- No se requiere código solo conectar los datos con las librerías de plantillas con las que cuenta
- Flexibilidad hacia arriba al permitirle a algunos usuarios poder crear plantillas privadas y a la medida
- Storytelling animado para poder guiar a las audiencias a través de datos. Explicándolos ya sea a través de la publicación o a medida que interactúan.
- Embeds y descargas ya que los proyectos se pueden incrustar en cualquier página, pero también se pueden descargar como archivos crudos o raw para otros usos.

¿Qué plantilla escoger?
De momento, Flourish se encuentra en una fase beta en la que ofrece 17 plantillas que te mostramos y comentamos.
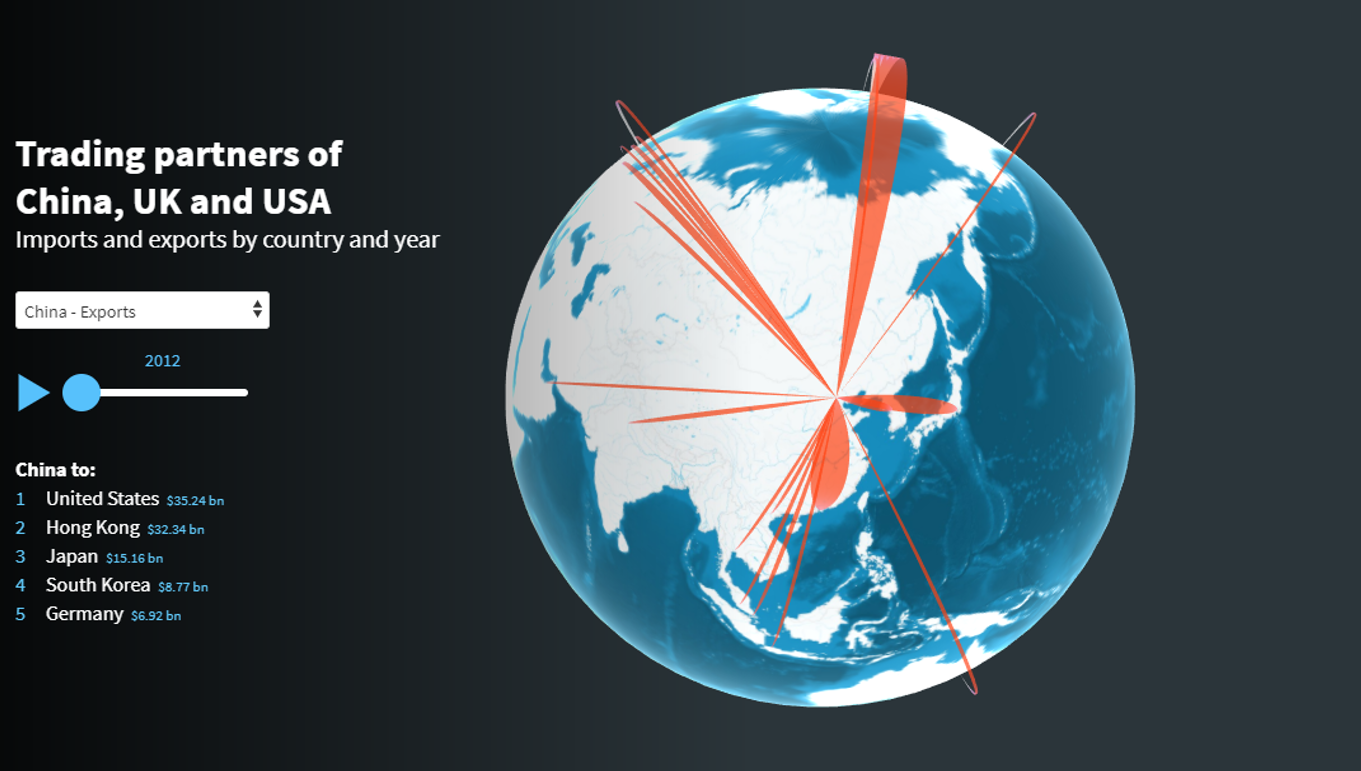
Globo terráqueo de conexiones
Esta plantilla tridimensional es ideal para visualizar un flujo de datos como patrones de migración, transferencias monetarias o vuelos. Cada fila en el conjunto de datos es representada como un arco entre dos locaciones, el cual tiene un tamaño escalable dependiendo del flujo.
Para usar esta plantilla necesitas tener las siguientes columnas: locación de origen, locación de destino y valor. Lo mejor es que los orígenes y destinos estén acompañados de la codificación de países ISO Alpha-3 (códigos de tres letras). Sino, puedes especificar latitud, longitud y un nombre para desplegar.
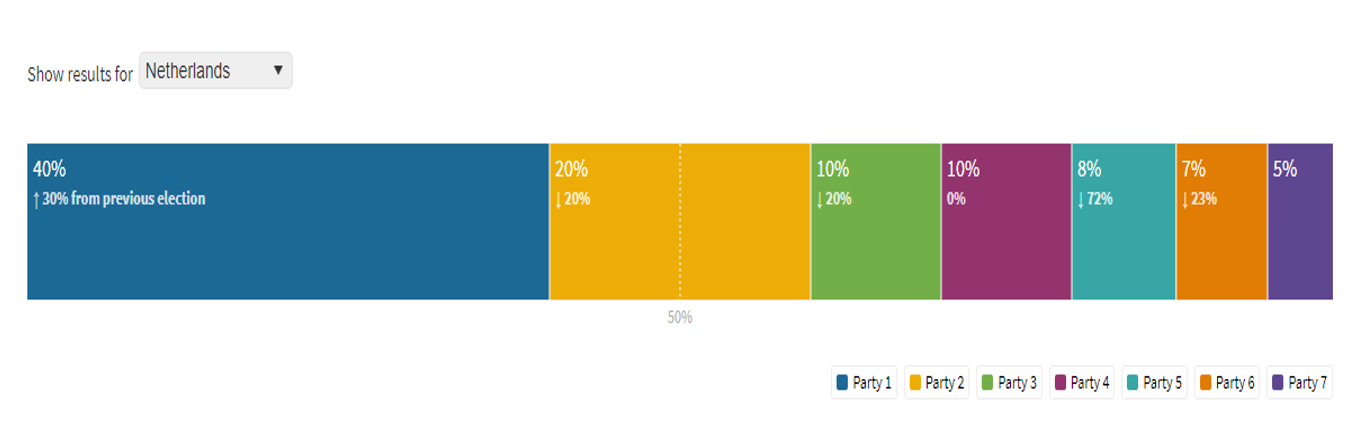
Barra apilada para resultados electorales
Un gráfico de barras apiladas (stacked bar) ideal para resultados electorales. Con él puedes mostrar un resultado general, o especificar por regiones que pueden ser seleccionadas de un menú dropdown. Incluye una funcionalidad que permite construir coaliciones, alternando los partidos en las leyendas para personalizarlas y también la opción de agregar datos históricos para comparar los resultados actuales con la elección anterior.
Para usar esta plantilla cada fila debería ser una región (país, estado, departamento o municipio). Esa región debería tener una columna con su nombre y una columna por cada partido en la elección.
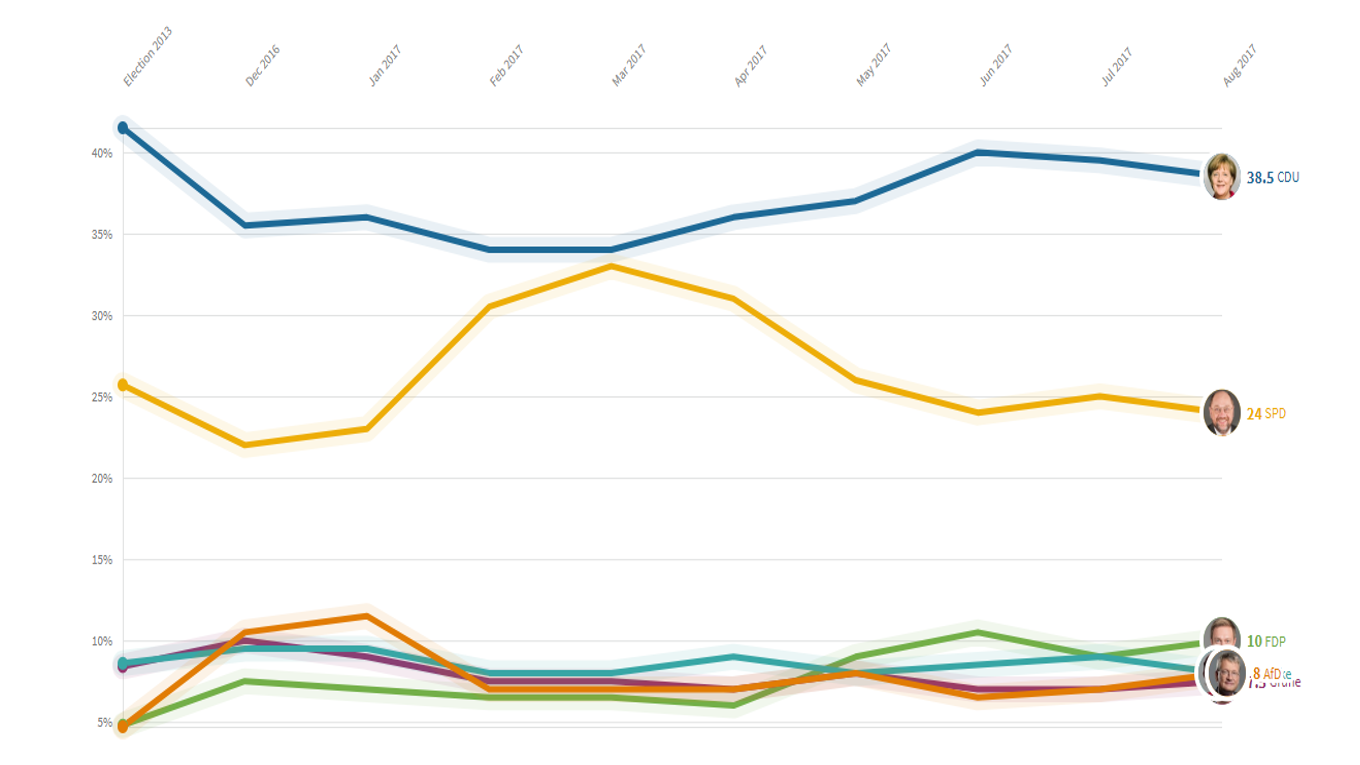
Carrera de caballos
Este tipo de gráfico muestra el cambio de un rango o su evolución en cierto tiempo. Esta visualización es muy utilizada para mostrar los datos de cualquier tipo de competencia o «carrera»: candidatos en unas elecciones, equipos de futbol en una competencia, por ejemplo. Grafica en dos modalidades y permite animaciones entre ambas: un gráfico lineal que traza los valores en bruto y un gráfico de evolución que calcula y traza los rangos de estos datos.
Para usar esta plantilla cada fila después de los encabezados debe corresponder a un participante de la carrera. En las columnas se señalará: nombre del participante y cuantas columnas sean necesarias para cada «etapa» de la carrera (semanas, días, años, montos, etc). Todas las etapas se grafican con el mismo ancho.
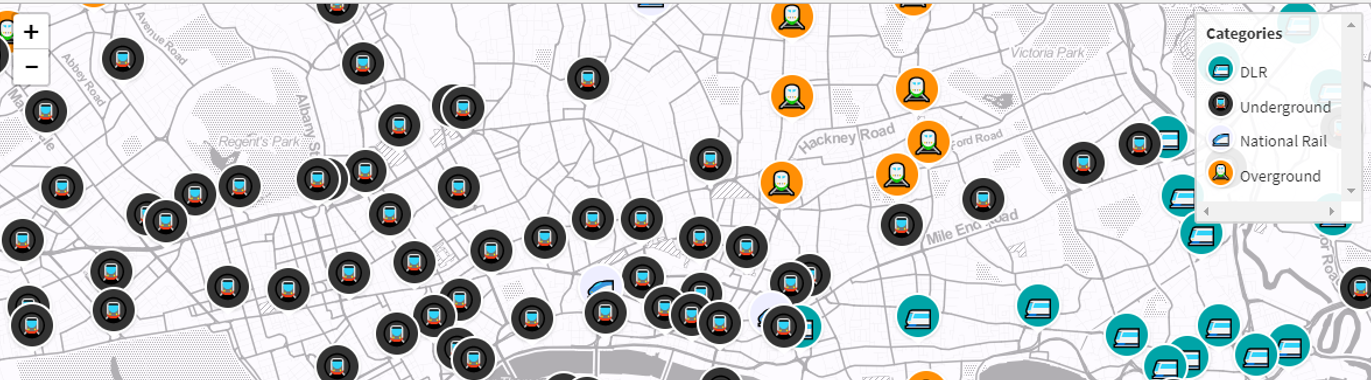
Mapa de íconos
En este mapa interactivo usas iconos, imágenes o emojis para marcar un lugar. La plantilla crea una calve que se duplica para que los usuarios puedan hacer click tanto a una categoría o a un ícono.
Para usar esta plantilla necesitas una hoja de cálculo con una fila para cada elemento en el mapa y sus respectivas latitud y longitud. Para agregar íconos debes tener una columna como categoría.
Gráficos de lineas, barras y pie o pastel
Elige entre un gráfico de líneas, uno de barras (incluso si son agrupadas o apiladas), de área o de pie. Para utilizar esta plantilla necesitas una columna con «etiquetas» (que pueden ser categorías, fechas, números, etc) y una o más columnas con «valores» (que debe contener números). Cada columna de valores crea una línea, barra o pedazo de pie, por lo que agrega cuantas requieras. Para seleccionar entre las opciones solo intercambia entre las opciones en «chart type«.
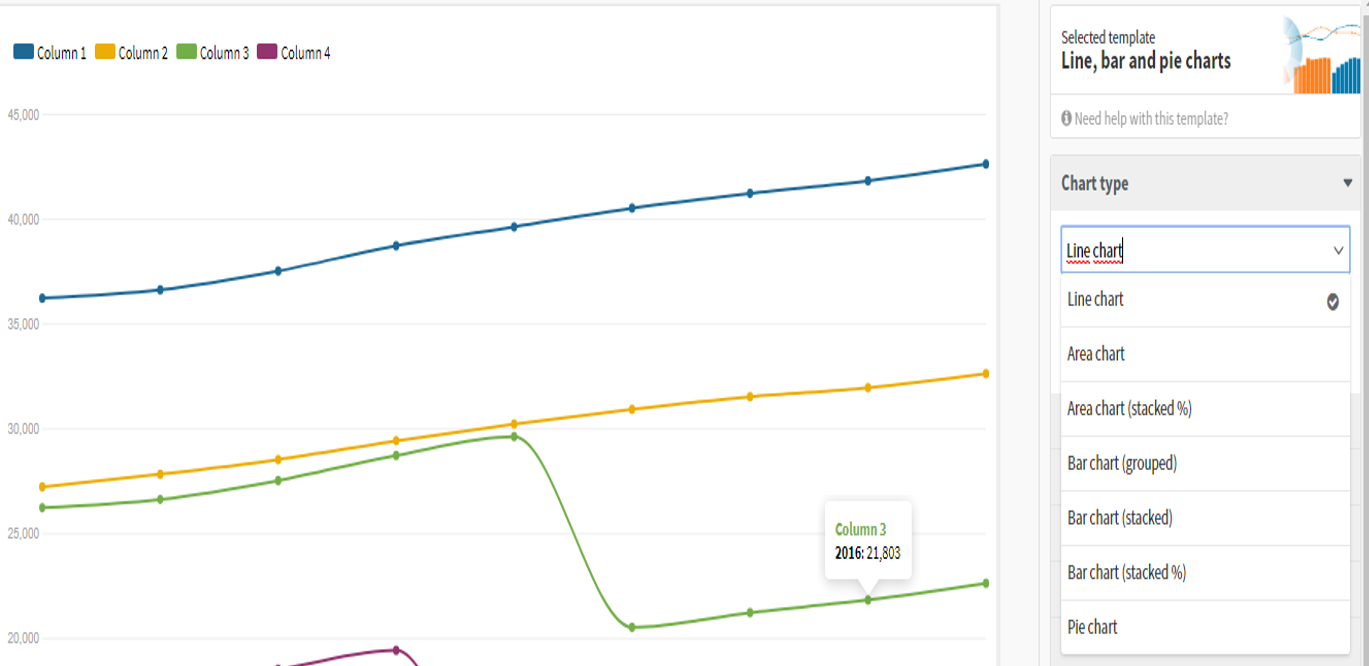
Mapamundi
Un mapa del mundo con opciones para colorearlo en escala, señalarlo con puntos y ventanas emergentes. Para graficar usa un conjunto de datos para los colores y otro para los círculos en coordinadas específicas.
Para utilizar este gráfico tus datos deberían contener una columna con nombres de región y una o más columna con valores. Los nombres de las regiones deberían coincidir con los datos de ejemplo precargados.
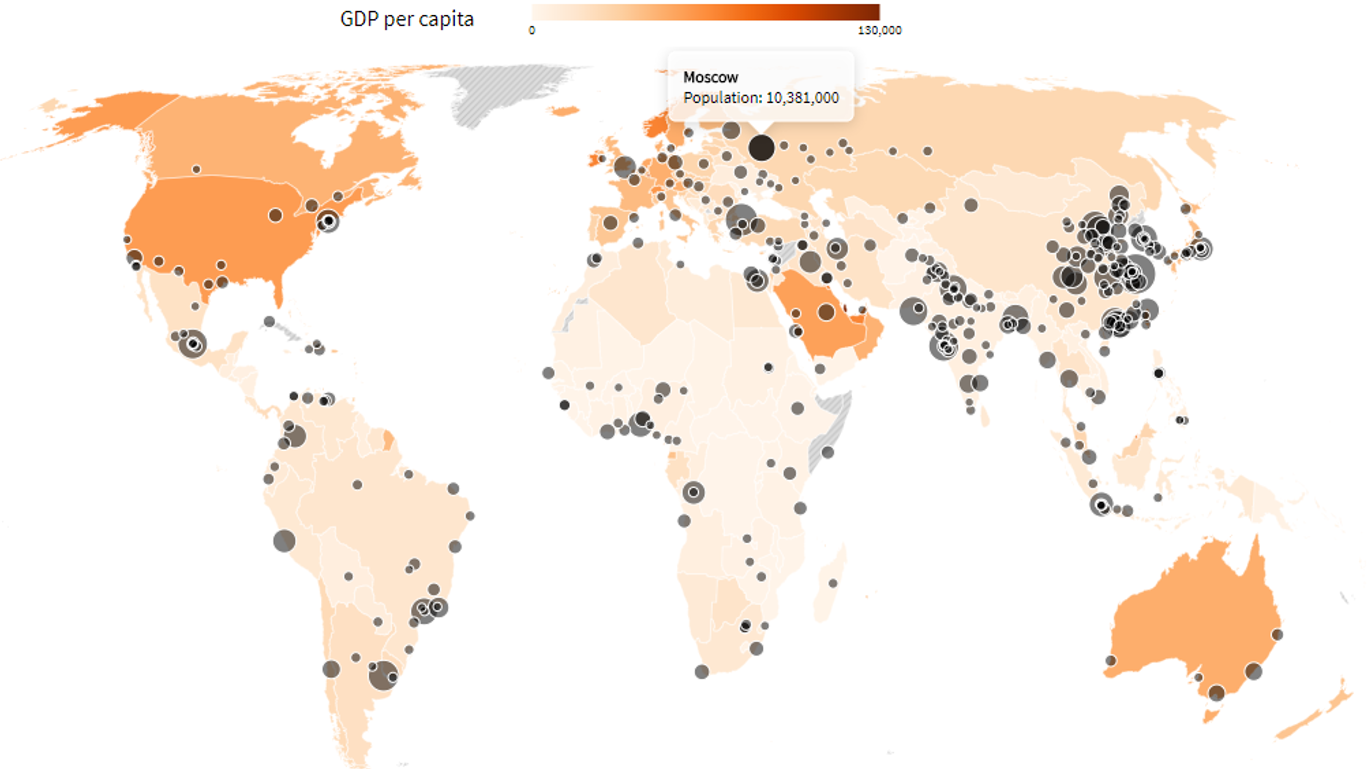
Gráfico de redes
Una red de puntos vinculados como un diagrama de nodos. Para lograr esta unión, el conjunto de datos debe de tener al menos dos columnas con los vínculos. Cada fila especifica los puntos (que se mostrarán como círculos) que se vinculan entre sí (a través de una línea). Se puede incluir una tercera columna que se use para definir el ancho del vínculo.
Si bien una hoja de cálculo es suficiente para crear un diagrama de red, una segunda hoja de «Puntos» permite una mayor flexibilidad. En lugar de dejar que Flourish determine todos los puntos para agregar a la red en función de los enumerados en la hoja Vínculos, las filas en la hoja Puntos definen la colección completa de puntos y se puede usar para asignar color a grupos codificados o tamaño a los puntos.

