Datos y elecciones
Aprovechando que en Guatemala hay elecciones este año, se presentaron proyectos electorales innovadores que usan tecnología y datos. Cada proyecto recolecta y comparte datos abiertos que ayudan a los ciudadanos a votar de manera informada.
Estos fueron los proyectos presentados:
¿Por quién voto? es una plataforma virtual en la que los usuarios llenan un cuestionario que compara sus respuestas con las de los partidos que compiten en la elección. Esto permite que cada usuario identifique primero su propia posición ideológica, pero también qué tan cercana es su postura con la de la oferta política. Además, la plataforma recolecta datos demográficos y de localización de los usuarios que participan en estos cuestionarios. El proyecto busca que estos datos estén accesibles para que analistas puedan identificar futuros proyectos de investigación.
3de3 es un proyecto que demanda transparencia de los candidatos políticos, invitándoles a compartir tres documentos importantes: su declaración fiscal, una declaración de intereses (para prevenir conflictos de interés futuros) y su declaración patrimonial.
La Papeleta es un directorio creado por Guatecambia que convierte los documentos legales de registro de candidatos del Tribunal Supremo Electoral, los cuales son PDFs escaneados. Como resultado, presenta registros transcritos y con datos legibles por máquina.
Rastreando el flujo de dinero público
La fellowship de Escuela de Datos consiste en un proyecto de investigación que mapea el proceso de contrataciones públicas en Guatemala. En relación con los valores de las Contrataciones Abiertas, entender cómo funcionan es un primer paso importante. Por eso, se aprovechó esta reunión con la comunidad local de usuarios de datos abiertos para entender sus necesidades, el nivel de interés que tienen por los datos abiertos sobre contrataciones públicas y las mejores maneras para explicar este proceso y lograr una interacción productiva con estos esfuerzos por la transparencia. Sofía Montenegro, nuestra actual fellow, presentó algunos hallazgos de esta investigación y el proceso.
Ciencia Abierta
Este espacio fue liderado por Kevin Martinez-Folgar, un investigador en epidemiología que brindó una introducción al marco de referencia que indica que los hallazgos científicos sean abiertos, consejos sobre cómo conducir investigación bajo este paradigma y una lista de recursos en línea para aprender y aplicar esta manera de hacer ciencia.
Navegamos por OSF.io para entender cómo ser abiertos en todas las fases del ciclo de investigación científica, ArXiv.org para conocer este servidor y su archivo de artículos científicos y Zenodo para publicar y divulgar hallazgos. También revisamos algunos proyectos en github y aprendimos sobre la identificación de nuestros documentos en el mundo digital a través del Digital Object Identifier System.
Por último, dimos un vistazo por los contenidos disponibles sobre el MOOC (Curso masivo y abierto en línea) de Ciencia Abierta, el OpenScienceMOOC y reflexionamos sobre la poca disponibilidad de conocimiento para las audiencias en español.
—-
Esta actividad fue organizada por Escuela de Datos y su fellowship local en Guatemala, con la ayuda de los entrenadores y los proyectos que presentaron su trabajo.
![]()
Como todos los años, esperamos que este año podamos crear espacios para líderes locales y para que más organizaciones se involucren en nuevos y emocionantes retos a la hora de usar los datos.
Luego de revisar cientos de postulaciones alrededor del mundo nuestro equipo se entrevistó con personas con trabajo increíble y potencial. Luego de este proceso no tenemos dudas de que esta generación de fellows logrará proyectos innovadores en sus respectivos espacios.
Te presentamos a la generación 2018 de fellows de Escuela de Datos:
Sofía Montenegro – Guatemala
@smontenegrom

Sofía es una enamorada de la naturaleza y las enseñanzas que esconde. Se ha dedicado a la investigación y las ciencias sociales. Es una politóloga egresada de la Universidad Francisco Marroquín y en 2017 obtuvo un Máster en Opinión Pública y Comportamiento Político en la Universidad de Essex. En este último espacio reforzó su interés por la aplicación de metodologías de datos para la investigación de temas sociales. Le interesa la academia en la manera en que es puesta en acción política y abrir camino para nuevas generaciones de mujeres que participen sin restricciones en el mundo de los datos y la política. A la hora de pensar en datos, le interesa el análisis de redes sociales, la corrupción como fenómeno, los procesos electorales y las diferentes metodologías de investigación.

