Tutorial: Limpieza y visualizaciones para encontrar patrones con Python
el agosto 31, 2017 en Tutoriales
Desde Escuela de Datos, Sebastián Oliva, fellow 2017, enseña cómo usar la librería de Pandas para Python para importar distintas bases de datos. En este ejercicio conocemos qué es una base de datos relacional, de qué trata el lenguaje SQL, y en el terreno práctico, cómo hacer algunas visualizaciones en Python para hallar patrones interesantes.
Puedes seguir paso a paso viendo este video-tutorial, siguiendo el cuaderno que publicamos abajo o consultando el cuaderno de trabajo de Sebastián en este link.
Leer y escribir archivos, bases de datos y más
Al realizar una exploración de datos, estos pueden provenir de muchas fuentes, en algunos casos recursos en linea, bases de datos SQL o de otros tipos; en otros puede ser necesario exportar a algun formato para seguir el análisis en otra herramienta. Con las herramientas que ya conocemos (Python, Pandas, etc), es muy conveniente el poder utilizarlas para exportar e importar datos. Vamos a trabajar un poco con unas bases de datos sencillas que nos permitirán ejemplificar la facilidad y algunos posibles asuntos a la hora de manipular datos en distintas fuentas. Una de estas es una base de datos de estudios ambientales desde los inicios de los 90’s hasta el 2014, mientras otra son los centros educativos en Guatemala hasta el 2013Bases de datos: un Crash Course
Como hemos visto ya en estos tutoriales, Pandas es una libreria muy poderosa para manipular datos; sin embargo tiene también competencia obvia en sistemas de bases de datos, que dependiendo de su oferta ofrecen alguna de la funcionalidad de Pandas, junto con otra que es incomparable. Entre los conceptos fundamentales de bases de datos es reconocer la diferencia entre un DBMS (Database Management System) y una DB en sí. El DBMS es el software que permite acceder y controlar la base de datos; mientras que la DB son nuestros datos. Es comparable a la relación entre un reproductor multimedios y la música en sí, la diferencia mas notable es que practicamente no existe un estandar de bases de datos, mas allá de lo que provee SQL en si. Existe una variedad de modelos de bases de datos, para esta ocasión nos enfocaremos en el más común: SQL y bases de Datos RelacionalesRDBMS (Relational Database Management Systems)
SQL es un lenguaje que permite interactuar con bases de datos relacionales. El «Standard Query Language» es en la realidad, no tan estandar, sin embargo, hay un subconjunto que es compatible conocido como ANSI SQL y sus posteriores revisiones. Los ejemplos de este tutorial estarán en SQLite, una base de datos libre que ofrece alto rendimiento y poco uso de recursos, a contraparte de sus limitaciones como concurrencia limitada y el estar basada en archivos. La estaremos usando por su simplicidad, pero téoricamente podriamos usar casi cualquier otro DBMS. Algo muy notable y de tener en cuenta es que las Bases de datos Relacionales, como su nombre lo dice, están basadas en relaciones. Mucha gente confunde este concepto con el de llaves y uniones entre ellas, sin embargo es mucho mas profundo. En las bases de datos relacionales (y lo siento por si puede parecer un poco confuso): Las relaciones son agrupaciones de datos en las cuales se preserva su identidad, es decir representan algo, del cual queramos llevar registro; De estas agrupaciones, cada entidad o sea filas ó tuplas (que lleva su propia carga matemática), del mismo tipo se materializan en tablas, es decir las relaciones de bases de datos relacionales no se refieren a las relaciones que se pueden crear entre los datos, sinó a la estructura tabular en sí. Podemos tomar una pausa aquí y comenzar con el código. Es conveniente porque podremos ver varias de estas analogías en vivo.import pandas as pd
import numpy as np
import seaborn
import joypy
import matplotlib
matplotlib.rc("savefig", dpi=300)
%matplotlib notebook
import sqlite3
conexion_estudios_ambientales = sqlite3.connect("estudios_amb.sqlite3")
estudios = pd.read_sql("SELECT * FROM estudios_ambientales",
conexion_estudios_ambientales,
parse_dates=["Fecha_Captura","Fecha_Resolucion","Fecha_Notificacion","Fecha_Dictamen"])
estudios.head()
tiempos_espera=pd.concat(
{
"Periodo": estudios["Periodo"].map(int).astype(int),
"TiempoEspera": (estudios["Fecha_Captura"]-estudios["Fecha_Resolucion"]).map(lambda x: x.days)
},
axis=1
).dropna()
tiempos_espera
tiempos_espera.describe()
Ahora ya tenemos los elementos, cada uno de los registros y las fechas en las cuales fueron procesados. Podemos ver que el 50% esperó hasta 47 dias y el promedio es esperar 96 dias.
tiempos_espera.plot()
tiempos_espera[tiempos_espera["TiempoEspera"] > 0]
¿Con que esperaste cuánto?