Capacidades y límites
Como muchos programas gratuitos, Flourish funciona bajo un esquema freemium. La versión gratis te permite publicar y compartir visualizaciones o incrustarlas en tu website. Estos trabajos permanecen públicos y cualquiera puede acceder a ellos, lo cual es bueno para comunicadores y medios, pero no tanto para organizaciones que lidian con información sensible. Existen versiones de pago personales y para empresas que te permiten descargar el código HTML y hospedarlo en tu propio servidor.
Con todas las versiones de Flourish puedes descargar un archivo .SVG que luego puedes abrir y editar en programas como Adobe Illustrator. Esto hace que Flourish sea una herramienta útil también para aquellos que trabajan en medios impresos y hacen infografías.
Flourish tiene también un programa para que organizaciones periodísticas tengan una cuenta premium de manera gratuita que les permita trabajos privados, plantillas personalizadas y proyectos compartidos. Si formas parte de un medio puedes aplicar a través de este formulario al programa.
Como siempre, queremos saber si te resultó útil nuestro tutorial y nos encantaría ver qué visualizaciones creas con Flourish. Escríbenos por twitter a @EscuelaDeDatos
![]()
¿Te has encontrado con bases de datos que tienen pequeños errores de transcripción? ¿Espacios de más, uso desordenado de mayúsculas y minúsculas, o registros que representan al mismo dato pero que fueron escritos con pequeñas diferencias? Con la herramienta OpenRefine puedes automatizar mucho del doloroso proceso de limpiar una base de datos. En este tutorial te enseñaremos una de sus funciones más útiles: la clusterización —o generación de agrupaciones automáticas— y los diferentes algoritmos que determinan las coincidencias entre registros.
El concepto de clusters (o agrupaciones, en español) se utiliza mucho en ciencias sociales y exactas para referirse a un tipo de análisis que toma un conjunto de datos y las reorganiza en grupos con características similares.
En OpenRefine, cuando uno hace clusters significa que el programa está encontrando grupos de valores diferentes que pueden ser representaciones alternativas del mismo valor. Por ejemplo, si hablamos de ciudades, “New York”, “new york” y “Nueva York” son tres valores diferentes pero que se refieren al mismo concepto, sólo con cambios de idioma y de uso de mayúsculas y minúsculas.
Vale la pena mencionar que las agrupaciones en OpenRefine sólo se generan automáticamente en la sintaxis (o sea, el orden y la composición de caracteres que tiene como valor una celda) y aunque estos métodos son útiles para encontrar errores e inconsistencias, no son lo suficientemente avanzados para determinar agrupaciones a nivel semántico (o sea, el significado de un valor).
Estos métodos se pueden aplicar determinando cuántos grados de cercanía -en otras palabras, qué tan estrechas o flojas quieres encontrar las coincidencias-. Al graduar la cercanía encuentras coincidencias más o menos exactas. Por eso es importante que si bien, los algoritmos ayudan a automatizar la tarea de limpieza, un ojo y cerebro humano va administrando qué tan agresivas deben ser estas uniones para encontrar coincidencias, para evitar que asocie datos que no deberían ir juntos.
Conozcamos los algoritmos: En qué consisten estas metodologías
Existen dos grandes metodologías para hacer clusters: la colisión clave y el vecino más cercano. Open Refine utiliza diferentes variantes de estos dos métodos. Aquí te explicamos cuál es el proceso detrás de cada uno.
Sección 1: Métodos de colisión clave
Estos se basan en la idea de crear una representación alternativa de un valor inicial, el cual se convierte en una clave. Una clave contiene las partes más distintivas y significativas de un valor. OpenRefine va buscando en los demás registros qué otros valores se parecen a esta clave para agruparlos. El procesamiento requerido para este método no es muy complejo, por lo que presenta resultados muy rápidos. Este método tiene varias funciones diferentes que se pueden administrar en OpenRefine.
- Fingerprint
Un método fácil y simple. Quita todos los espacios en blanco, cambia todos los caracteres a minúsculas, remueve toda la puntuación y normaliza cualquier caracter especial a una versión estándar. Luego, parte el texto y aplica espacios en blanco. Así encuentra las coincidencias.
- N-Gram Fingerprint
Es similar al anterior, pero en vez de separar los caracteres por espacios en blanco, usa una cantidad a la enésima (n) potencia de espacios que el usuario puede determinar.
- Fingerprint Fonético
Este método no revisa los caracteres textuales sino su pronunciación y fonética: la manera en que esa palabra se pronunciaría, en vez de revisar similitudes en la escritura. Es muy útil para limpiar datos con nombres particulares, ya sea de lugares y personas. En ocasiones, los errores de registro se deben a que se registran a partir de la pronunciación. Sirve para encontrar similitudes entre sonidos parecidos pero que se escriben muy distinto como el sonido de “sh” y “x”, que en ocasiones son similares.
Sección 2: Vecino más cercano (Nearest neighbor)
Estos métodos proveen un parámetro o radio de aproximación alrededor de un valor o palabra, y va encontrando los grados de similitud entre éste y otros registros. Debido a los cálculos necesarios, estos métodos son más tardados en procesar.
- Distancia Levenshtein
Este método se basa en el trabajo y proceso que implicaría cambiar a un registro A para que sea igual a un registro B. La distancia Levenshtein mide cuántas operaciones de edición -o cuántos pasos- le tomaría a alguien hacer que un dato se parezca al otro. Encuentra coincidencias entre los datos que están separados por la menor cantidad de pasos o cambios.
Por ejemplo, “Paris” y “paris” tienen una distancia de edición de 1, ya que solo se debe cambiar la P mayúscula a una minúscula. Sin embargo, “Nueva York” y “nuevayork” tienen una distancia de 3 pasos: dos sustituciones y un borrón.
- PPM (Prediction by Partial Matching)
Este método se utiliza para encontrar coincidencias en secuencias de ADN. Estima la similitud entre textos y determina su contenido idéntico. Por ejemplo, con el ADN encuentra similitud entre dos muestras para indicar un grado de familiaridad. Es común en este campo que no se busque una coincidencia exacta (que implicaría trabajar con muestras de ADN de la misma persona) sino encontrar un alto grado de coincidencia y familiaridad.
Si dos cadenas A y B son idénticas, al concatenar A+B debería de producirse muy poca diferencia. Pero si A y B son diferentes, al concatenar A+B se deberían producir diferencias muy dramáticas en la longitud de la cadena.
Paso a paso. Aplicando los clusters en OpenRefine
 OpenRefine es un programa que corre a través de tu browser o navegador de internet. Para instalarlo, es necesario que lo descargues en este link y sigas las instrucciones para tu equipo. Usualmente, solo requiere que descargues la carpeta, la descomprimas y abras la aplicación.
OpenRefine es un programa que corre a través de tu browser o navegador de internet. Para instalarlo, es necesario que lo descargues en este link y sigas las instrucciones para tu equipo. Usualmente, solo requiere que descargues la carpeta, la descomprimas y abras la aplicación.
OpenRefine debería abrir una ventana negra con algunos códigos y abrirse automáticamente en tu navegador de internet. Si no funciona, prueba ir a la dirección http://127.0.0.1:3333/
Vamos a hacer un ejemplo con un conjunto de datos sobre financistas a las elecciones del 2017-2018 en Estados Unidos que puedes descargar aquí.
Para subir el archivo, solo sigue los siguientes pasos:
Create project > Elegir archivo (selecciona el archivo ZIP que descargaste) > Next
OpenRefine te mostrará una previsualización de tu conjunto de datos. En este caso, deberás desmarcar la opción >Parse Next para indicar que tu base de datos no tiene títulos de columna en la primera fila.
En >Project Name, escribe “Financiamiento político_Estados Unidos 2017-2018” y da click a >Create project para guardar este proyecto.
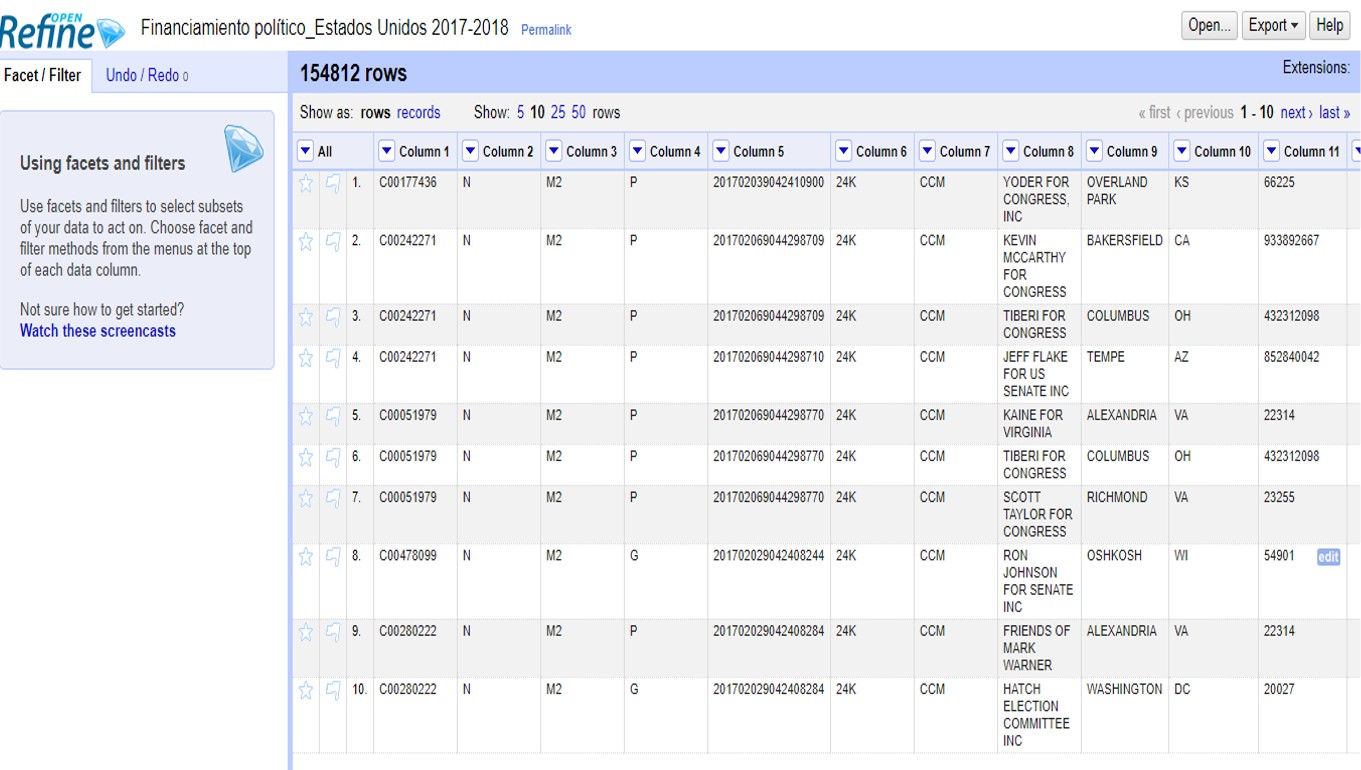
En la columna 8 encontrarás el listado de financistas. Haciendo click en el triángulo a la par del título de esta columna, selecciona >Facet >Text facet para generar un filtro de texto.
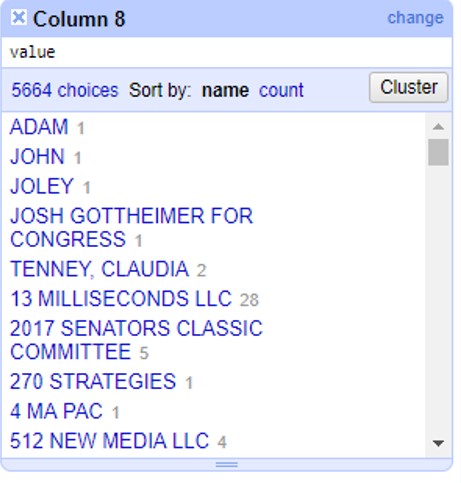
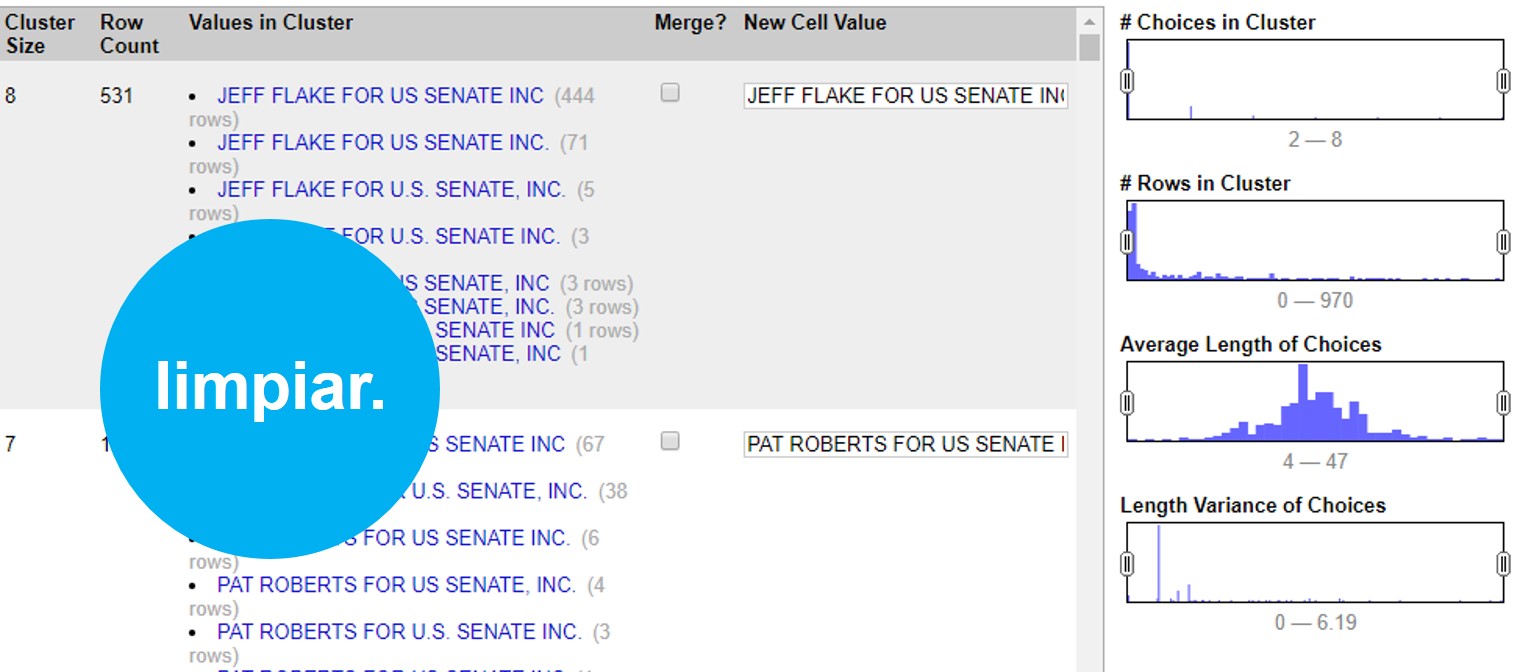
A un lado, te aparecerán todos los registros de financistas en orden alfabético, con un número a la par que indica cuántas veces aparece este nombre en la base de datos. Haz click en el botón >Cluster para empezar a generar agrupaciones automáticas.
En la siguiente ventana puedes aplicar todos los métodos de clusters que te enseñamos. Puedes administrarlo cambiando las opciones >Method, >Keying Function o >Distance Function.
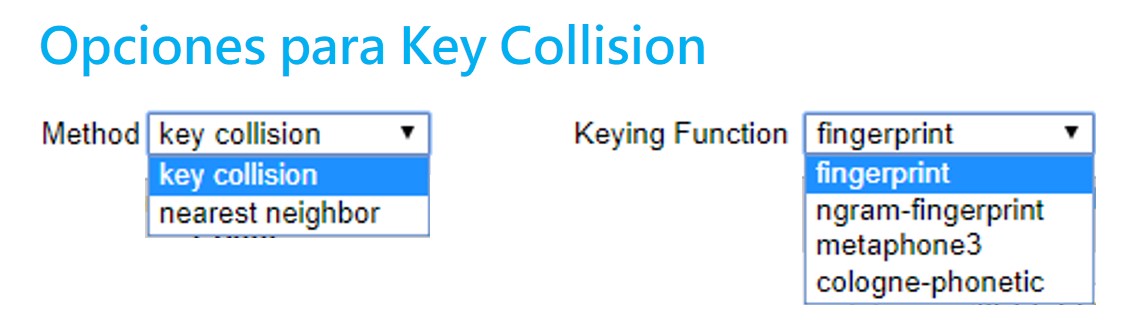

Con estos controles podrás ir determinando qué tan agresivos son tus clusters. Independientemente del método que eligas, el proceso es el mismo. Al seleccionar el método y sus opciones, OpenRefine comenzará a procesar los datos para encontrar coincidencias y armarlas en un cluster o agrupación.
En este ejemplo podemos ver que el programa encontró 531 valores muy similares, escritos de 8 maneras diferentes para decir lo mismo: que un financista se llama “JEFF FLAKE FOR U.S SENATE, INC”. Como puedes ver, a la par de cada manera de escribir, OpenRefine te muestra cuántas veces aparece de esta manera el valor.
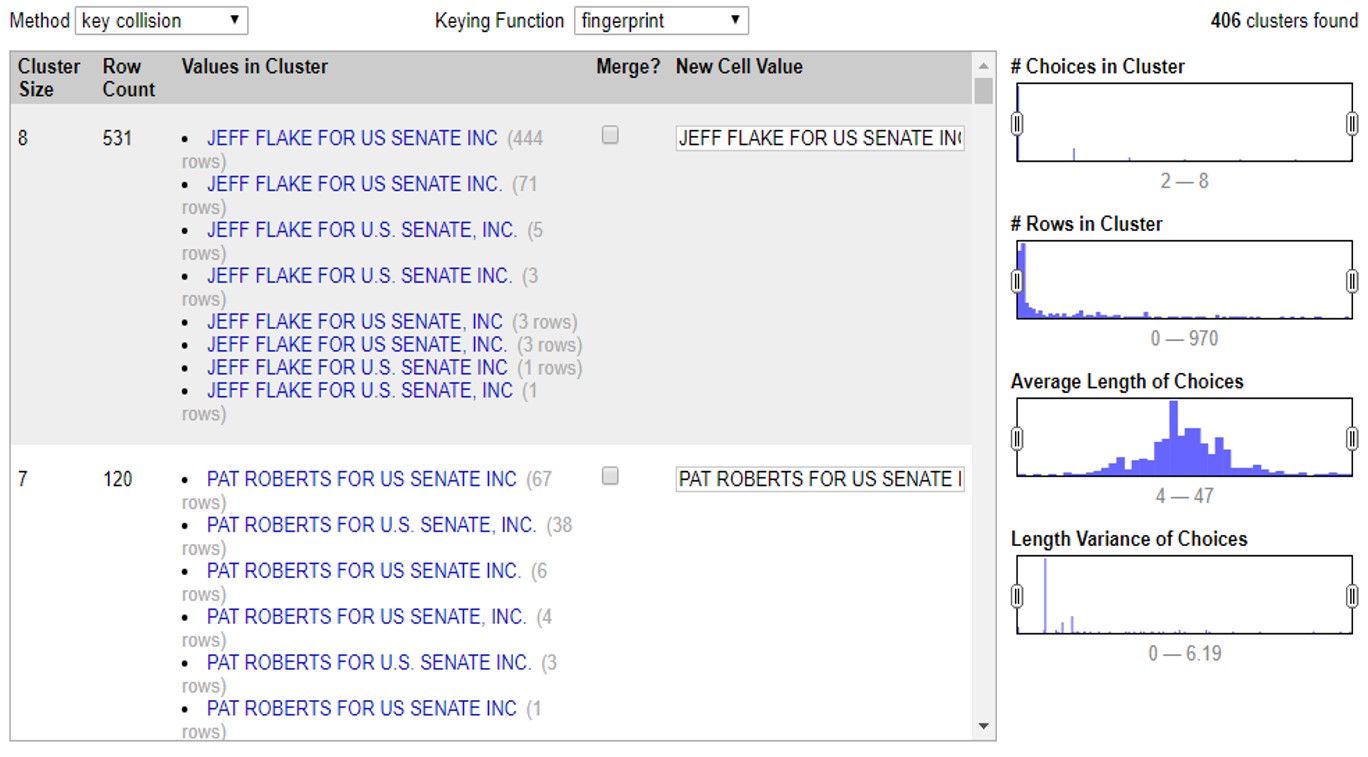
En este caso te muestra dos opciones. La primera, >Merge incluye una casilla que puedes seleccionar en caso de que sí quieras que OpenRefine una estos valores. En la segunda opción >New Cell Value, el programa te da la oportunidad de que edites y decidas de qué manera quieres que se reescriba este cluster. Así, irás administrando la agrupación valor por valor, decidiendo si quieres o no agrupar los valores con >Merge y la opción de escritura bajo la cual estos valores se agruparán con >New Cell Value
Con este ejemplo, si aceptas todas las agrupaciones de cluster que te permite el método >Key Collision >Fingerprint verás como la columna de financistas pasó de tener 5,664 opciones diferentes, a tener 5,136 registros diferentes. 528 valores menos que eran repetidos pero contenían errores gramaticales o de sintaxis que hacían que la computadora no los tomara como iguales.
Así, en estos sencillos pasos, OpenRefine editó los valores de 54,807 celdas que manualmente tomarían demasiado tiempo para limpiar y estandarizar.
Para finalizar, haz click en >Export para descargar tu base de datos limpia en el formato que prefieras.Ya sea valores separados por coma, o por tabulaciones; formato para Excel o HTML, OpenRefine te permite escoger entre diversos formatos para descargar la versión limpia de tu base de datos.
Cuéntanos en qué casos puedes utilizar los clusters y OpenRefine para limpiar tus datos. Escríbenos a [email protected] o por twitter @escueladedatos y estaremos compartiendo algunos ejemplos de usos de esta herramienta.
![]()
Desde Escuela de Datos, Sebastián Oliva, fellow 2017, enseña cómo usar Python para generar mapas a partir de datos georreferenciados.
Mapas y Python
Es obvia la importancia de los mapas, para la visualizacion de datos. Las coordenadas, latitud y longitud, pueden describir un punto sobre la tierra. Utilizamos estandares como WGS-84 para atar esas coordenadas a un punto real.
Utilizando MatPlotlib, podemos aprovechar Basemap, una libreria que provee funcionalidad básica de mapa, con la cual podemos construir y componer. Agregar poligonos, puntos, areas, barras, colores, etc; se hace mediante estas librerias.
Librerias
La libreria mas utilizada en el ecosistema Jupyter-Matplotlib es Basemap. Tambien existen otras, entre ellas, Plotly, que son muy poderosas y convenientes pero tienen dependencias externas.
- Basemap: el «industry standard». Un poco complicado para el setup, bastante poderoso e integrado con matplotlib.
- Plotly: Una libreria que permite desplegar datos mediante Javascript en la Web
- QGis: Una aplicación completa para el manejo de datos GIS, tiene bindings en Python y es posible utilizar como libreria para aplicaciónes tanto GUI como en notebooks o para analizar en scripts y exportar.
- OSMnx: Basada en Open Street Map, Permite tanto analisis como visualización de mapas a nivel de calle, region, ciudad y más.
Para este webinar, vamos a indagar mas en Basemap, que es el mas accesible.
Basemap
Basemap es una extensión de la funcionalidad disponible
Existen varias formas de instalarlo, así que puede ser un poco confuso. Dependiendo de el método en el cual tengas instalado matplotlib hace variar la forma apropiada de instalarlo.
Ambiente de Trabajo
$ #ESTE_ENV = midevenviroment $ source ~/miniconda3/envs/$ESTE_ENV/bin/activate $ conda install jupyter-notebook $ conda install gdal -c conda-forge $ conda install basemap -c conda-forge $ conda install pandas seaborn ## En caso hayan instalado basemap en algun directorio no standard: utiliza un link para la carpeta data. $ ln -s /home/tian/miniconda3/pkgs/basemap-1.1.0-py36_2/lib/python3.6/site-packages/mpl_toolkits/basemap/data/ /usr/share/basemap
In [16]:
# Importamos lo ya usual. import matplotlib.pyplot as plt import matplotlib.cm import pandas as pd import numpy as np import seaborn # Algunas librerias extra que usaremos from matplotlib.colors import Normalize import matplotlib.colors as colors from numpy import array from numpy import max # Aqui cargamos Basemap from mpl_toolkits.basemap import Basemap from matplotlib.patches import Polygon from matplotlib.collections import PatchCollection sns.set(style="white", color_codes=True) %matplotlib inline
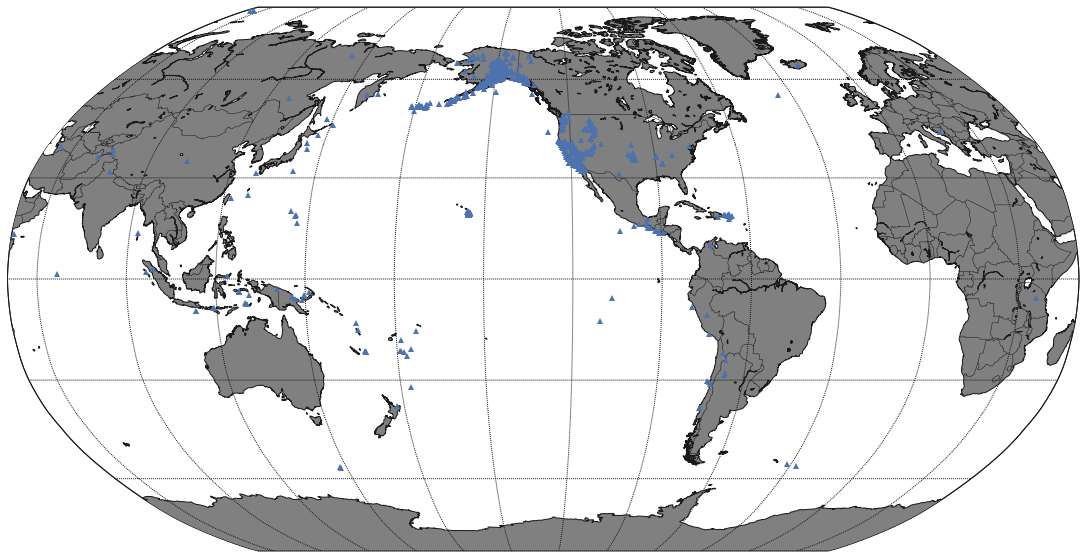
Mapeando los terremotos globales de la ultima semana
Vamos a usar la feed de datos del US Geological, ellas tienen disponibles datos referenciados de actividad geologica a nivel mundial, regional y de EEUU.
In [17]:
quakes = pd.read_csv("http://earthquake.usgs.gov/earthquakes/feed/v1.0/summary/1.0_week.csv")
# Creamos la lista de latitudes y longitudes.
lats, lons = list(quakes['latitude']), list(quakes['longitude'])
In [60]:
mags = list(quakes['mag']) quakes.head()
Out[60]:
| time | latitude | longitude | depth | mag | magType | nst | gap | dmin | rms | … | updated | place | type | horizontalError | depthError | magError | magNst | status | locationSource | magSource | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2017-10-31T16:29:08.330Z | 36.746834 | -121.467163 | 9.00 | 2.78 | md | 56.0 | 61.0 | 0.02078 | 0.15 | … | 2017-10-31T16:32:56.802Z | 11km SW of Ridgemark, California | earthquake | 0.24 | 0.45 | 0.16 | 66.0 | automatic | nc | nc |
| 1 | 2017-10-31T16:23:50.380Z | 19.839001 | -155.555664 | 23.85 | 2.06 | md | 44.0 | 110.0 | 0.08413 | 0.13 | … | 2017-10-31T16:27:14.110Z | 23km SSE of Waimea, Hawaii | earthquake | 0.61 | 0.81 | 0.19 | 8.0 | automatic | hv | hv |
| 2 | 2017-10-31T16:15:45.210Z | 37.603668 | -118.955666 | 1.43 | 1.08 | md | 8.0 | 198.0 | 0.01381 | 0.02 | … | 2017-10-31T16:25:02.360Z | 5km SSE of Mammoth Lakes, California | earthquake | 1.38 | 1.29 | 0.17 | 6.0 | automatic | nc | nc |
| 3 | 2017-10-31T16:14:54.100Z | 37.598167 | -118.954330 | 1.40 | 1.43 | md | 21.0 | 150.0 | 0.01940 | 0.03 | … | 2017-10-31T16:23:02.354Z | 5km SSE of Mammoth Lakes, California | earthquake | 0.34 | 0.70 | 0.26 | 19.0 | automatic | nc | nc |
| 4 | 2017-10-31T15:54:17.460Z | 19.265667 | -155.392166 | 3.49 | 2.34 | ml | 47.0 | 106.0 | 0.02847 | 0.21 | … | 2017-10-31T16:00:00.580Z | 11km NE of Pahala, Hawaii | earthquake | 0.37 | 1.25 | 0.32 | 8.0 | automatic | hv | hv |
5 rows × 22 columns
Iniciemos con el mapa
In [25]:
eq_map = Basemap(projection='robin', resolution = 'l', area_thresh = 1000.0,
lat_0=0, lon_0=-130)
eq_map.drawcoastlines()
eq_map.drawcountries()
eq_map.fillcontinents(color = 'gray')
eq_map.drawmapboundary()
plt.show()
/usr/lib64/python3.6/site-packages/mpl_toolkits/basemap/__init__.py:1631: MatplotlibDeprecationWarning: The get_axis_bgcolor function was deprecated in version 2.0. Use get_facecolor instead.
fill_color = ax.get_axis_bgcolor()
/usr/lib64/python3.6/site-packages/mpl_toolkits/basemap/__init__.py:1775: MatplotlibDeprecationWarning: The get_axis_bgcolor function was deprecated in version 2.0. Use get_facecolor instead.
axisbgc = ax.get_axis_bgcolor()
In [64]:
figu, ax = plt.subplots(figsize=(20,10))
eq_map = Basemap(projection='robin', resolution = 'l', area_thresh = 1000.0,
lat_0=0, lon_0=-130)
eq_map.drawcoastlines()
eq_map.drawcountries()
eq_map.fillcontinents(color = 'gray')
eq_map.drawmapboundary()
eq_map.drawmeridians(np.arange(0, 360, 30))
eq_map.drawparallels(np.arange(-90, 90, 30))
## Coordenadas a posiciones
x,y = eq_map(lons, lats)
eq_map.plot(x, y, '^', markersize=6)
plt.show()
/usr/lib64/python3.6/site-packages/mpl_toolkits/basemap/__init__.py:1631: MatplotlibDeprecationWarning: The get_axis_bgcolor function was deprecated in version 2.0. Use get_facecolor instead.
fill_color = ax.get_axis_bgcolor()
/usr/lib64/python3.6/site-packages/mpl_toolkits/basemap/__init__.py:1775: MatplotlibDeprecationWarning: The get_axis_bgcolor function was deprecated in version 2.0. Use get_facecolor instead.
axisbgc = ax.get_axis_bgcolor()
/usr/lib64/python3.6/site-packages/mpl_toolkits/basemap/__init__.py:3298: MatplotlibDeprecationWarning: The ishold function was deprecated in version 2.0.
b = ax.ishold()
/usr/lib64/python3.6/site-packages/mpl_toolkits/basemap/__init__.py:3307: MatplotlibDeprecationWarning: axes.hold is deprecated.
See the API Changes document (http://matplotlib.org/api/api_changes.html)
for more details.
ax.hold(b)
In [33]:
x[0]
Out[33]:
17740352.000926033
Veamos esto mas a detalle.
In [28]:
df = pd.read_csv('hiv_cr_data.csv')
df.columns
df.shape # (71, 8)
df.describe()
df.columns
df.loc[df.coordenadas == df.coordenadas]
subset = df.loc[df.coordenadas == df.coordenadas]
coordenadas = subset[['sitio','latitud', 'longitud', 'coordenadas']]
coordenadas.head()
Out[28]:
| sitio | latitud | longitud | coordenadas | |
|---|---|---|---|---|
| 0 | Esquina Sureste de la Iglesia del Corazón de J… | 10.018010 | -84.216480 | (10.01801 , -84.21648) |
| 1 | Parque Central de Alajuela | 10.016787 | -84.213914 | (10.016787 , -84.213914) |
| 2 | Parque de las Palmas, costado sur del hospital… | 10.020168 | -84.214064 | (10.020168 , -84.214064) |
| 3 | Mall Internacional | 10.006020 | -84.212740 | (10.00602 , -84.21274) |
| 4 | Ojo de Agua | 9.985120 | -84.195540 | (9.98512 , -84.19554) |
In [66]:
coordenadas.count()
Out[66]:
sitio 67 latitud 67 longitud 67 coordenadas 67 dtype: int64
In [67]:
coordenadas.coordenadas.head()
Out[67]:
0 (10.01801 , -84.21648) 1 (10.016787 , -84.213914) 2 (10.020168 , -84.214064) 3 (10.00602 , -84.21274) 4 (9.98512 , -84.19554) Name: coordenadas, dtype: object
In [35]:
(10.01801 , -84.21648)
Out[35]:
(10.01801, -84.21648)
In [30]:
fig, ax = plt.subplots(figsize=(10,20))
mapa = Basemap(projection='merc',
lat_0 = 9.74, lon_0 = -83.5,
resolution = 'i',
llcrnrlon=-88.1, llcrnrlat=5.5,
urcrnrlon=-80.1, urcrnrlat=11.8)
mapa.drawmapboundary(fill_color='#479EE0')
mapa.drawcoastlines()
from ast import literal_eval as make_tuple
def unpac(t):
# haciendo trampa en la vida
return pd.Series(make_tuple(t))
def plot_area(pos):
ps = unpac(pos)
x, y = mapa(ps[1], ps[0])
mapa.plot(x, y, 'o', markersize=7, color='#444444', alpha=0.8)
coordenadas.coordenadas.apply(plot_area)
plt.show()
/usr/lib64/python3.6/site-packages/mpl_toolkits/basemap/__init__.py:3298: MatplotlibDeprecationWarning: The ishold function was deprecated in version 2.0.
b = ax.ishold()
/usr/lib64/python3.6/site-packages/mpl_toolkits/basemap/__init__.py:3307: MatplotlibDeprecationWarning: axes.hold is deprecated.
See the API Changes document (http://matplotlib.org/api/api_changes.html)
for more details.
ax.hold(b)
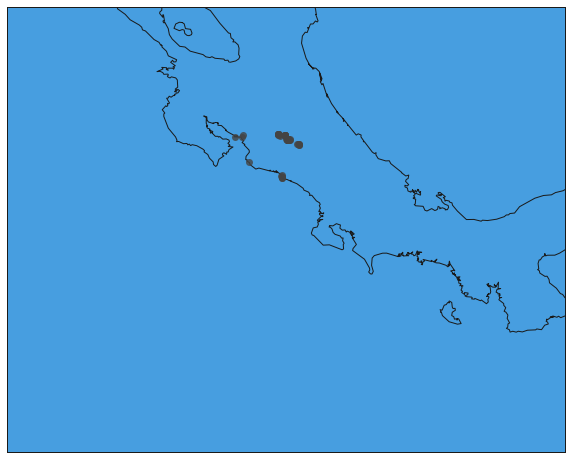
In [12]:
clox = array(coordenadas['longitud']) clay = array(coordenadas['latitud']) clo = list(clox) cla = list(clay)
In [51]:
clay.mean() clay
Out[51]:
array([ 10.01801 , 10.016787, 10.020168, 10.00602 , 9.98512 ,
10.001528, 9.998438, 9.99943 , 9.998952, 9.996179,
9.98495 , 9.99961 , 9.935734, 9.93335 , 9.93284 ,
9.93355 , 9.9356 , 9.9359 , 9.93454 , 9.927243,
9.93387 , 9.93191 , 9.93378 , 9.937275, 9.937206,
9.93281 , 9.868255, 9.864336, 9.864255, 9.86715 ,
9.97685 , 9.99725 , 9.974695, 9.61626 , 9.39646 ,
9.42387 , 9.43062 , 9.930423, 9.930036, 9.934636,
9.929361, 9.937733, 9.930169, 9.927714, 9.934579,
9.927496, 9.93141 , 9.938098, 9.927755, 9.933922,
9.936659, 9.932065, 9.927739, 9.930635, 9.932147,
9.93535 , 9.93286 , 9.927324, 10.018506, 10.018993,
10.002973, 9.408455, 9.39838 , 9.403425, 9.40677 ,
9.866258, 9.865848])
In [58]:
plt.figure(2)
#fig.add_subplot(223)
fig2, ax2 = plt.subplots(figsize=(20,10))
mapa2 = Basemap(projection='merc',
lat_0 = 9.74, lon_0 = -83.5,
resolution = 'i',
llcrnrlon=-88.1, llcrnrlat=7.5,
urcrnrlon=-80.1, urcrnrlat=11.8)
pos_x, pos_y = mapa2(clox, clay)
mapa2.drawmapboundary(fill_color='#A6CAE0', linewidth=0)
mapa2.fillcontinents(color='darkgrey', alpha=0.3)
mapa2.drawcoastlines(linewidth=0.1, color="white")
paleta = seaborn.diverging_palette(10, 220, sep=80, as_cmap=True)
#sns.cubehelix_palette(8, start=2, rot=0, dark=0, light=.95, reverse=True)
hb = plt.hexbin(pos_x, pos_y, gridsize=4, mincnt=1,
edgecolor='none', cmap = paleta)
cb = fig2.colorbar(hb, ax=ax2)
plt.show()
/usr/lib64/python3.6/site-packages/mpl_toolkits/basemap/__init__.py:1775: MatplotlibDeprecationWarning: The get_axis_bgcolor function was deprecated in version 2.0. Use get_facecolor instead.
axisbgc = ax.get_axis_bgcolor()
<matplotlib.figure.Figure at 0x7f8646f5d7f0>
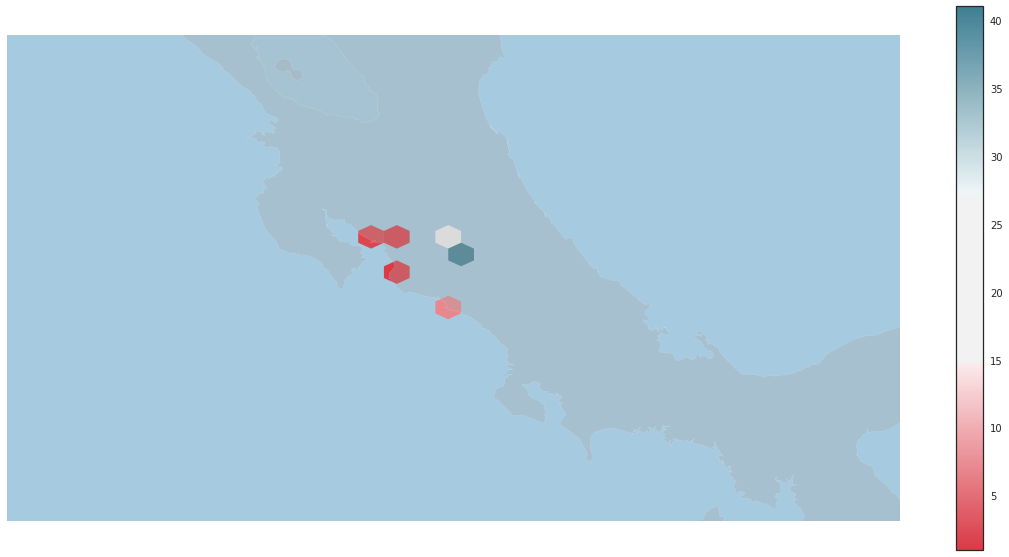
Cool links
- http://beneathdata.com/how-to/visualizing-my-location-history/
- https://pypi.python.org/pypi/descartes *
![]()
Los mapas son excelentes herramientas para visualizar datos de una ciudad y compararlos entre zonas de la misma. Pero si además podemos graficar los edificios en tres dimensiones, la visualización resulta más impactante aún. En este tutorial contamos cómo realizamos el mapa que muestra los precios promedio del metro cuadrado en cada parcela de la ciudad de Buenos Aires (Argentina) y San Pablo (Brasil), con sus respectivos edificios en 3D.
1. Obtener los shapefiles con las geometrías de las parcelas/edificios de la ciudad y su respectiva altura y un dataset con las propiedades en venta y su precio.
En el caso de Buenos Aires, la información está en archivos distintos.
- Por un lado la geometría de las parcelas.
- Y por otro la cantidad de pisos de cada edificio que hay en esas parcelas
- En www.properati.com.ar/data se pueden obtener todas las propiedades en venta en la ciudad.
2. Calcular el precio por metro cuadrado y la altura para cada parcela
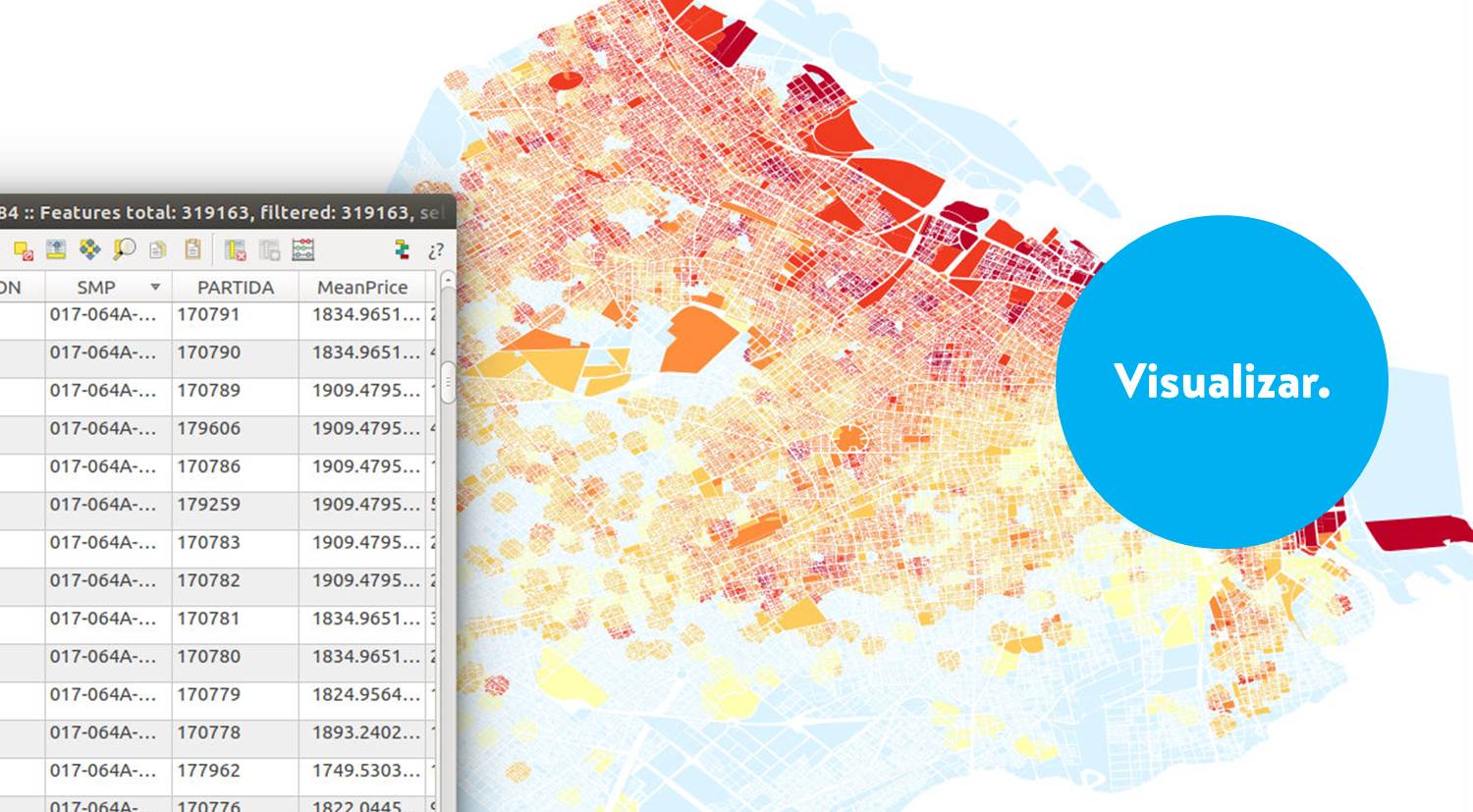
A partir del dataset de propiedades y el de parcelas, utilizando un spatial join de Qgis, se calcula el precio promedio del metro cuadrado que le corresponde a cada parcela. Este tutorial explica simplemente cómo hacerlo.
Luego unimos los datos de las parcelas con la altura de cada edificio.
Se hace una union de estos datasets por el campo que identifica a cada parcela, que incluye la “sección”, la “manzana” y la “parcela”, para así poder asociar cada parcela a su altura correspondiente.
3. Transformar el shapefile en un tileset vectorial
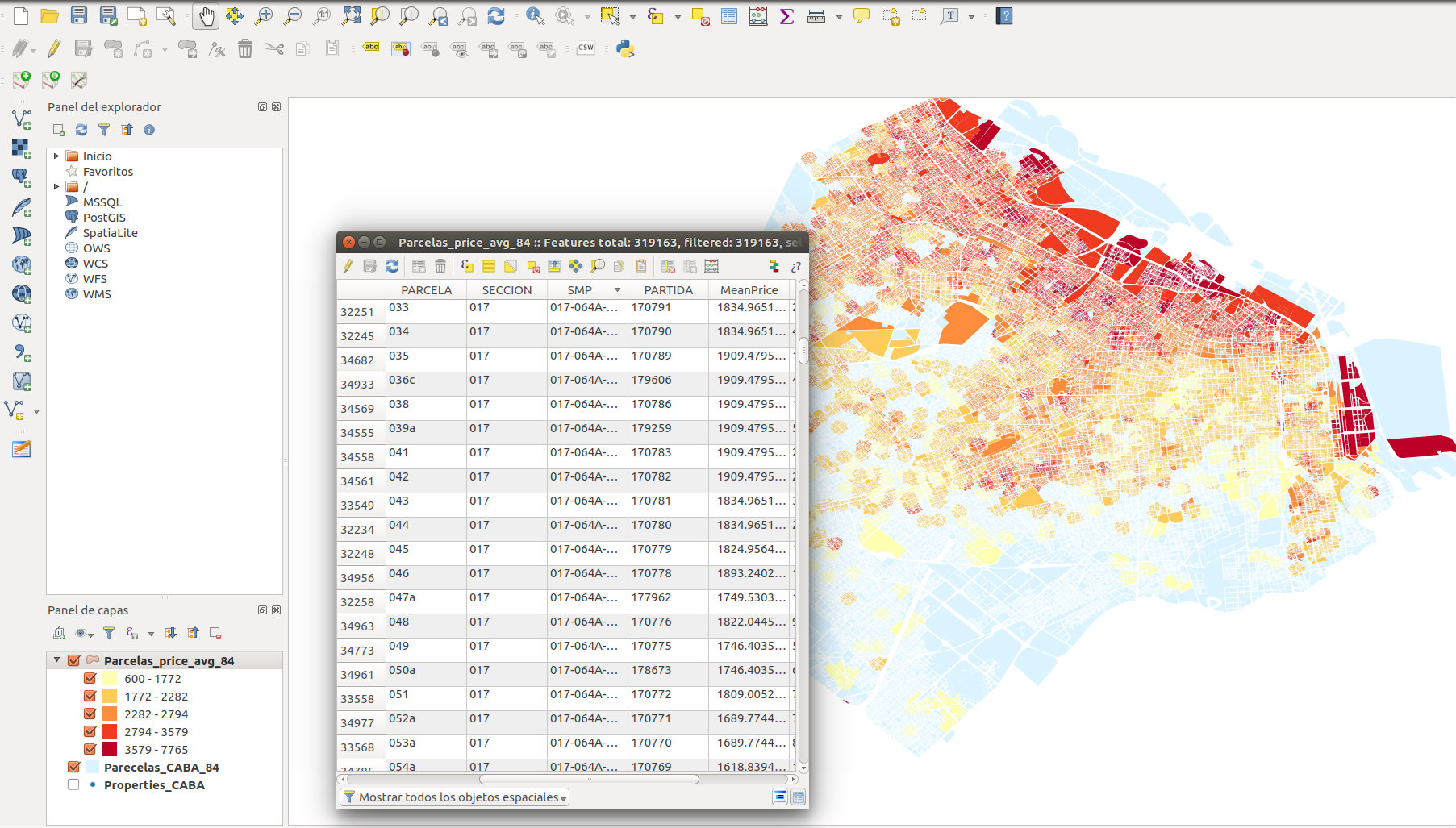
En este punto transformamos el shapefile en un tileset vectorial que es un tipo información georeferenciada que usan múltiples tecnologías de mapas digitales para mostrar los datos.
Se denominan «tilesets» porque se trata de un malla de mosaicos que cubre la superficie deseada: cada mosaico tiene cierta información que va siendo dibujada a medida que navegamos por esa zona del mapa. Si no fuera por estos mosaicos sería muy lento mostrar toda la información que muestra el mapa.
Primero hay que convertir el shapefile producido en el primer punto en un GEOJSON (QGis=> guardar como => GeoJSON).
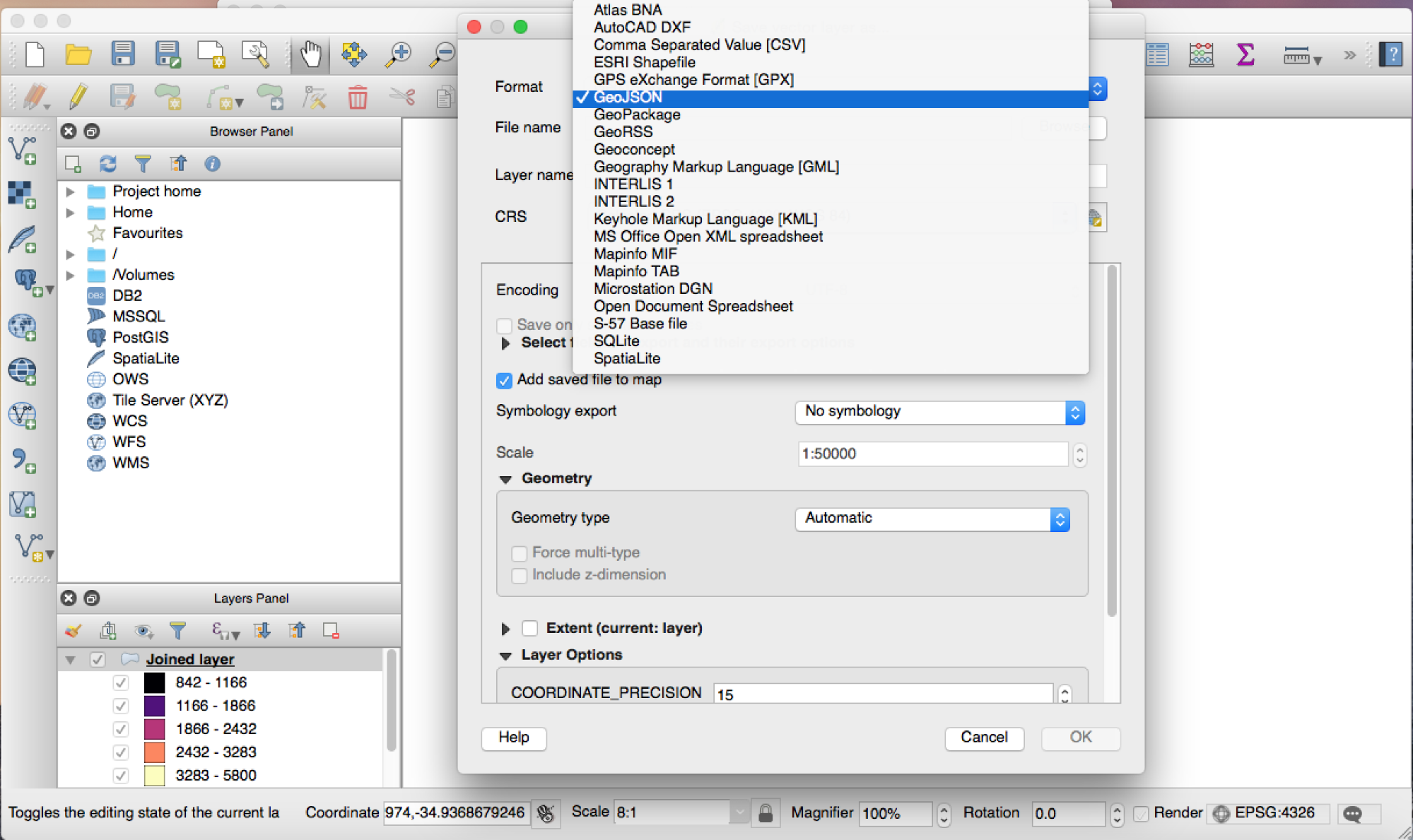
Usaremos el formato de tiles vectorial de Mapbox, mbtiles, ya que es ahí donde nosotros vamos a subir nuestro tileset. Para realizar la conversión de geojson a mbtiles usaremos el programa tippecanoe (https://github.com/mapbox/tippecanoe):
tippecanoe -o 3d_map_tileset.mbtiles -z 17 -Z 12 3d_map_tileset.geojson
Los parámetros z y Z son importantes, porque los tilesets se construyen por nivel de zoom. Cuanto más grande es el rango de zooms para el que se construye el tileset, más pesado es.
4. Subir el tileset a Mapbox Studio
Una vez generado el archivo, hay que subirlo a Mapbox Studio, en la sección datasets.
5. Programar Javascript
Vamos a necesitar programar un poco de javascript para poder mostrar la capa. De hecho, hay que hacer una aplicación en javascript que nos permita cargar un baselayer y el tileset en cuestión. Para eso vamos a usar Mapbox GL JS (https://github.com/mapbox/mapbox-gl-js). La documentación sobre la API se encuentra en https://www.mapbox.com/mapbox-gl-js/api/.
Supongamos que vamos a hacer todo en un archivo llamado “our_map.html”. Los pasos a seguir serían:
1. Crear el esqueleto de html:
<html>
<body
<!– mapbox gl js –>
<script src=’https://api.tiles.mapbox.com/mapbox-gl-js/v0.38.0/mapbox-gl.js’></script>
<link href=’https://api.tiles.mapbox.com/mapbox-gl-js/v0.38.0/mapbox-gl.css’ rel=’stylesheet’ />
<script>
// Here we are going to put our map code
</script>
</body>
</html>
Tenemos que realizar las siguientes tareas dentro del bloque <script>
2. Cargar mapbox
var center = [-58.388875,-34.612427];
mapboxgl.accessToken = ‘YOUR ACCESS TOKEN’;
var map = new mapboxgl.Map({
container: ‘map’,
style: ‘mapbox://styles/YOUTUSER/YOUR_BASE_STYLE’,
center: center,
zoom: 13.5,
pitch: 59.5,
bearing: 0
});
3. Cargar el tileset:
map.on(‘style.load’, function () {
map.addSource(‘buildings’,
{«type»: «vector»,
«url»: «THE TILESET URL»
});
map.addLayer({
‘id’: ‘buildings’,
‘interactive’: true,
‘type’: ‘fill-extrusion’,
‘source’: ‘buildings’,
‘source-layer’: ‘super_new_join_finalgeojson’,
‘paint’: {
‘fill-extrusion-height’: {
‘property’: ‘altura’,
‘stops’: [
[{zoom: 13, value: 0}, 0],
[{zoom: 13.5, value: 1000}, 0],
[{zoom: 17.5, value: 0}, 0],
[{zoom: 17.5, value: 1000}, 1000]
]
},
‘fill-extrusion-color’: {
‘property’: ‘precio’,
‘stops’: [
[0, ‘#e6e6e6’],
[700, ‘#ffffb2’],
[1754, ‘#fecc5c’],
[2233, ‘#fd8d3c’],
[2751, ‘#f03b20’],
[3683, ‘#bd0026’]
]
},
‘fill-extrusion-opacity’: 0.9
}
}, ‘road_major_label’);
});
Tomar nota de las partes más importantes:
‘fill-extrusion-height’: {
‘property’: ‘altura’,
…
}
Aquí estamos diciendo “tomar las alturas de los edificios del campo ‘altura’”.
Y
fill-extrusion-color: style: {
‘property’: ‘precio’,
‘stops’: [
[0, ‘#e6e6e6’],
[700, ‘#ffffb2’],
[1754, ‘#fecc5c’],
[2233, ‘#fd8d3c’],
[2751, ‘#f03b20’],
[3683, ‘#bd0026’]
]
}
Aquí estamos diciendo “pintar usando los valores del campo ‘precio’ y usar los rangos para diferenciar los colores”, si no hay valor, usar ‘#e6e6e6’, si el valor está entre 0 y 700, usar ‘#ffffb2’, si el valor está entre 700 y 1754 usar ‘#fecc5c’, y así sucesivamente.
El código completo sería:
<html>
<body
<!– mapbox gl js –>
<script src=’https://api.tiles.mapbox.com/mapbox-gl-js/v0.38.0/mapbox-gl.js’></script>
<link href=’https://api.tiles.mapbox.com/mapbox-gl-js/v0.38.0/mapbox-gl.css’ rel=’stylesheet’ />
<div style=»padding:0; margin:0; width:100%; height:100%» id=»map»></div>
<script>
window.onload = function(){
var center = [-58.388875,-34.612427];
mapboxgl.accessToken = ‘YOUR ACCESS TOKEN’;
var map = new mapboxgl.Map({
container: ‘map’,
style: ‘mapbox://styles/YOUTUSER/YOUR_BASE_STYLE’,
center: center,
zoom: 13.5,
pitch: 59.5,
bearing: 0
});
map.on(‘style.load’, function () {
map.addSource(‘buildings’,
{«type»: «vector»,
«url»: «THE TILESET URL»
});
map.addLayer({
‘id’: ‘buildings’,
‘interactive’: true,
‘type’: ‘fill-extrusion’,
‘source’: ‘buildings’,
‘source-layer’: ‘super_new_join_finalgeojson’,
‘paint’: {
‘fill-extrusion-height’: {
‘property’: ‘altura’,
‘stops’: [
[{zoom: 13, value: 0}, 0],
[{zoom: 13.5, value: 1000}, 0],
[{zoom: 17.5, value: 0}, 0],
[{zoom: 17.5, value: 1000}, 1000]
]
},
‘fill-extrusion-color’: {
‘property’: ‘precio’,
‘stops’: [
[0, ‘#e6e6e6’],
[700, ‘#ffffb2’],
[1754, ‘#fecc5c’],
[2233, ‘#fd8d3c’],
[2751, ‘#f03b20’],
[3683, ‘#bd0026’]
]
},
‘fill-extrusion-opacity’: 0.9
}
}, ‘road_major_label’);
});
}
</script>
</body>
</html>
Servir el HTML desde un server
Ahora hay que servir el html desde un server. En nuestra máquina local podemos usar http-server . Una vez instalado, (se puede instalar con npm: npm install http-server), hay que correrlo en la misma carpeta donde tenemos nuestro html. Y después, en el browser, navegar a localhost:8080/our_map.html.
![]()
Leer y escribir archivos, bases de datos y más
Al realizar una exploración de datos, estos pueden provenir de muchas fuentes, en algunos casos recursos en linea, bases de datos SQL o de otros tipos; en otros puede ser necesario exportar a algun formato para seguir el análisis en otra herramienta. Con las herramientas que ya conocemos (Python, Pandas, etc), es muy conveniente el poder utilizarlas para exportar e importar datos. Vamos a trabajar un poco con unas bases de datos sencillas que nos permitirán ejemplificar la facilidad y algunos posibles asuntos a la hora de manipular datos en distintas fuentas. Una de estas es una base de datos de estudios ambientales desde los inicios de los 90’s hasta el 2014, mientras otra son los centros educativos en Guatemala hasta el 2013Bases de datos: un Crash Course
Como hemos visto ya en estos tutoriales, Pandas es una libreria muy poderosa para manipular datos; sin embargo tiene también competencia obvia en sistemas de bases de datos, que dependiendo de su oferta ofrecen alguna de la funcionalidad de Pandas, junto con otra que es incomparable. Entre los conceptos fundamentales de bases de datos es reconocer la diferencia entre un DBMS (Database Management System) y una DB en sí. El DBMS es el software que permite acceder y controlar la base de datos; mientras que la DB son nuestros datos. Es comparable a la relación entre un reproductor multimedios y la música en sí, la diferencia mas notable es que practicamente no existe un estandar de bases de datos, mas allá de lo que provee SQL en si. Existe una variedad de modelos de bases de datos, para esta ocasión nos enfocaremos en el más común: SQL y bases de Datos RelacionalesRDBMS (Relational Database Management Systems)
SQL es un lenguaje que permite interactuar con bases de datos relacionales. El «Standard Query Language» es en la realidad, no tan estandar, sin embargo, hay un subconjunto que es compatible conocido como ANSI SQL y sus posteriores revisiones. Los ejemplos de este tutorial estarán en SQLite, una base de datos libre que ofrece alto rendimiento y poco uso de recursos, a contraparte de sus limitaciones como concurrencia limitada y el estar basada en archivos. La estaremos usando por su simplicidad, pero téoricamente podriamos usar casi cualquier otro DBMS. Algo muy notable y de tener en cuenta es que las Bases de datos Relacionales, como su nombre lo dice, están basadas en relaciones. Mucha gente confunde este concepto con el de llaves y uniones entre ellas, sin embargo es mucho mas profundo. En las bases de datos relacionales (y lo siento por si puede parecer un poco confuso): Las relaciones son agrupaciones de datos en las cuales se preserva su identidad, es decir representan algo, del cual queramos llevar registro; De estas agrupaciones, cada entidad o sea filas ó tuplas (que lleva su propia carga matemática), del mismo tipo se materializan en tablas, es decir las relaciones de bases de datos relacionales no se refieren a las relaciones que se pueden crear entre los datos, sinó a la estructura tabular en sí. Podemos tomar una pausa aquí y comenzar con el código. Es conveniente porque podremos ver varias de estas analogías en vivo.import pandas as pd
import numpy as np
import seaborn
import joypy
import matplotlib
matplotlib.rc("savefig", dpi=300)
%matplotlib notebook
import sqlite3
conexion_estudios_ambientales = sqlite3.connect("estudios_amb.sqlite3")
estudios = pd.read_sql("SELECT * FROM estudios_ambientales",
conexion_estudios_ambientales,
parse_dates=["Fecha_Captura","Fecha_Resolucion","Fecha_Notificacion","Fecha_Dictamen"])
estudios.head()
tiempos_espera=pd.concat(
{
"Periodo": estudios["Periodo"].map(int).astype(int),
"TiempoEspera": (estudios["Fecha_Captura"]-estudios["Fecha_Resolucion"]).map(lambda x: x.days)
},
axis=1
).dropna()
tiempos_espera
tiempos_espera.describe()
tiempos_espera.plot()
tiempos_espera[tiempos_espera["TiempoEspera"] > 0]
¿Con que esperaste cuánto?
+6926.000000 !!! Esto es un poco ridiculo. Pero este error está atado a la calidad del dato. Lo que podemos hacer es limpiarlo.tiempos_espera = tiempos_espera[tiempos_espera["Periodo"] < 2015]
tiempos_espera = tiempos_espera[tiempos_espera["TiempoEspera"] < 0] # Errores, probablemente año 1900? (IDK)
tiempos_espera = tiempos_espera[tiempos_espera["TiempoEspera"] > -10000] # Errores, probablemente año 1900? (IDK)
# print(tiempos_espera.Periodo.unique()) # Ver que años
tiempos_espera = tiempos_espera.set_index("Periodo")
tiempos_espera.describe()
# tiempos_espera.plot()
# verde_obscuro = seaborn.palplot(seaborn.cubehelix_palette(8, start=2, rot=0, dark=0, light=.95, reverse=True))
# %matplotlib inline
fig, axes = joypy.joyplot(tiempos_espera,
by="Periodo",
column="TiempoEspera",
fade=True,
#kind="normalized_counts",
hist=True,
bins=250,
grid=True,
range_style="own",
x_range=[-1255,100],
figsize=(4,8),
colormap=seaborn.cubehelix_palette(8, start=2, rot=0, dark=0, light=.95, reverse=True, as_cmap=True))
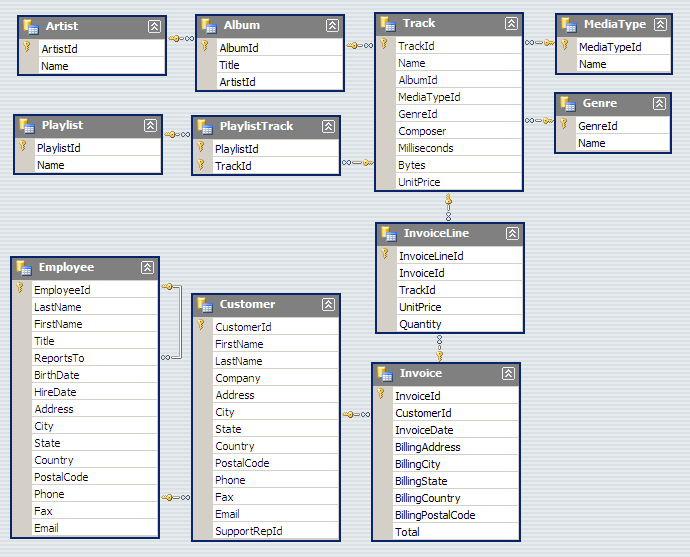
chinook_connection = sqlite3.connect("Chinook_Sqlite.sqlite")
chinook_dataframe = pd.read_sql("""Select *
FROM Track
LEFT OUTER JOIN MediaType ON MediaType.MediaTypeId = Track.MediaTypeId
LEFT OUTER JOIN Genre ON Genre.GenreId =Track.GenreId
LEFT OUTER JOIN Album ON Album.AlbumId = Track.AlbumId
LEFT OUTER JOIN Artist ON Artist.ArtistId = Album.ArtistId""", chinook_connection)
chinook_dataframe
chinook_connection = sqlite3.connect("Chinook_Sqlite.sqlite")
#artista_genero = pd.read_sql("""Select Genre.Name, Artist.Name
#FROM Track
#LEFT OUTER JOIN Genre ON Genre.GenreId = Track.GenreId
#LEFT OUTER JOIN Track ON Track.AlbumId = Album.AlbumId
#LEFT OUTER JOIN Artist ON Artist.ArtistId = Album.ArtistId """, chinook_connection)
#artista_genero
chinook_dataframe.to_csv()
tiempos_espera.to_excel("miarchivo.xls")
%time centros_educativos = pd.read_excel("14102014 - MINEDUC - CENTROS EDUCATIVOS REPUBLICA DE GUATEMALA.xlsx")
centros_educativos
# print(centros_educativos["AREA"].value_counts())
centros_educativos = centros_educativos[centros_educativos.AREA != "SIN ESPECIFICAR"]
print(centros_educativos["AREA"].value_counts())
for col in ["DISTRITO", "DEPARTAMENTO", "MUNICIPIO", "NIVEL","SECTOR","AREA","STATUS","MODALIDAD","JORNADA","PLAN"]:
centros_educativos[col] = centros_educativos[col].astype('category')
#centros_educativos.groupby(["JORNADA","PLAN","AREA"],).count()
centros_educativos.groupby(["JORNADA","PLAN","AREA"]).count()["CODIGO"]
seaborn.factorplot(
y="PLAN",
col="AREA",
hue="JORNADA",
row="NIVEL",
data=centros_educativos,
kind="count", size=4);
#seaborn.tsplot(centros_educativos.groupby(["JORNADA","PLAN","AREA"]).count()["CODIGO"])
# escuelas_heatmap_pivot = centros_educativos.pivot("PLAN", "AREA", "JORNADA")
escuelas_heatmap = centros_educativos.pivot("PLAN", "AREA", "JORNADA")
# Draw a heatmap with the numeric values in each cell
f, ax = plt.subplots(figsize=(9, 6))
sns.heatmap(escuelas_heatmap, annot=True, fmt="d", linewidths=.5, ax=ax,
y="PLAN", col="AREA", hue="JORNADA", row="NIVEL", data=centros_educativos)
![]()
Ese tutorial y documentación detallados en Jupyter Notebook fueron escritos por Sebastián Oliva, fellow 2017 de Escuela de Datos por Guatemala. En el webinar lanzado el 28 de junio puedes seguir paso a paso este ejercicio de limpieza y análisis de datos.
Introducción¶
Este es el primero de varios tutoriales introductorios al procesamiento y limpieza de datos. En este estaremos usando como ambiente de trabajo a Jupyter, que permite crear documentos con código y prosa, además de almacenar resultados de las operaciones ejecutadas (cálculos, graficas, etc). Jupyter permite interactuar con varios lenguajes de programación, en este, usaremos Python, un lenguaje de programación bastante simple y poderoso, con acceso a una gran variedad de librerias para procesamiento de datos. Entre estas, está Pandas, una biblioteca que nos da acceso a estructuras de datos muy poderosas para manipular datos.
¡Comenzemos entonces!
Instalación¶
Para poder ejecutar este Notebook, necesitas tener instalado Python 3, el cual corre en todos los sistemas operativos actuales, sin embargo, para instalar las dependencias: Pandas y Jupyter.
Modo Sencillo¶
Recomiendo utilizar la distribución Anaconda https://www.continuum.io/downloads en su versión para Python 3, esta incluye instalado Jupyter, Pandas, Numpy y Scipy, y mucho otro software útil. Sigue las instrucciones en la documentación de Anaconda para configurar un ambiente de desarollo con Jupyter.
https://docs.continuum.io/anaconda/navigator/getting-started.html
Una vez instalado, prueba a seguir los paso de https://www.tutorialpython.com/modulos-python/ o tu tutorial de Python Favorito.
«It’s a Unix System, I know This!» – Modo Avanzado¶
Te recomiendo utilizar Python 3.6 o superior, instalar la version mas reciente posible de virtualenv y pip. Usa Git para obtener el codigo, crea un nuevo entorno de desarollo y ahi instala las dependencias necesarias.
~/$ cd notebooks
~/notebooks/$ git clone https://github.com/tian2992/notebooks_dateros.git
~/notebooks/$ cd notebooks_dateros/
~/notebooks/notebooks_dateros/$
~/notebooks/notebooks_dateros/$ virtualenv venv/
~/notebooks/notebooks_dateros/$ source venv/bin/activate
~/notebooks/notebooks_dateros/$ pip install -r requirements.txt
~/notebooks/notebooks_dateros/$ cd 01-Intro
~/notebooks/notebooks_dateros/$ 7z e municipal_guatemala_2008-2011.7z
~/notebooks/notebooks_dateros/$ jupyter-notebookPrimeros pasos¶
## En Jupyter Notebooks existen varios tipos de celdas, las celdas de código, como esta:
print(1+1)
print(5+4)
6+4
Y las celdas de texto, que se escriben en Markdown y son hechas para humanos. Pueden incluir negritas, itálicas Entre otros tipos de estilos. Tambien pueden incluirse imagenes o incluso interactivos.
%pylab inline
import seaborn as sns
import pandas as pd
pd.set_option('precision', 5)
Con estos comandos, cargamos a nuestro entorno de trabajo las librerias necesarias.
Usemos la funcion de pandas read_csv para cargar los datos. Esto crea un DataFrame, una unidad de datos en Pandas, que nos da mucha funcionalidad y tiene bastantes propiedades convenientes para el análisis. Probablemente esta operación tome un tiempo asi que sigamos avanzando, cuando esté lista, verás que el numero de la celda habrá sido actualizado.
muni_data = pd.read_csv("GUATEMALA MUNICIPAL 2008-2011.csv",
sep=";")
muni_data.head()
DataFrames y más¶
Aqui podemos ver el dataframe que creamos.
En Pandas, los DataFrames son unidades básicas, junto con las Series.
Veamos una serie muy sencilla antes de pasar a evaluar muni_data, el DataFrame que acabamos de crear. Crearemos una serie de numeros aleatorios, y usaremos funciones estadisticas para analizarlo.
serie_prueba_s = pd.Series(np.random.randn(5), name='prueba')
print(serie_prueba_s)
print(serie_prueba_s.describe())
serie_prueba_s.plot()