+6926.000000 !!! Esto es un poco ridiculo. Pero este error está atado a la calidad del dato. Lo que podemos hacer es limpiarlo.tiempos_espera = tiempos_espera[tiempos_espera["Periodo"] < 2015]
tiempos_espera = tiempos_espera[tiempos_espera["TiempoEspera"] < 0] # Errores, probablemente año 1900? (IDK)
tiempos_espera = tiempos_espera[tiempos_espera["TiempoEspera"] > -10000] # Errores, probablemente año 1900? (IDK)
# print(tiempos_espera.Periodo.unique()) # Ver que años
tiempos_espera = tiempos_espera.set_index("Periodo")
tiempos_espera.describe()
# tiempos_espera.plot()
# verde_obscuro = seaborn.palplot(seaborn.cubehelix_palette(8, start=2, rot=0, dark=0, light=.95, reverse=True))
# %matplotlib inline
fig, axes = joypy.joyplot(tiempos_espera,
by="Periodo",
column="TiempoEspera",
fade=True,
#kind="normalized_counts",
hist=True,
bins=250,
grid=True,
range_style="own",
x_range=[-1255,100],
figsize=(4,8),
colormap=seaborn.cubehelix_palette(8, start=2, rot=0, dark=0, light=.95, reverse=True, as_cmap=True))
Algunos de los usos mas avanzados de esto te permiten hacer análisis de datos estructurados, como justamente un sistema informatico ya existente usualmente se compone de muchas tablas y relaciones, además de vinculos y estructuras entre ellas. Veamos un ejemplo con otra base de datos.
Usaremos una llamada Chinook, una base de datos de ejemplo que contiene datos de una tienda de discos, es un ejemplo un poco «empresarial» pero puede servirnos. Podemos ver el esquema de la base de datos aqui: 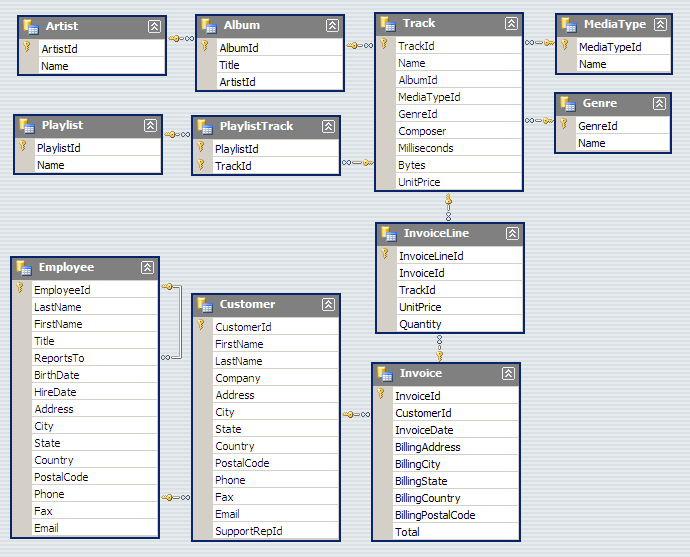
chinook_connection = sqlite3.connect("Chinook_Sqlite.sqlite")
chinook_dataframe = pd.read_sql("""Select *
FROM Track
LEFT OUTER JOIN MediaType ON MediaType.MediaTypeId = Track.MediaTypeId
LEFT OUTER JOIN Genre ON Genre.GenreId =Track.GenreId
LEFT OUTER JOIN Album ON Album.AlbumId = Track.AlbumId
LEFT OUTER JOIN Artist ON Artist.ArtistId = Album.ArtistId""", chinook_connection)
chinook_dataframe
chinook_connection = sqlite3.connect("Chinook_Sqlite.sqlite")
#artista_genero = pd.read_sql("""Select Genre.Name, Artist.Name
#FROM Track
#LEFT OUTER JOIN Genre ON Genre.GenreId = Track.GenreId
#LEFT OUTER JOIN Track ON Track.AlbumId = Album.AlbumId
#LEFT OUTER JOIN Artist ON Artist.ArtistId = Album.ArtistId """, chinook_connection)
#artista_genero
chinook_dataframe.to_csv()
Fwomp! necesitamos guardar esto en un archivo.
tiempos_espera.to_excel("miarchivo.xls")
Podemos ver mas de la interoperabilidad de estas plataformas en la documentación de Pandas y SQL y en general aprender más de SQL en una variedad de recursos en linea.
Ahora probemos a extraer información.
%time centros_educativos = pd.read_excel("14102014 - MINEDUC - CENTROS EDUCATIVOS REPUBLICA DE GUATEMALA.xlsx")
centros_educativos
# print(centros_educativos["AREA"].value_counts())
centros_educativos = centros_educativos[centros_educativos.AREA != "SIN ESPECIFICAR"]
print(centros_educativos["AREA"].value_counts())
for col in ["DISTRITO", "DEPARTAMENTO", "MUNICIPIO", "NIVEL","SECTOR","AREA","STATUS","MODALIDAD","JORNADA","PLAN"]:
centros_educativos[col] = centros_educativos[col].astype('category')
#centros_educativos.groupby(["JORNADA","PLAN","AREA"],).count()
centros_educativos.groupby(["JORNADA","PLAN","AREA"]).count()["CODIGO"]
seaborn.factorplot(
y="PLAN",
col="AREA",
hue="JORNADA",
row="NIVEL",
data=centros_educativos,
kind="count", size=4);
#seaborn.tsplot(centros_educativos.groupby(["JORNADA","PLAN","AREA"]).count()["CODIGO"])
# escuelas_heatmap_pivot = centros_educativos.pivot("PLAN", "AREA", "JORNADA")
escuelas_heatmap = centros_educativos.pivot("PLAN", "AREA", "JORNADA")
# Draw a heatmap with the numeric values in each cell
f, ax = plt.subplots(figsize=(9, 6))
sns.heatmap(escuelas_heatmap, annot=True, fmt="d", linewidths=.5, ax=ax,
y="PLAN", col="AREA", hue="JORNADA", row="NIVEL", data=centros_educativos)
Deja un comentario