Con esto podemos ver ya unas propiedades muy interesantes. Las series están basadas en el concepto estadistico, pero incluyen un título (del eje), un índice (el cual identifica a los elementos) y el dato en sí, que puede ser numerico (float), string unicode (texto) u otro tipo de dato.
Las series estan basadas tambien en conceptos de vectores, asi que se pueden realizar operaciones vectoriales en las cuales implicitamente se alinean los indíces, esto es muy util por ejemplo para restar dos columnas, sin importar el tamaño de ambas, automaticamente Pandas unirá inteligentemente ambas series. Puedes tambien obtener elementos de las series por su valor de índice, o por un rango, usando la notación usual en Python. Como nota final, las Series comparten mucho del comportamiento de los NumPy Arrays, haciendolos instantaneamente compatibles con muchas librerias y recursos. https://pandas.pydata.org/pandas-docs/stable/dsintro.html#series
serie_prueba_d = pd.Series(np.random.randn(5), name='prueba 2')
print(serie_prueba_d)
print(serie_prueba_d[0:3]) # Solo los elementos del 0 al 3
# Esto funciona porque ambas series tienen indices en común.
# Si sumamos dos con tamaños distintos, los espacios vacios son marcados como NaN
serie_prueba_y = serie_prueba_d + (serie_prueba_s * 2)
print(serie_prueba_y)
print("La suma de la serie y es: {suma}".format(suma=serie_prueba_y.sum()))
Pasemos ahora a DataFrames, como nuestro muni_data DataFrame. Los DataFrames son estructuras bi-dimensionales de datos. Son muy usadas porque proveen una abstracción similar a una hoja de calculo o a una tabla de SQL. Los DataFrame tienen índices (etiquetas de fila) y columnas, ambos ejes deben encajar, y el resto será llenado de datos no validos.
Por ejemplo podemos unir ambas series y crear un DataFrame nuevo, usando un diccionario de Python, por ejemplo. Tambien podemos graficar los resultados.
prueba_dict = {
"col1": serie_prueba_s,
"col2": serie_prueba_d,
"col3": [1, 2, 3, 4, 0]
}
prueba_data_frame = pd.DataFrame(prueba_dict)
print(prueba_data_frame)
# La operacion .sum() ahora retorna un DataFrame, pero Pandas sabe no combinar peras con manzanas.
print("La suma de cada columna es: \n{suma}".format(suma=prueba_data_frame.sum()))
prueba_data_frame.plot()

Veamos ahora ya, nuestro DataFrame creado con los datos, muni_data.
#muni_data
# Una grafica bastante inutil, ¿porque?
muni_data.plot()

# Veamos los datos, limitamos a solo los primeros 5 filas.
muni_data.head(5)
## La columna 'APROBADO' se ve un poco sospechosa.
## Python toma a los numeros como números, no con una Q ni un punto (si no lo tiene) ni comas innecesarias.
## Veamos mas a detalle.
muni_data['APROBADO'].head()
# Vamos a ignorar esto por un momento, pero los números de verdad son de tipo float
Veamos cuantas columnas son, podemos explorar un poco mas asi.
muni_data.columns
muni_data['MUNICIPIO'].unique()[:5] # Listame 5 municipios
print("Funcion 1: \n {func1} \n Funcion 2: \n {func2} \n Funcion 3: \n{func3}".format(
func1=muni_data["FUNC1"].unique(),
func2=muni_data["FUNC2"].unique(),
func3=muni_data["FUNC3"].unique()
)
)
Vamos a explorar un poco con indices y etiquetas:
index_geo_data = muni_data.set_index("DEPTO","MUNICIPIO").sort_index()
index_geo_data.loc[
["GUATEMALA","ESCUINTLA","SACATEPEQUEZ"],
['FUNC1','FUNC2','FUNC3','APROBADO','EJECUTADO']
].head()
Ahora que podemos realizar selección basica, pensamos, que podemos hacer con estos datos, y nos enfrentamos a un problema…
muni_data['APROBADO'][3] * 2
¡Rayos! porque no puedo manipular estos datos así como los otros, y es porque son de tipo texto y no números.
# muni_data['APROBADO'].sum() ## No correr, falla...
Necesitamos crear una funcion para limpiar estos tipos de dato que son texto, para poderlos convertir a numeros de tipo punto flotante (decimales).
## Esto es una funcion en Python, con def definimos el nombre de esta funcion, 'clean_q'
## esta recibe un objeto de entrada.
def clean_q(input_object):
from re import sub ## importamos la función sub, que substituye utilizando patrones
## https://es.wikipedia.org/wiki/Expresión_regular
## NaN es un objeto especial que representa un valor numérico invalido, Not A Number.
if input_object == NaN:
return 0
inp = unicode(input_object) # De objeto a un texto
cleansed_q = sub(r'Q\.','', inp) # Remueve Q., el slash evita que . sea interpretado como un caracter especial
cleansed_00 = sub(r'\.00', '', cleansed_q) # Igual aqui
cleansed_comma = sub(',', '', cleansed_00)
cleansed_dash = sub('-', '', cleansed_comma)
cleansed_nonchar = sub(r'[^0-9]+', '', cleansed_dash)
if cleansed_nonchar == '':
return 0
return cleansed_nonchar
presupuesto_aprobado = muni_data['APROBADO'].map(clean_q).astype(float)
presupuesto_aprobado.describe()
muni_data['EJECUTADO'].head()
muni_data['FUNC1'].str.upper().value_counts()
presupuesto_aprobado.plot()

Bueno, ahora ya tenemos estas series de datos convertidas. ¿como las volvemos a agregar al dataset? ¡Facil! lo volvemos a insertar al DataFrame original, sobreescribiendo esa columna.
for col in ('APROBADO', 'RETRASADO', 'EJECUTADO', 'PAGADO'):
muni_data[col] = muni_data[col].map(clean_q).astype(float)
muni_data['APROBADO'].sum()
muni_data.head()
muni_data['ECON1'].unique()
Ahora si, ¡ya podemos agrupar y hacer indices bien!
index_geo_data = muni_data.set_index("DEPTO","MUNICIPIO").sort_index()
index_geo_data.head(40)
mi_muni_d = muni_data.set_index(["ANNO"],["DEPTO","MUNICIPIO"],["FUNC1","ECON1","ORIGEN1"]).sort_index()
mi_muni_d.head()
## Para obtener mas ayuda, ejecuta:
# help(mi_muni_d)
mi_muni_d.columns
mi_muni_d["DEPTO"].describe()
year_grouped = mi_muni_d.groupby("ANNO").sum()
year_grouped
year_dep_grouped = mi_muni_d.groupby(["ANNO","DEPTO"]).sum()
year_dep_grouped.head()
sns.set(style="whitegrid")
# Draw a nested barplot to show survival for class and sex
g = sns.factorplot( data=year_dep_grouped,
size=6, kind="bar", palette="muted")
# g.despine(left=True)
g.set_ylabels("cantidad")

year_dep_grouped.head()
Contestando preguntas¶
Ahora ya podemos contestar algunas clases de preguntas agrupando estas entradas individuales de de datos.
¿Que tal el departamento que tiene mas gasto en Seguridad? ¿Los tipos de gasto mas elevados como suelen ser pagados?
year_grouped.plot()

year_dep_group = mi_muni_d.groupby(["DEPTO","ANNO"]).sum()
year_dep_group.unstack().head()
func_p = mi_muni_d.groupby(["FUNC1"]).sum()
func_dep = mi_muni_d.groupby(["FUNC1","DEPTO"]).sum()
func_p
func_dep_flat = func_dep.unstack()
func_dep_flat.head()
mi_muni_d.groupby(["DEPTO"]).sum()
func_p.plot(kind="barh", figsize=(8,6), linewidth=2.5)

![]()
A partir de un set de datos (que puede ser .csv, o .xls) puedes entrenar esta API para que trabaje para ti. En la interfaz web de MonkeyLearn puedes ir probando y entrenando para aplicar un modelo. Debido a que es una API, esta plataforma es integrable con otros lenguajes de programación que te permitirán procesar los textos de tu fuente de datos a tiempo real y publicarlos.
Una de las ventajas de esta plataforma es que no tienes que ser programador o un experto en Machine Learning para empezar a usarla. La interfaz de usuario te irá dando pasos que deberás seguir para crear un modelo y cuando entiendas la manera en que funciona, podrás ir avanzando en su uso.
Esta herramienta aprende a base de clasificadores de texto, una categoría o etiqueta que se asigna automáticamente a una pieza de texto. Aunque el programa ya cuenta con unos clasificadores comunes, puedes crear los propios.
Con base en estas etiquetas, MonkeyLearn hará una clasificación al leer el contenido de tu set de datos. Por ejemplo, en una base de datos sobre proyectos de compras de una institución pública, esta herramienta te podría ayudar a reconocer los rubros de los fondos, o a clasificar qué tipo de productos se compraron y clasificarlos en base a una jerarquía establecida.
Al leer el texto, MonkeyLearn aplica los parámetros establecidos en los clasificadores de texto y te provee un resultado. El resultado se muestra en lenguaje JSON, para la API. La categorización del producto puede ser en varias categorías, por ejemplo Compras / Materiales de construcción / Asfalto. Aparte de esta clasificación, el programa también te provee un valor de probabilidad, el cual determina el nivel de certidumbre sobre la predicción realizada para que puedas mantener control sobre el rigor con el que tu modelo se aplica y la manera en que funciona.
Los módulos
Esta herramienta te permite tres funciones principales que indican el tipo de módulo que creas:
- Clasificación: Es un módulo que toma el texto y lo devuelve con etiquetas o categorías organizadas en algún tipo de jerarquía
- Extracción: Es el módulo que extrae ciertos datos dentro de un texto, que pueden ser entidades, nombres, direcciones, palabras clave, etc.
- Pipeline: Es el módulo que combina otros módulos, tanto de clasificación como de extracción, para que puedas construir un modelo más robusto con mayor nivel de procesamiento.
Las tres funciones principales de esta plataforma son:
- Análisis de sentimientos: Te permite detectar sentimientos (positivos, negativos, etc) en un texto a través de machine learning.
- Categorización de temas: Identifica el tema de un texto y lo reconoce.
- Otras clasificaciones: Clasifica los contenidos de un texto y los asigna a una jerarquía.
Tutorial: Cómo crear un clasificador de textos a partir de una descripción
Para probar esta herramienta, vamos a crear un clasificador que lea un texto y lo asigne a una categoría y jerarquía establecida por nosotros. En este caso, trabajaré con los datos de las compras del estado de Guatemala. Aunque mi set de datos contiene mucha información, voy a trabajar solo con el campo “Descripción” que tiene contenidos como este: INTRODUCCION DE ENERGIA ELECTRICA, CASERIO PENIEL, TUCURU, A. V.
Para utilizar MonkeyLearn debes crear un usuario o vincularlo a tu cuenta de Github.
Al hacer click en +Create Module se te desplegarán las opciones para guardar tu primer clasificador.
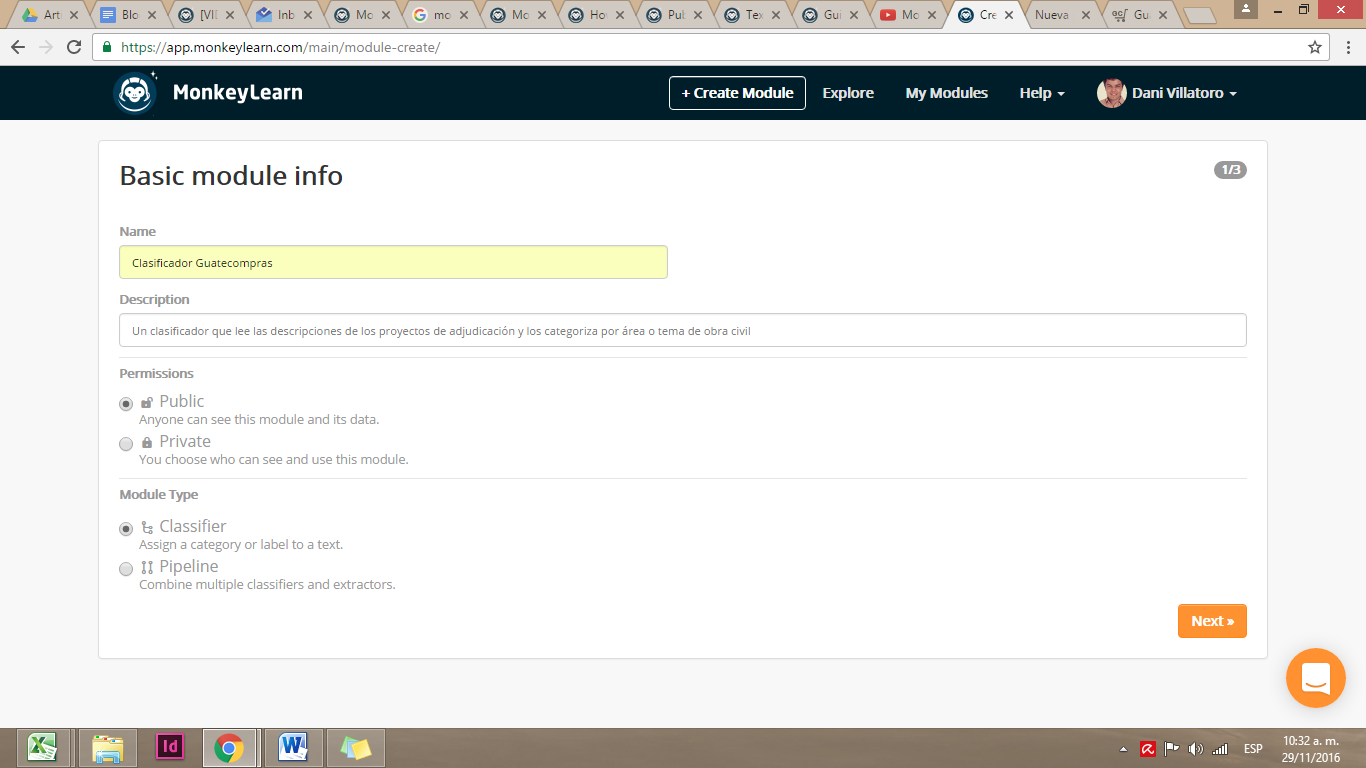
MonkeyLearn te va guiando paso a paso para que completes la información necesaria para crear un módulo. Al rellenar los datos de tu clasificador, da click en Next.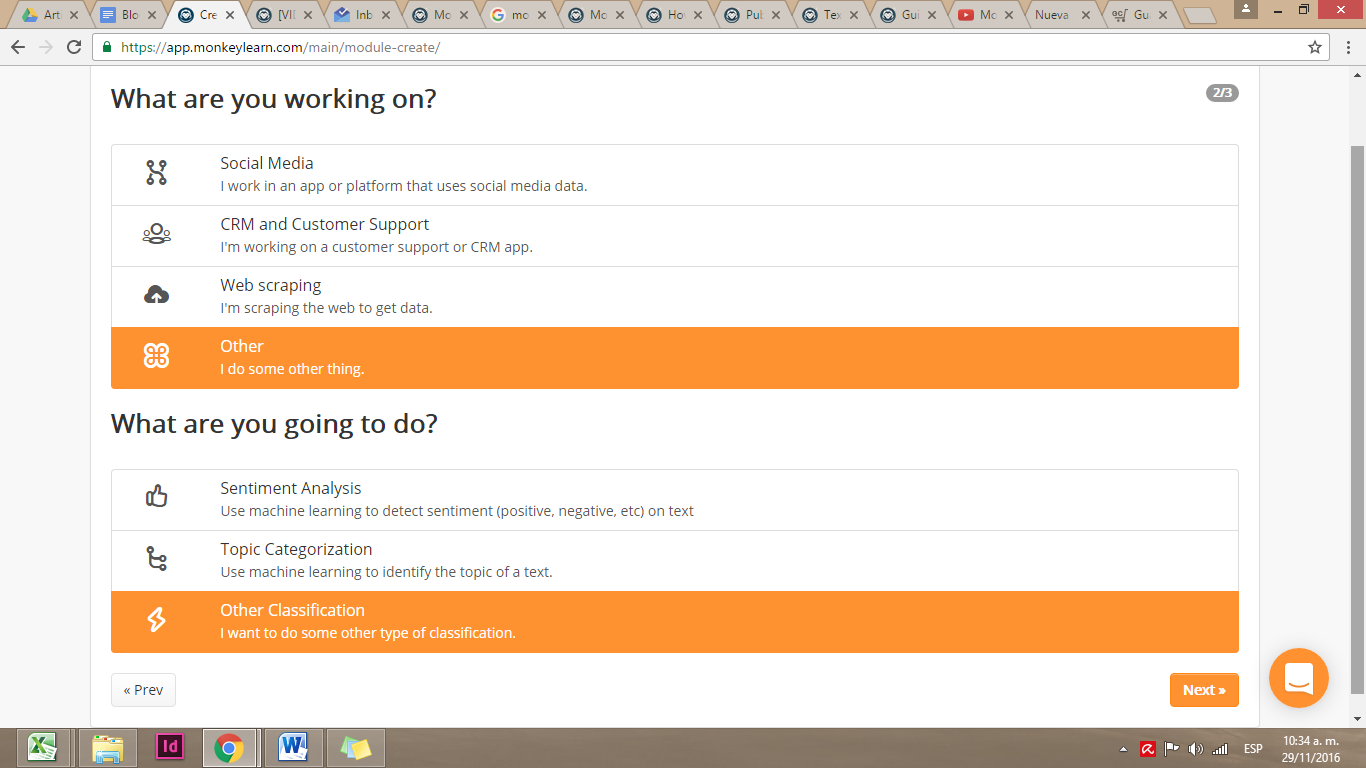
Responde a las preguntas que te hace sobre el tipo de trabajo que estás haciendo. En este caso, seleccionamos “otras clasificaciones”.
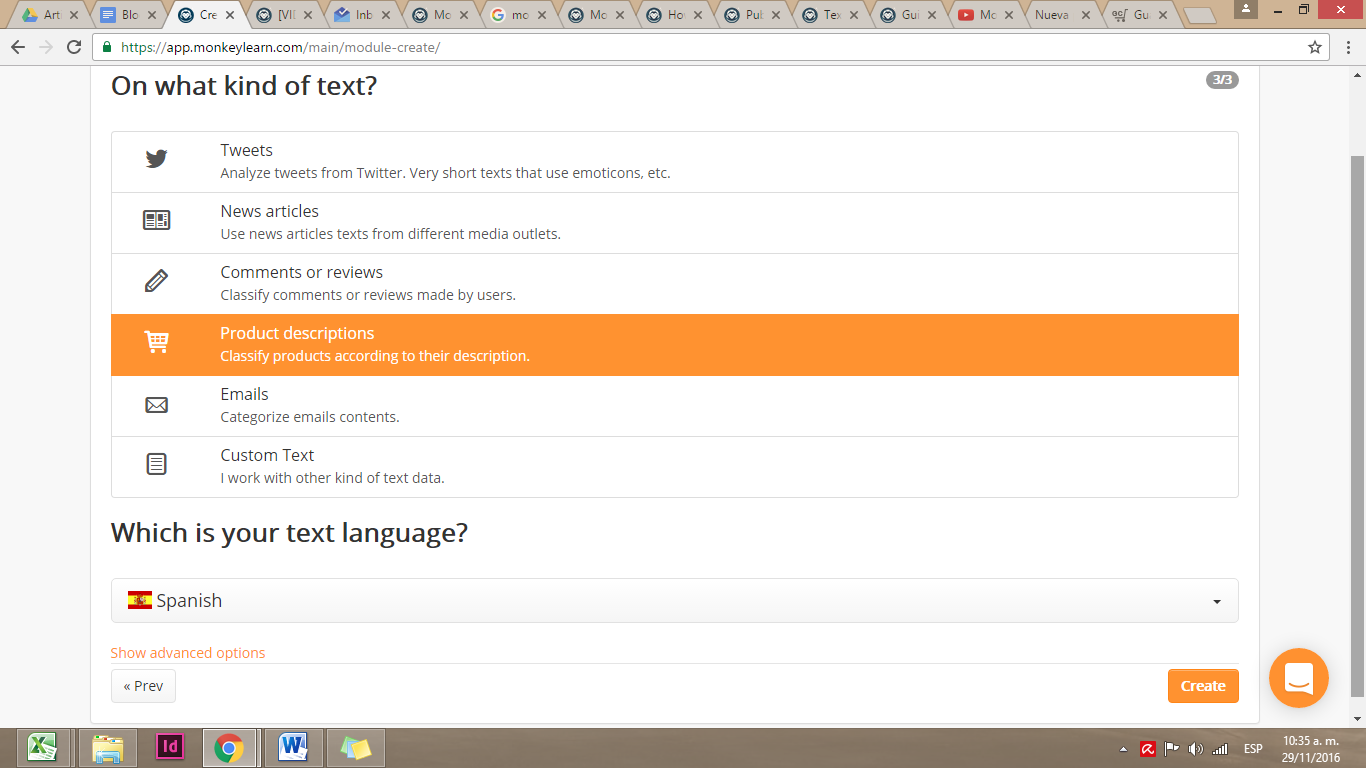
Selecciona la opción que más se ajuste al tipo de texto que vas a analizar, pueden ser tweets (textos cortos con emoticones), noticias de diferentes medios, comentarios o reseñas de usuarios, descripciones de productos, emails, o texto personalizado. Debido a que estamos trabajando las compras del estado, vamos a seleccionar Product Descriptions. También es importante que señales el idioma en que está tu texto.
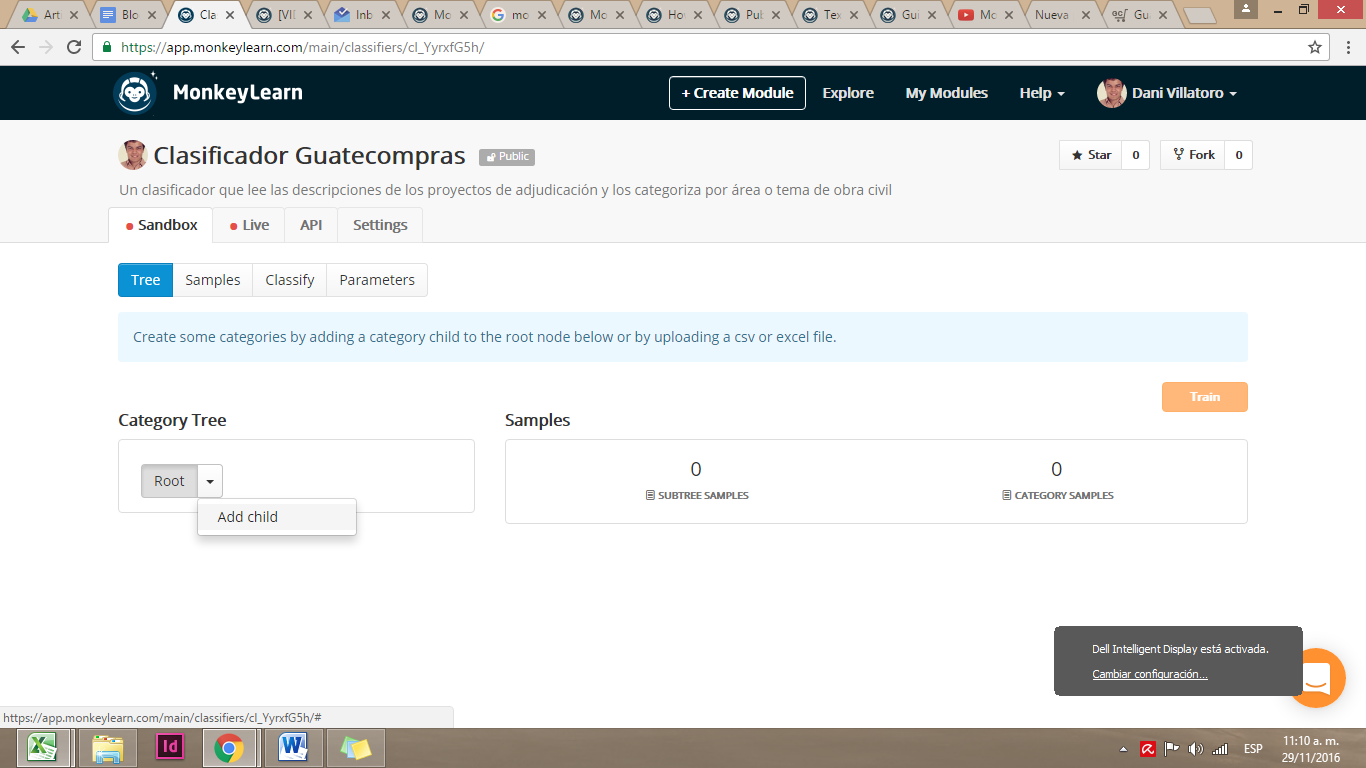
Al crear tu módulo, se abrirá un panel con diferentes opciones. En Category Tree se enlistan las diferentes categorías de tu modelo. Para crear nuevas categorías, haz click en el menú a la par de Root y selecciona Add child. Al hacer esto, creas nuevas categorías “hijas”. En este caso crearemos “Agua potable” “Caminos y carreteras” “Energía eléctrica” “Agricultura” y cuantas secciones queramos tener. MonkeyLearn también permite añadir subcategorías dentro de las categorías.
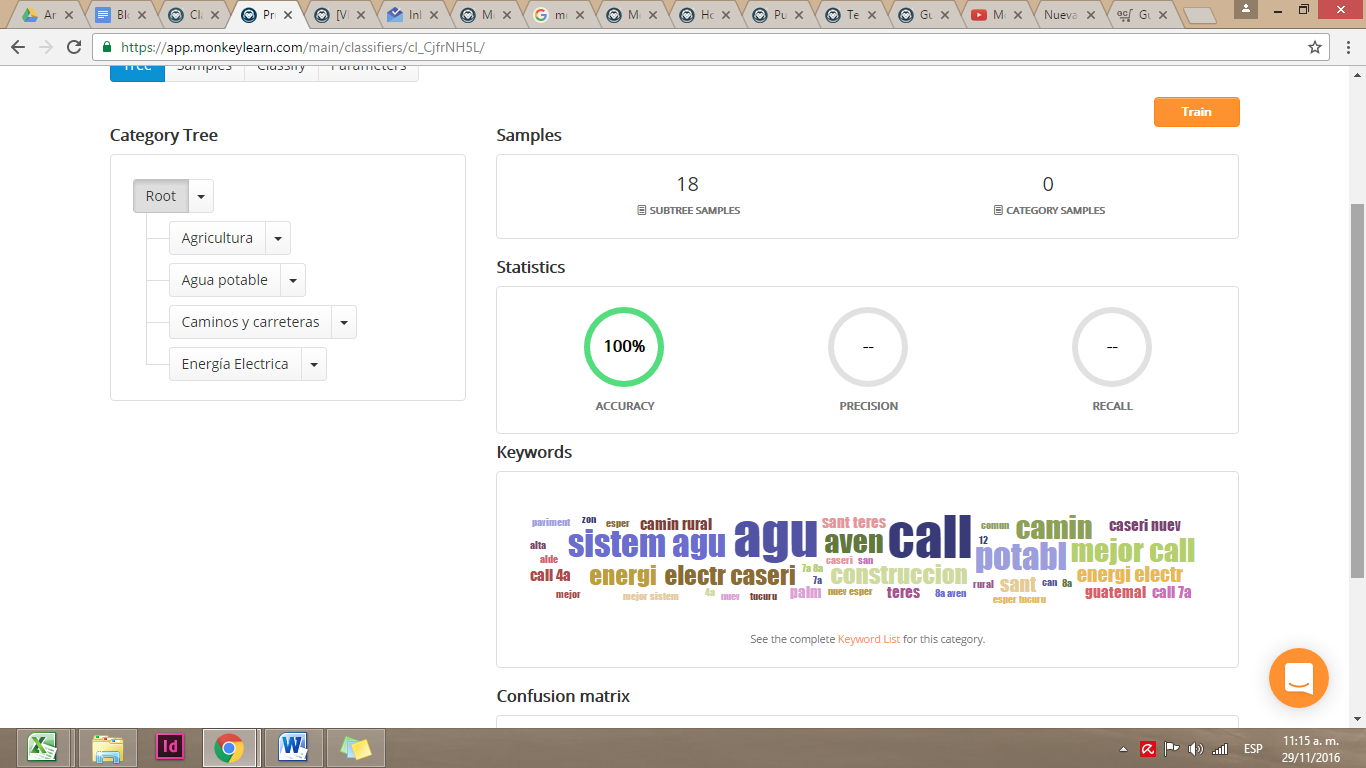
Para que nuestro modelo funcione, debemos entrenar cada categoría con ejemplos que le permitirán al programa reconocer automáticamente textos similares a los ejemplos que le dimos. Al hacer click en el menú desplegable a la par de cada categoría se muestra la opción Create sample, que te permite ingresar ejemplos.
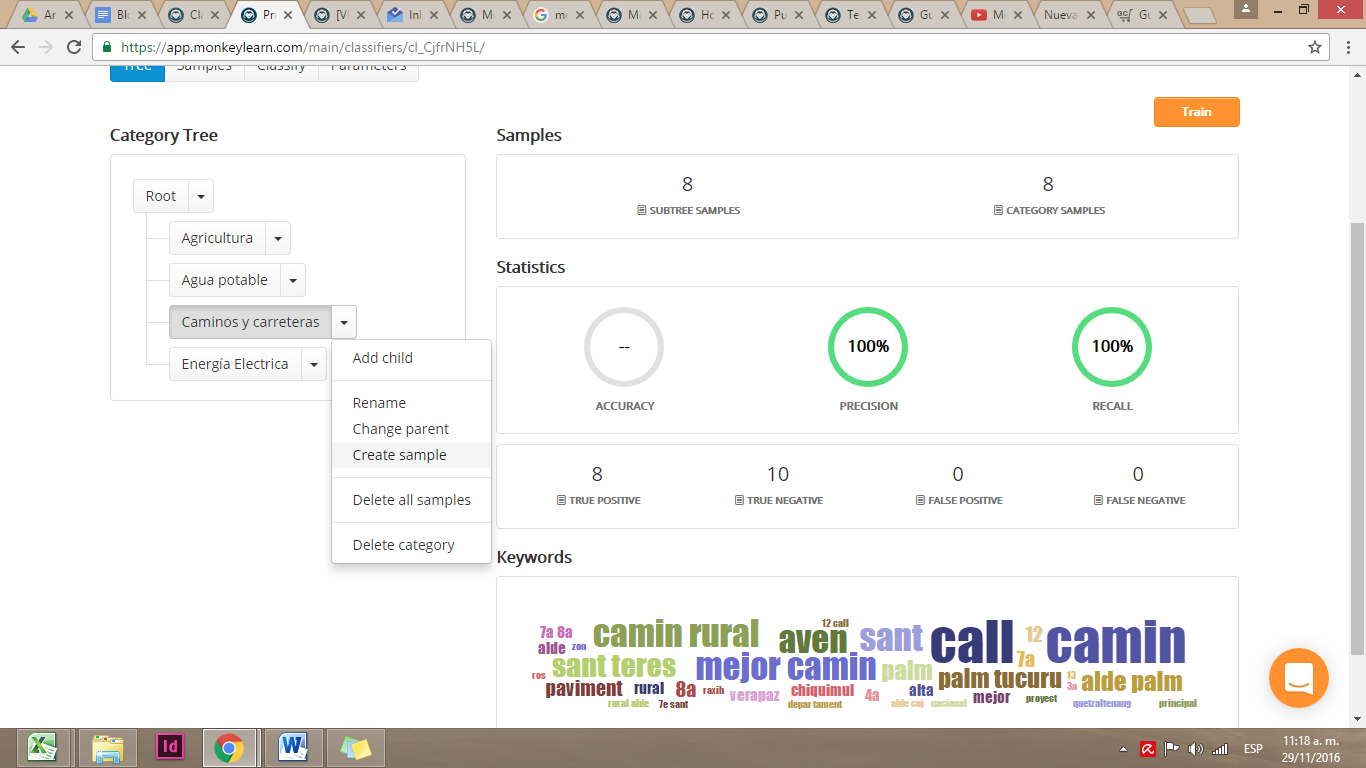
Para entrenar la categoría “Caminos y carreteras” vamos a añadir cuantos ejemplos podamos de descripciones que se ajusten a esta sección. Por ejemplo, “MEJORAMIENTO CALLE PAVIMENTADO Y ENCUNETADO…”. El agregar muchos ejemplos robustece la capacidad de que nuestro modelo identifique con mayor celeridad las categorías.
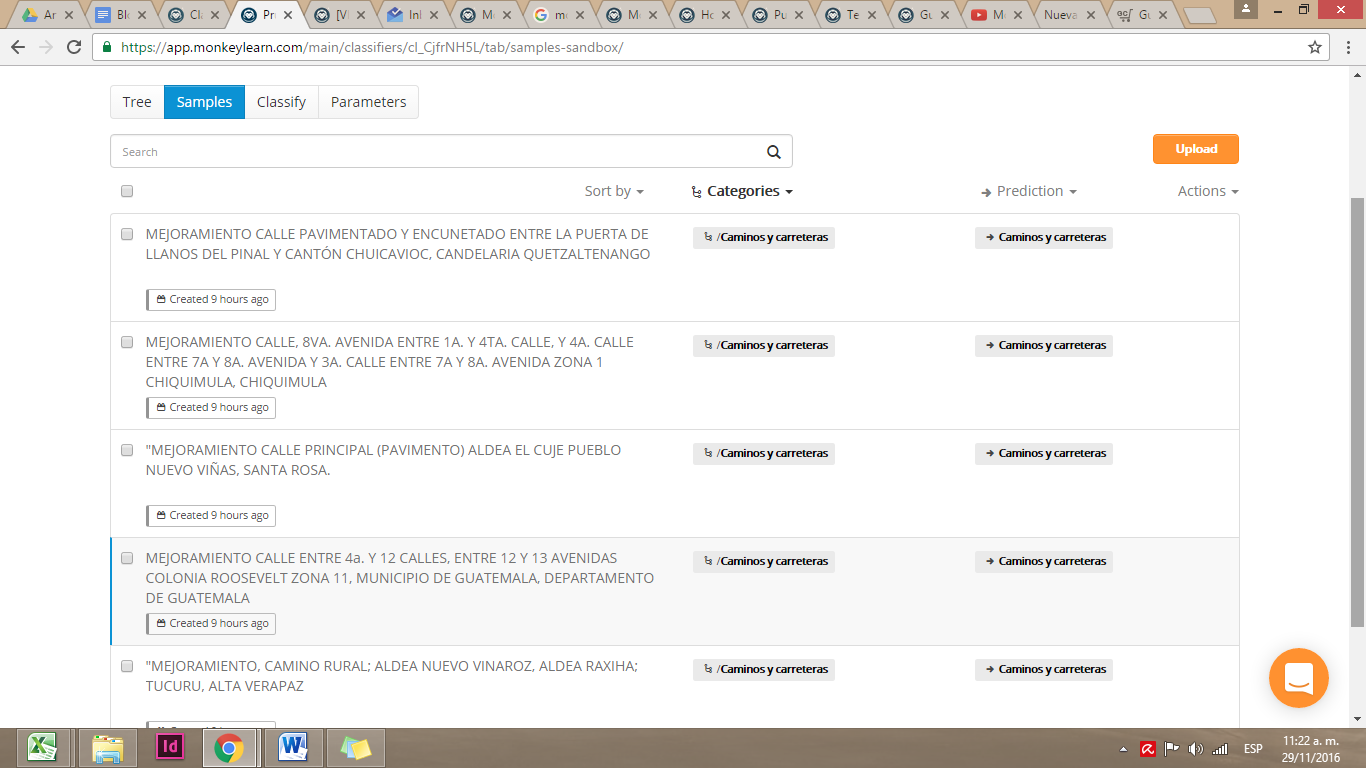
El panel principal de MonkeyLearn muestra las categorías en la sección Tree. Al hacer click en Samples, podemos ver los ejemplos que añadimos para cada categoría.
Luego de añadir varios ejemplos a todas nuestras categorías, dejamos que las capacidades de machine learning se ajusten al hacer click en Train
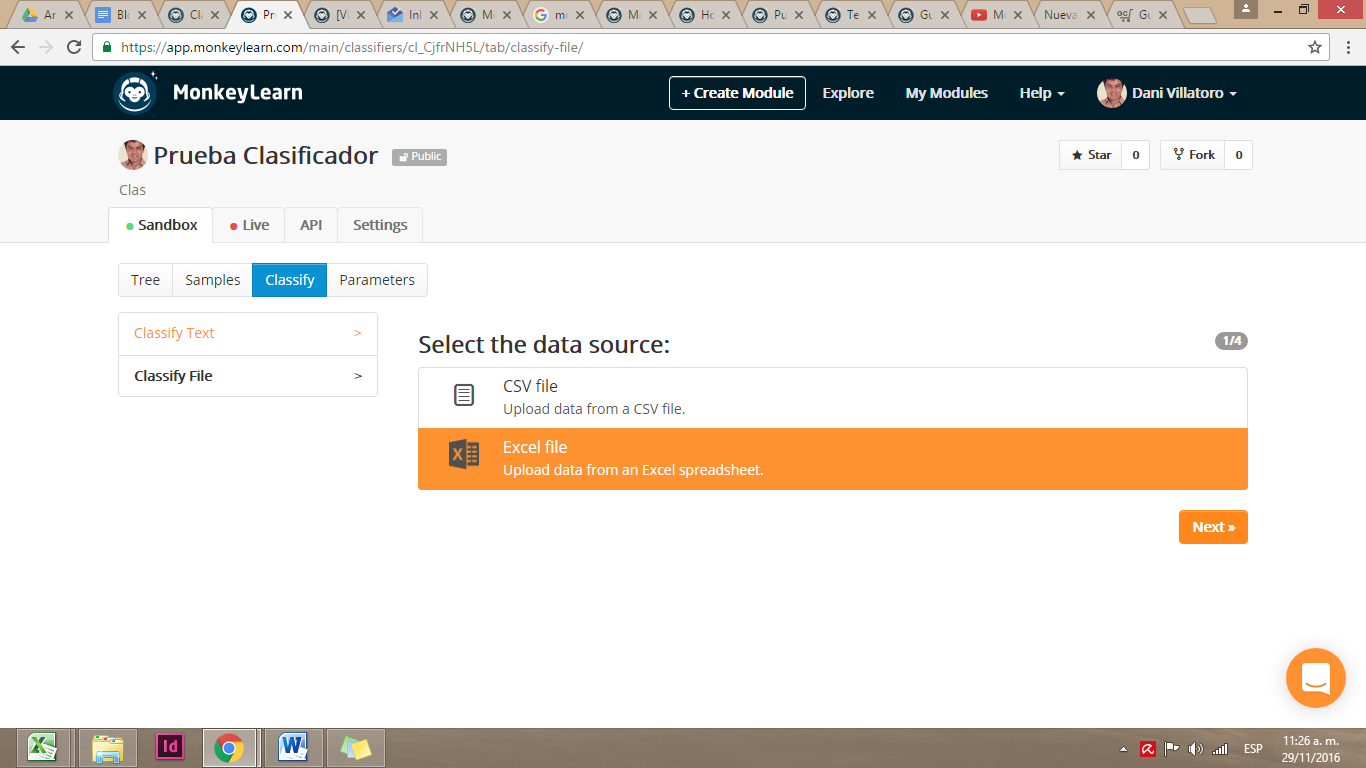
Con nuestro modelo ya entrenado, nos vamos a la secció Classify para aplicar este modelo a un set de datos. La fuente de datos puede ser un texto corrido o un archivo csv o xls.
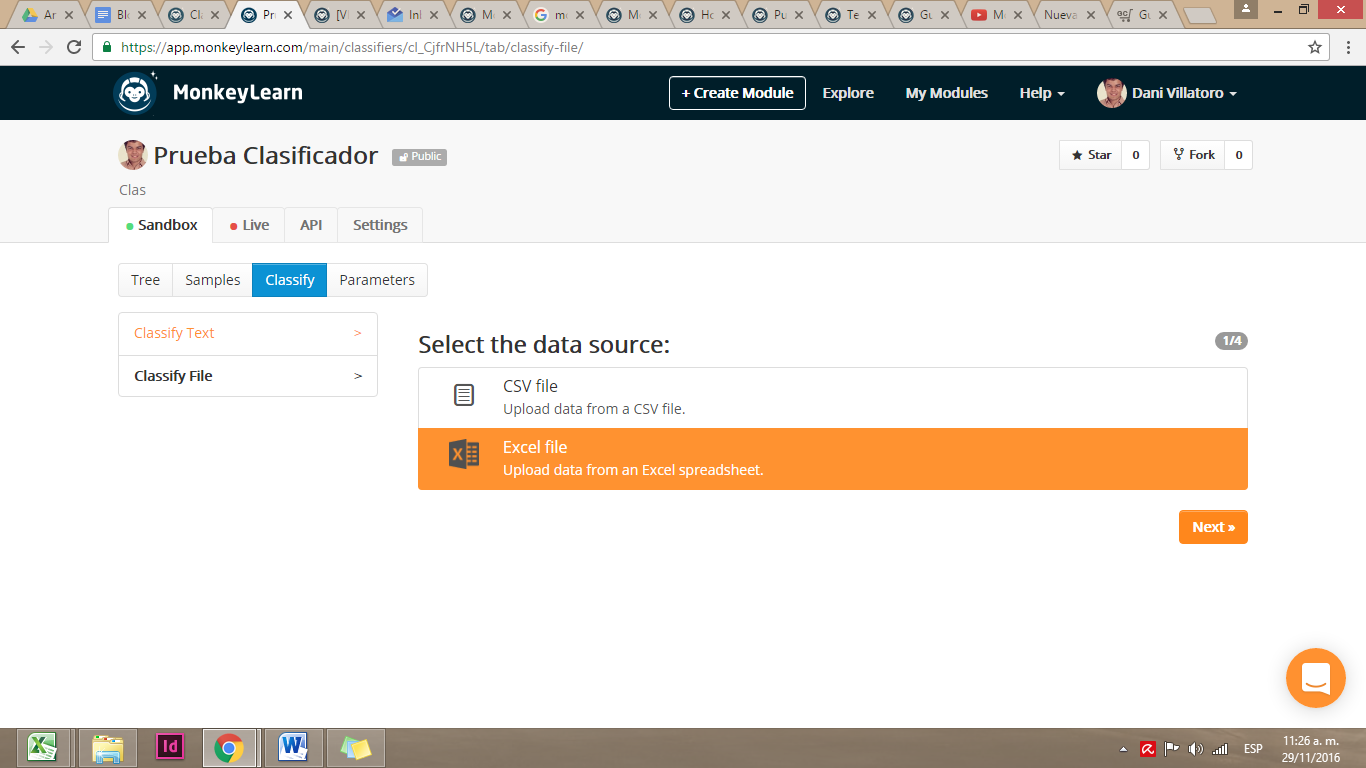
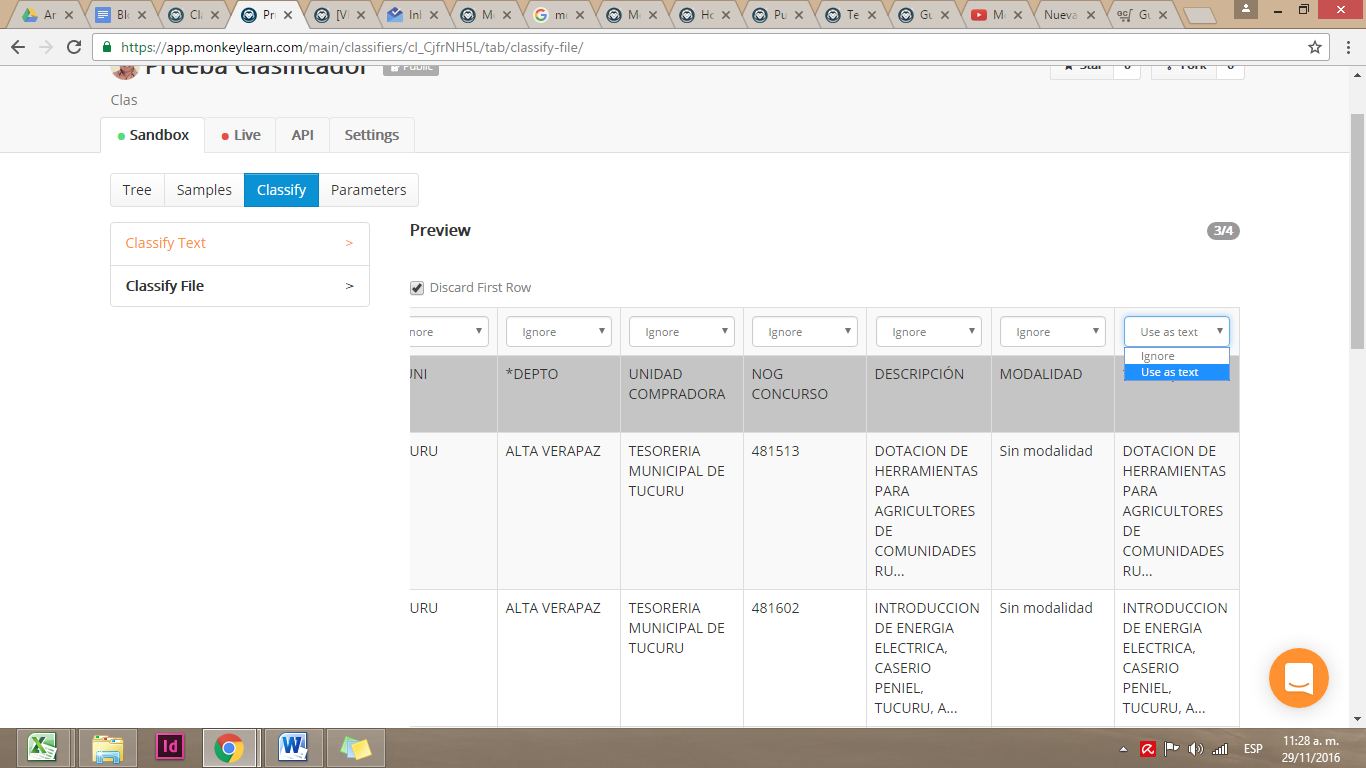
Seleccionamos nuestro archivo y nos presenta una muestra de nuestro set de datos y nos pregunta qué columna es la que vamos a analizar. Para seleccionar nuestra columna debemos marcar la opción Use as text que se muestra en la primera fila. Y para aplicar el modelo pulsamos Next.
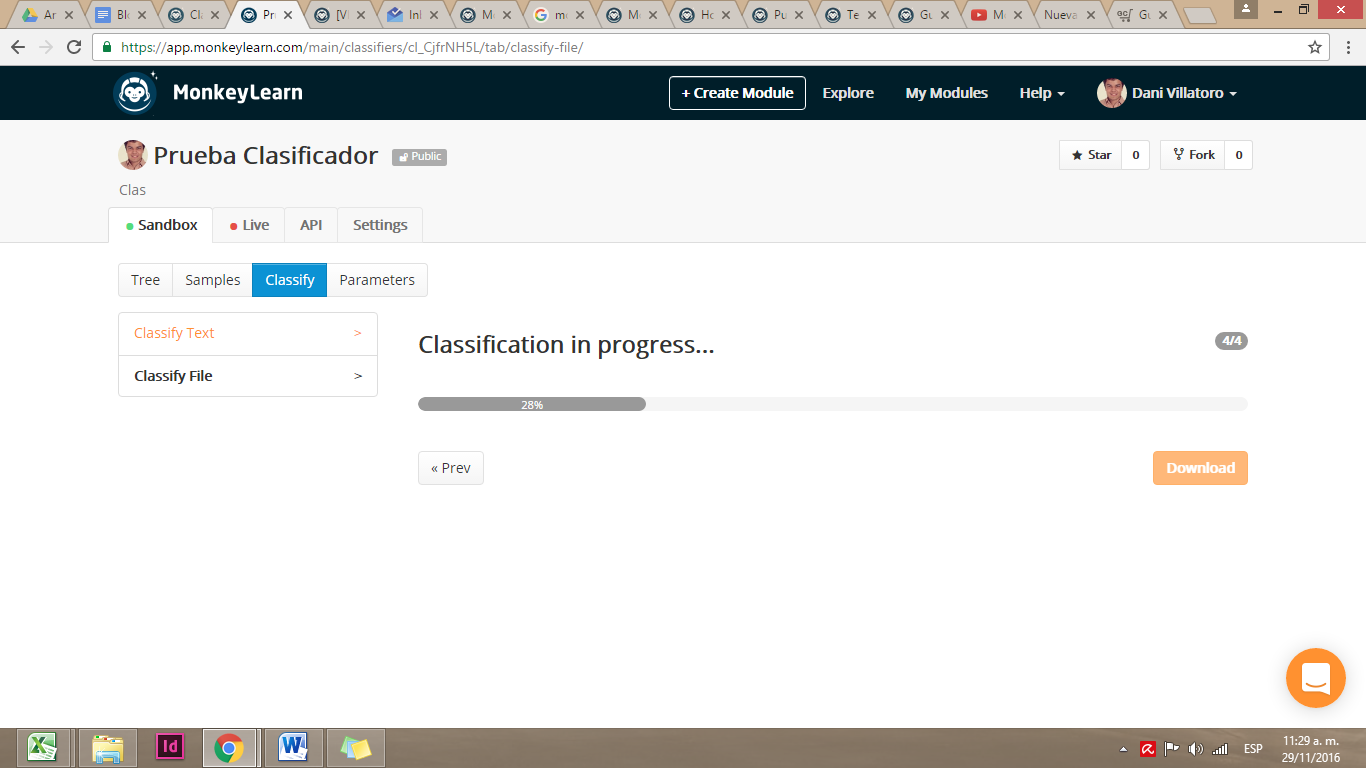
MonkeyLearn aplicará el modelo de clasificación que creamos y devolverá un archivo descargable.
En nuestro ejemplo, utilizamos un set de datos de las adjudicaciones del estado a proveedores. Nuestra base de datos contaba con categorías útiles como la entidad compradora, modalidad, fecha de adjudicación, proveedor y descripción. Sin embargo, las descripciones son texto escrito no categorizado, por lo que buscábamos categorizar esas compras por el tipo de materiales que se compraban.
En el archivo que MonkeyLearn produce se agregan varios elementos. “Classification path” te muestra la categorización que realizó y, si tiene jerarquía, te muestra los diferentes niveles separados por / una barra diagonal. Te muestra también “Level 1 label”, la clasificación que realizó, y “Level 1 probability”, un índice de probabilidad sobre la similitud entre el texto que encontró y los ejemplos que le mostraste.
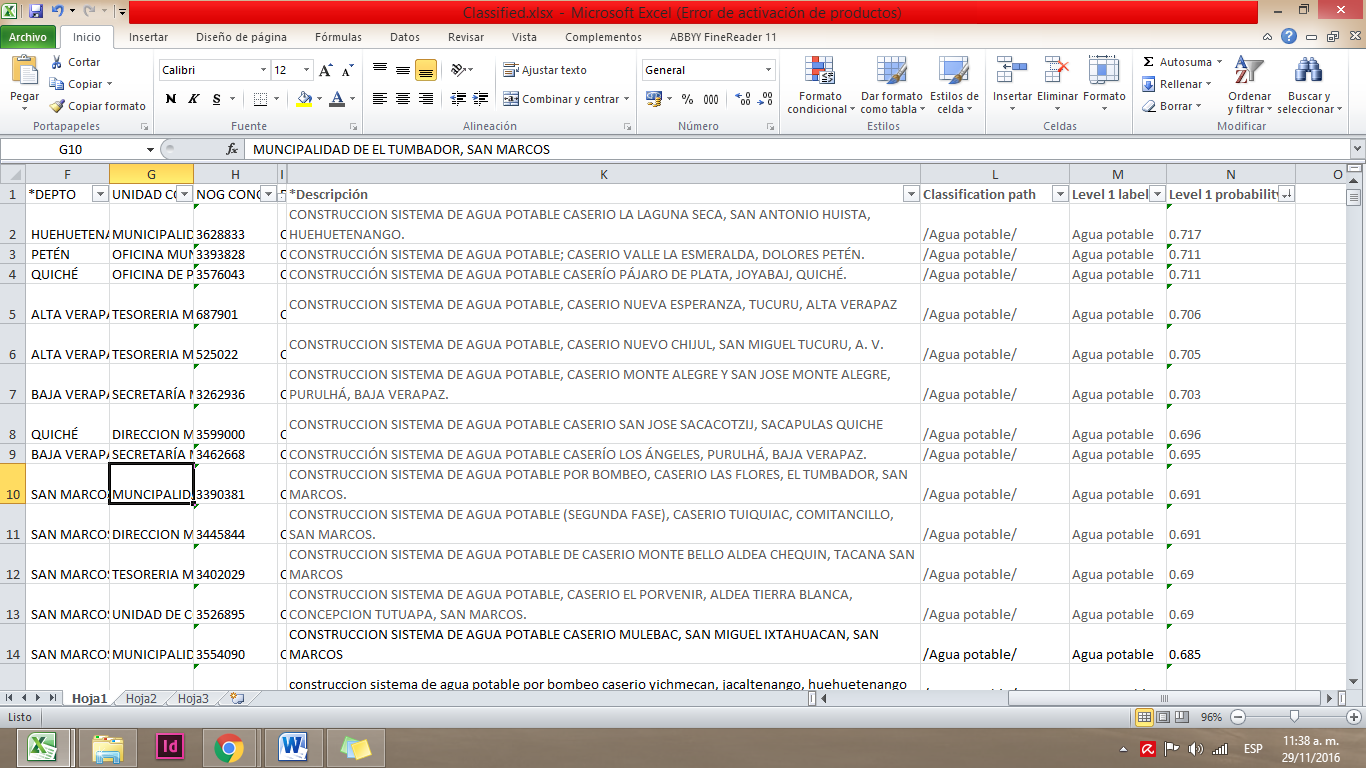
A medida que entrenes más cada categoría, tus resultados serán más certeros. Debido a la cantidad de registros de una base de datos, la clasificación manual sería un proceso muy tardado. Así que cuando tengas estos problemas puedes aplicar el machine learning para clasificar o tematizar bases de datos con texto.
Yo estoy aprendiendo a utilizar esta herramienta, pero si tienes dudas o ejemplos sobre cómo aplicar estas habilidades a un trabajo con datos, tuiteanos a @EscuelaDeDatos y @danyvillatoro. Nos gustaría saber de qué manera has podido aplicar esta herramienta a tu trabajo.
magazine.image = https://es.schoolofdata.org/files/2017/01/image07.png
![]()
Al combinar datos de manera automática te ahorras el tedioso trabajo de tener que emparejar de manera manual dos o varios set de datos.
Al combinar datos de manera automática te ahorras el tedioso trabajo de tener que emparejar de manera manual dos o varios set de datos.
- Instala el programa
Este programa gratuito te permite importar tus datos para crear visualizaciones interactivas. Todo tu trabajo se guarda en tu usuario y se puede compartir a través de códigos embed o iframes. Otra ventaja es que el programa está disponible para los sistemas operativos Windows y Mac. Para descargar la aplicación, entra en este link y sigue las instrucciones que el instalador te señala.
2) Asegúrate de que tus datos compartan un denominador común
Cuando quieres unir bases de datos debes asegurarte de que ambas compartan algún campo que vincule los dos sets de datos. Por ejemplo, si tienes dos set de datos sobre los países de Latinoamérica, tu denominador común puede ser el nombre del país. O si tienes datos sobre denuncias y delitos de los partidos políticos, el denominador común puede ser el nombre o las siglas del partido.
3) Repasa la teoría de los conjuntos
Tableau Public te permite realizar dos tipos de combinaciones.
La primera, es una unión interior.
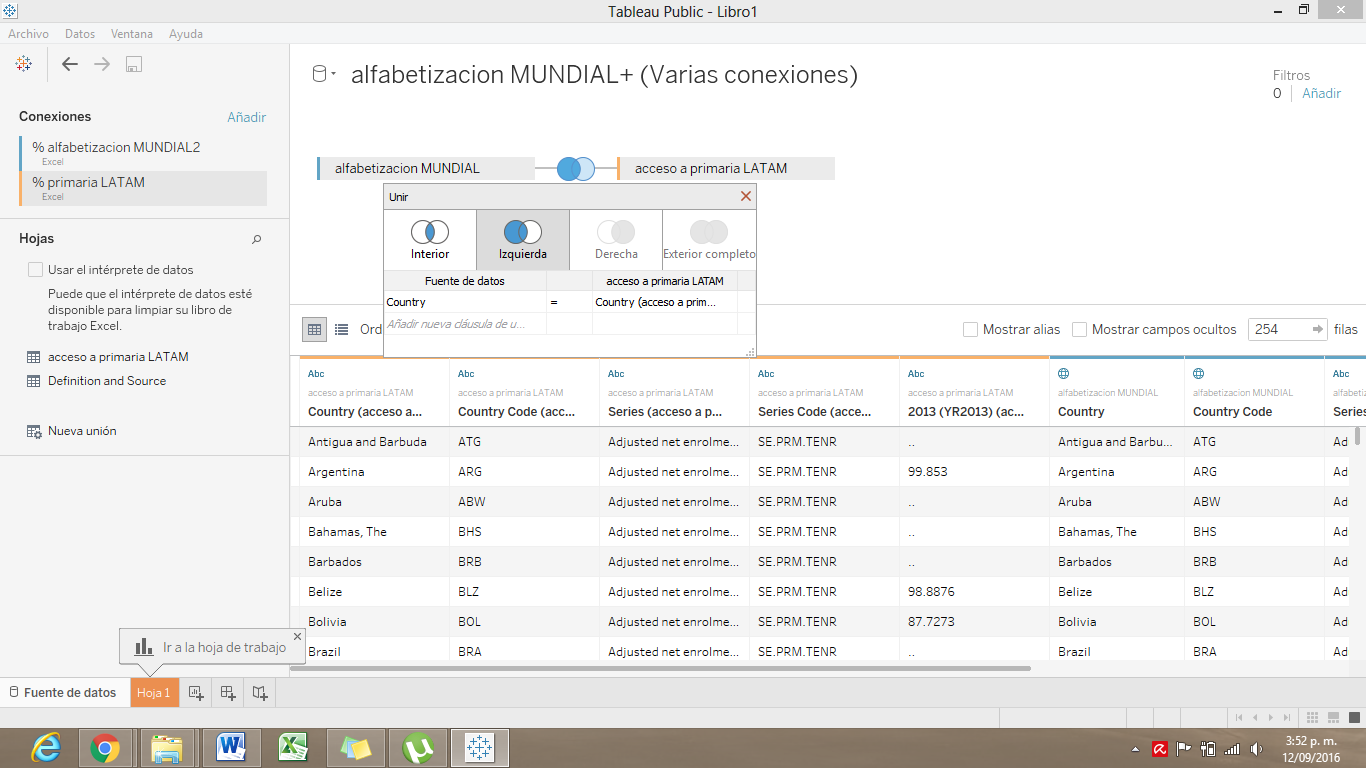
En este tipo de unión, sólo se copiaran los datos en los que el denominador común de ambas fuentes de datos coincida. Por ejemplo, si tenemos un set de datos sobre alfabetización en todos los países del mundo y lo combinamos con datos sobre el acceso a la educación primaria en los países de Latinoamérica, nuestra base de datos combinada solo mostrará los datos de los países de Latinoamérica.
La segunda, es una unión izquierda.
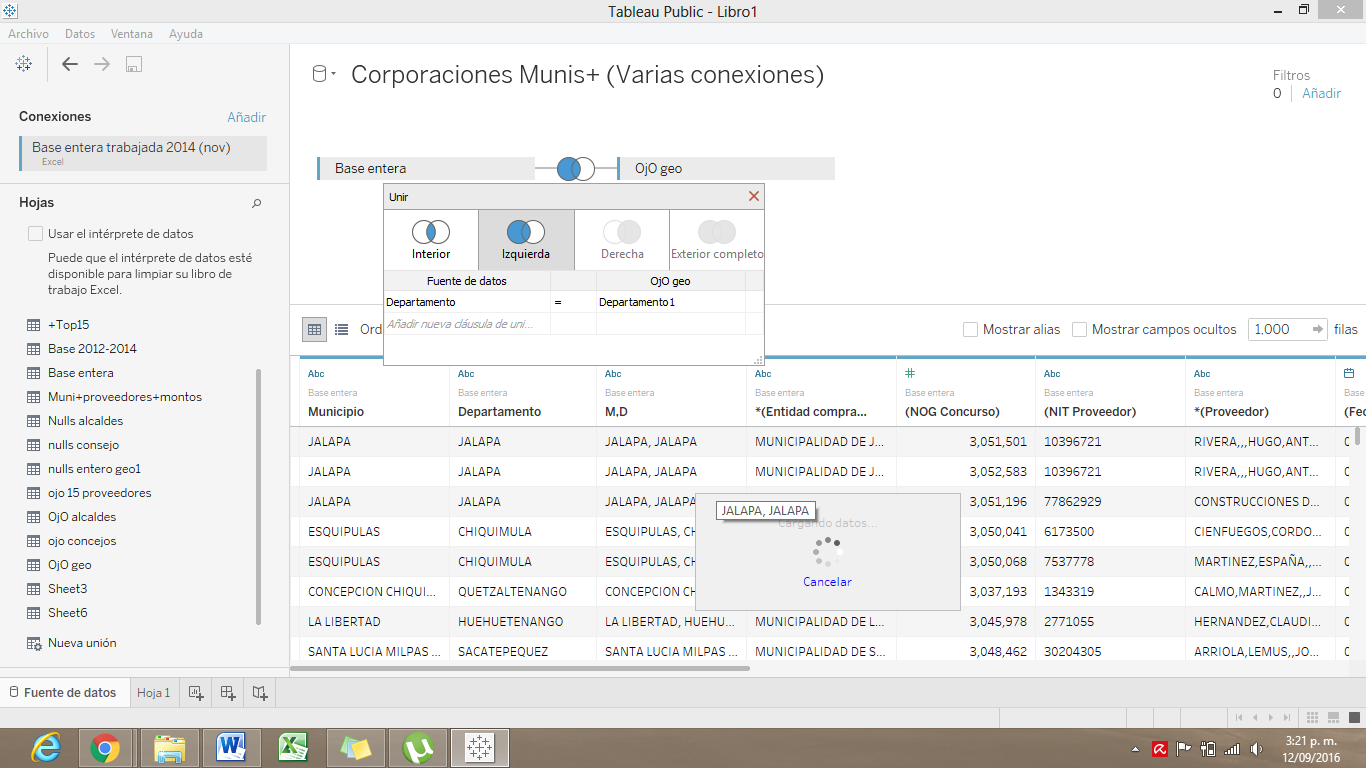
En este tipo de unión, se copiarán todos los datos de tu primera fuente de datos y sólo se agregarán los datos de la segunda fuente cuando estos coincidan en denominador común. Las filas que no tengan coincidencias se mostrarán como valores nulos. Siguiendo nuestro ejemplo, nuestra base de datos combinada mostraría los datos de alfabetización de todos los países del mundo, pero aquellos que no forman parte de Latinoamérica no contarían con datos sobre el acceso a educación primaria.
4) Abre el programa y conecta tu primera fuente de datos
Al iniciar, el programa te invita a conectar a un archivo de base de datos, que puede ser en formatos Excel (xls, xlsx), Archivos de texto (csv) o Access. Selecciona tu primer set de datos. En nuestro ejemplo, sería el archivo con el porcentaje de alfabetización de todos los países del mundo.
5) Añade tu segunda fuente de datos
Haz click en la palabra añadir y agrega una segunda base de datos. En nuestro ejemplo, es el archivo con el porcentaje de acceso a la educación primaria en los países latinoamericanos.
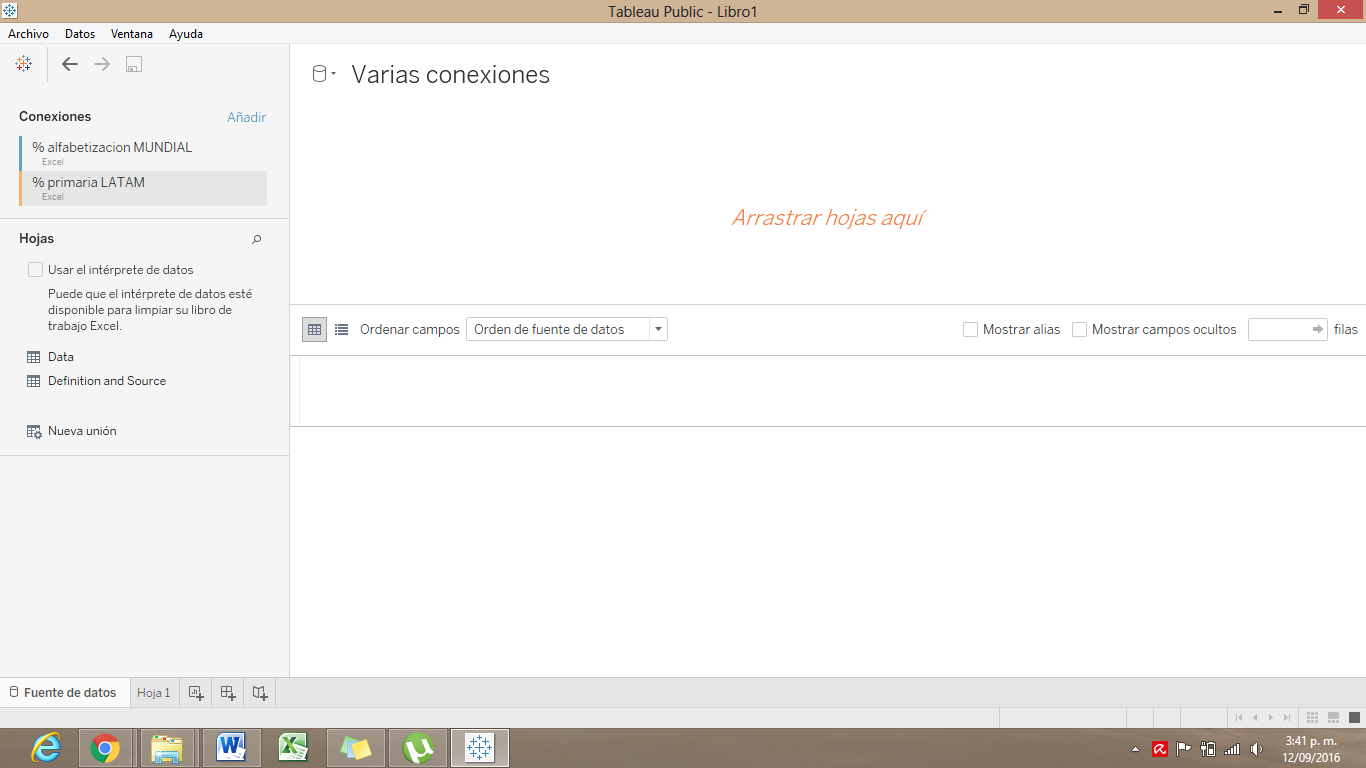
6) Arrastra ambos sets de datos y conéctalos
Al arrastrar las diferentes hojas de cálculo a la pantalla de Tableau Public, el programa te mostrará la relación que estás creando entre ambas bases de datos y te dará una muestra de cómo luce tu conexión de datos.
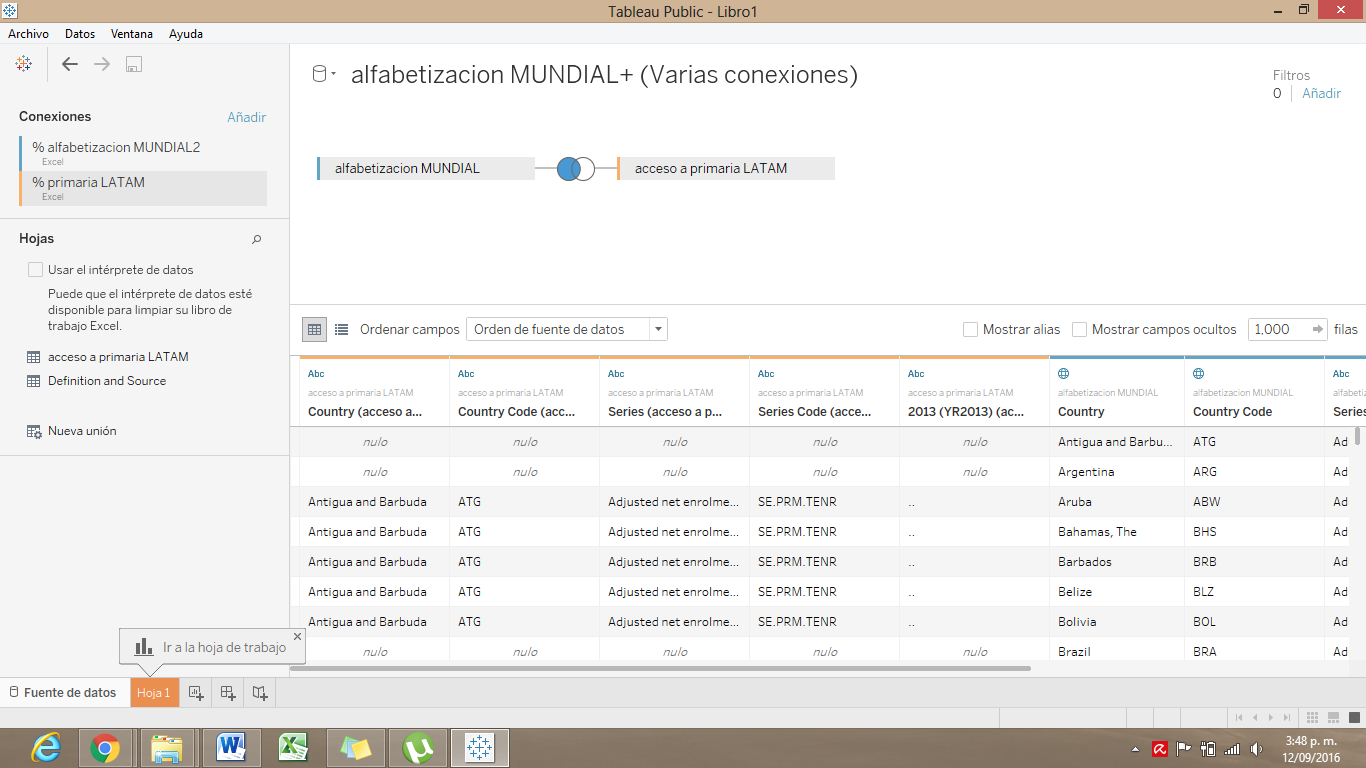
7) Edita la conexión
Haz click en los dos círculos unidos que se muestran entre tus fuentes de datos para abrir una ventana de edición de tu unión. En esta pestaña debes de decidir si quieres una combinación interior o una combinación izquierda. También debes de indicar cuál es la categoría en tus fuentes de datos que coincide o es igual en ambas. En este caso, seleccionamos el campo Country (País) para que combine los datos de cada país de manera automática.
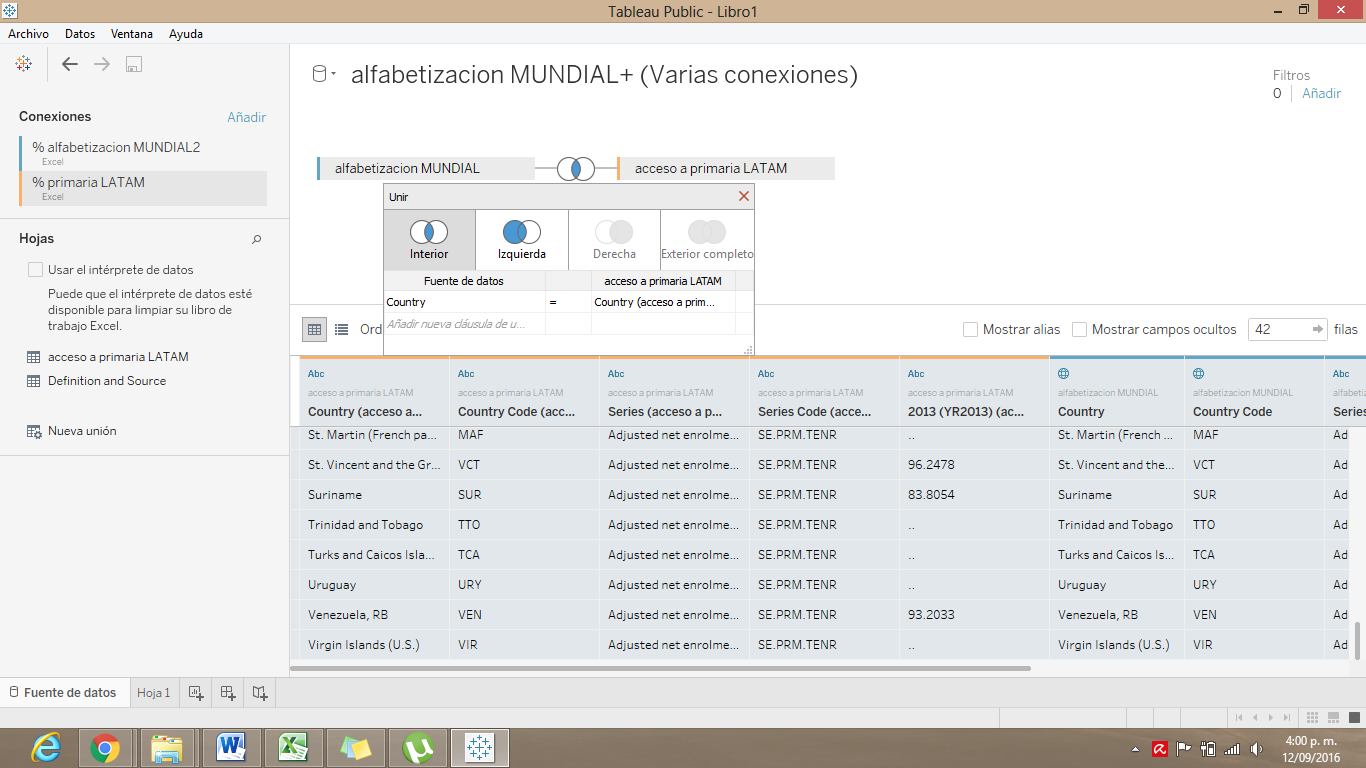
Siguiendo el ejemplo, si decides hacer una conexión interior, la combinación de estas dos bases de datos sólo te mostraria 42 filas con los datos de alfabetización y acceso a educación primaria de los 42 países de Latinoamérica y el Caribe.
En cambio, si eliges una conexión izquierda, el set de datos resultante te mostraría 254 filas con los nombres de todos los países del mundo y sus datos sobre alfabetización, pero los datos sobre acceso a educación primaria solo estarían en los países latinoamericanos. El resto de países tendría un valor nulo en esta categoría.
Durante todo el proceso, Tableau Public te muestra una previsualización de cómo se ve tu set de datos combinado debajo de la sección en la que editas las uniones.
8) Copiar y guardar.
Selecciona todas las filas y columnas de tu base de datos combinada haciendo click en la esquina superior izquierda de la previsualización que te muestra el programa. Copia el contenido con la combinación Ctrl+C o ⌘+C, pégalo en el editor de hojas de cálculo de tu preferencia y guárdalo.
Así, de manera sencilla, puedes combinar bases de datos con muchos campos y sin tener que prestar atención y copiar manualmente las coincidencias. Esta práctica es de mucha utilidad cuando quieres combinar diferentes estadísticas sobre varios lugares, o cuando quieres combinar una base de datos con datos georeferenciales con una que contenga estadísticas.
La combinación izquierda te puede servir para identificar valores que coincidan entre dos bases de datos. Esto es de mucha utilidad cuando estás creando hipótesis para investigaciones o quieres comprobar relaciones entre listados de personas o entidades.
![]()
Ahí estás, sentado frente al monitor de tu pantalla. Las celdas de la mayor base de datos que tu equipo de trabajo consiguió se deslizan frente a tus ojos.
Están llenas de dedazos, entradas diferentes para un mismo nombre, ciudades en nombre completo por un lado y abreviadas por otro… es un desastre.
No tienes conexión a internet, por lo que no puedes usar Open Refine o herramienta por el estilo y, además, no tienes ninguna otra herramienta de datos instalada.
Son sólo tú y una hoja de cálculo en una isla desierta. Estas cuatro fórmulas/funcionalidades podrían salvarte la vida.
 CC por Gibran Mena
CC por Gibran Mena
Filtros
Lo primero que tendrás que hacer es, por supuesto, tener una tabla de datos donde las celdas sean, de hecho, datos.
En este caso usaremos un ejemplo sencillo con los eventos del Open Data Day 2016.
Ve al tab Datos (lo mismo si estás usando hojas de cálculo propietarias como Excel o las más recientes versiones de Calc, de LibreOffice) y da clic en el ícono Filtros.

En cada uno de los nombres de las columnas puedes dar clic en el triángulo, que despliega los elementos enlistados. Selecciona sólo los que quieras ver. Puedes especificar aún más la búsqueda filtrando desde otra columna.
Puedes usar la opción “Filtros de texto” para hacer la búsqueda aún más específica, con la opción, por ejemplo de hacer búsqueda en los elementos de la columna excluyendo una palabra específica o en la opción “Filtros de fecha” que… filtra las fechas.
Para deshacerte de los filtros sólo da clic en “Borrar filtro”
Ordenar


En el mismo submenú de Datos hay un ícono con una flecha descendente llamado Ordenar. Esta función puede resultar útil en caso de ser necesitarse un listado alfabético, numéricamente o descendente. Pero también puedes crear un orden basado en preferencias específicas.
También puedes ordenar de acuerdo con una lista personalizada, por ejemplo si quieres que los datos de Colombia aparezcan primero que los de Bolivia.
Primero debes crear una lista personalizada: digitas en las celdas los valores requeridos en el orden requerido, y en el menú de Preferencias de Excel das clic en Modificar listas personalizadas. Añade la selección.
Luego, en el cuadro de diálogo de Ordenar, es necesario seleccionar la lista personalizada recién creada.
Buscar / Reemplazar
Esta es una función en Excel, es decir que es una fórmula incluida por el paquete por defecto. Las fórmulas y funciones tienen elementos sintácticos (“ortográficos”), estos son paréntesis y comas, y argumentos (los datos a los que se aplican dichas fórmulas). La sintaxis incluye el nombre de la función, los paréntesis, comas que separan las celdas y, finalmente, los argumentos o datos que la fórmula “consume”.
En el caso de Buscar Reemplazar es sencillo hacerlo directamente desde el menú de opciones del programa.
Digamos que queremos encontrar los eventos que se realizan en Ciudad de México. En ubicación tenemos Ciudad de México con acento y Ciudad de Mexico, sin acento, además de DF y Distrito Federal.
La Ciudad de México se llama oficialmente así desde hace muy poco, por lo que este caso seguramente lo encontrarás si trabajas con datos de esta ubicación. No faltará quien le llame Mexico City.

Sólo hay que ir al Menú de Buscar y dar clic en Reemplazar. Para buscar todas las entradas similares a México puedes usar M*xico, que incluye tanto México como Mexico, pero también Maexico o Meexico o Meéxico, que pueden haber sido dedazos a la hora de ingresar la información. Si se quieres buscar solamente un caracter comodín, puedes usar el signo de interrogación, como en M?xico, y si quieres buscar signos como ? o & o @ puedes usar la tilde, en caso de que haya entradas como M?xico, M$xico, M@exico.
Enseguida puedes reemplazar cada valor uno por uno o dar clic en Reemplazar todos. Puedes hacer tantas búsquedas/reemplazos consecutivos como quieras y puedes hacerlo por filas o columnas. Una guía más detallada la encuentras aquí.
BuscarV
La función nos permite introducir un valor específico conocido (locación) para que el programa vaya y busque el dato de una columna que no conocemos (nombre de los organizadores de un evento en Azerbaiyán). Es particularmente útil en matrices masivas con interminables columnas.
La sintaxis o estructura “ortográfica” de la función es la siguiente:
=BUSCARV(«Japan»,B2:E7)
En algunos casos, aunque tengas Excel en inglés se puede usar la fórmula en español. En otros no, y deberás sustituir sólo el nombre de la fórmula por “vlookup”. Esta fórmula se digita en la celda en la que queremos que la matriz escupa el resultado deseado.
Vamos paso a paso.
Lo primero que debes hacer es colocarte en la celda en la que quieres que aparezca lo que buscas.
En mi caso es J5 (y la lista de mi antivirus está actualizada, no tiene nada que ver, pero en la vida eso te da puntos extra).

(Este screenshot es también un recordatorio subliminal de que deben instalar y manterner activo su antivirus)
Eso, J5, es el primer “argumento” que escribo después del nombre de mi fórmula, y entre paréntesis.
=BuscarV(J5)
Después se introduce una coma, seguida por la celda donde empezaré a buscar =BuscarV(J5,A2:
Seguida por dos puntos y la fila y columna de la celda donde pienso terminar la búsqueda (G207, en mi caso).

Puedes también simplemente seleccionar el área donde buscará la función, esto se conoce como rango de búsqueda.
He ahí el poder de una hoja de cálculo para hacer limpieza de datos. Úsalo con sabiduría.
![]()
Hoy en Escuela les presentamos un material generosamente elaborado y compartido por Dennys Mejía, quien de día es diseñador y periodista de datos de Plaza Pública en Guatemala, y miembro de la red de Escuela de Datos de noche. Se trata de un instructivo para introducirnos en el uso de CartoDB.
Dennys usa este material en sus cursos offline, y agradecemos que lo comparta con todos.
Sin más, el documento en Scribd:
Dennys Mejía – Introducción a CartoDB by Escuela de Datos
![]()