Pamela Gonzáles – Bolivia
@10PAMELA20
Pamela Gonzáles es una apasionada por la visualización de datos y reducir le brecha digital para las mujeres. Cofundó Bolivia Tech Hub, un espacio colaborativo de proyectos de tecnología que buscan contribuir a que en Bolivia prospere un ecosistema innovador. Es también la embajadora regional de Technovation, un programa basado en San Francisco que busca formar a niñas alrededor del mundo con habilidades para usar la tecnología, emprender y liderar. Se graduó de Licenciada en Ciencias de la Computación en la Universidad Mayor de San Andrés.

Odanga Madung – Kenia
Es el cofundador de Odipo Dev, una firma de ciencia de datos y analíticas que opera en Nairobi brindando servicios a compañías de tecnología y organizaciones sociales. Su mayor interés se encuentra en la intersección entre los datos y la cultura: a través de su trabajo ha podido visualizar y analizar actividades de sus clientes y eventos en Kenia y en el mundo. Su trabajo ha sido parte de artículos en Adweek, Yahoo, BBC, Quartz y Daily Nation, por mencionar algunos. Trabajará en el programa de Open Contracting en Kenia.
Nzumi Malendeja – Tanzania

Trabaja como investigador asociado en una firma independiente de evaluación de BRAC International en Tanzania, donde lidera proyectos de agricultura, salud y educación. Desarrolla plataformas de recolección de datos a través de móviles (como ODK collect y SurveyCTO) las cuales reemplazaron los métodos tradicionales basados en papel. Antes, trabajó como monitor de campo y asistente de investigación en el proyecto de educación SoChaGlobal y Maarifa ni Ufunguo, sobre transparencia en construcción. Estudió en la Escuela de Verano de Métodos de Investigación de la Universidad de Ciencias Aplicadas de Alemania y trabaja en su tesis de la Maestría de Investigación y Políticas Públicas en la Universidad de Dar Es Salaam.
Elias Mwakilama – Malawi

Es profesor en la Universidad de Malawi y coordina los programas de investigación, seminario y estadísticas en el departamento de Matemáticas. Elias estudió matemática aplicada y computacional en operaciones, y tiene un máster en ciencias ma
temáticas. Sus intereses en investigación radican en trabajar con modelos de optimización usando técnicas estadísticas integradas con habilidades en computación
para resolver problemas industriales en la práctica y la teoría. Durante su fellowship espera trabajar con la plataforma de contrataciones públicas para organizaciones sociales en Malawi, junto a Hivos.

Ben Hur Pintor – Filipinas
Es un activista por los datos abiertos y la tecnología open-source que cree que la democratización no solo implica abrir el acceso a datos, sino también su uso y análisis. Es un desarrollador de software con habilidades en datos geoespaciales que ha trabajado en proyectos relacionados a energías renovables y mapeos de riesgo participativos. Actualmente está estudiando un Máster en Ingeniería Geomática en la Universidad de Filipinas. Como parte de Free and Open Source Software (FOSS), es miembro activo de las comunidades de FOSS4G Filipinas y MaptimeDiliman — medios para compartir tecnologías de acceso libre.
 Hani Rosidaini – Indonesia
Hani Rosidaini – Indonesia
Le apasiona cómo la tecnología puede ser adoptada y aplicada a las necesidades de las personas. En su trabajo, combina sus habilidades tecnicas en sistemas de información y ciencia de datos, con su conocimiento sobre los negocios y lo social para ayudar a compañías y organizaciones en Indonesia, Australia y Japón. Hani tiene experiencia como especialista en datos para políticas públicas en la oficina presidencial de Indonesia, en donde analizó la plataforma de integración de datos nacional data.go.id y contribuyó a la generación de políticas públicas basadas en datos, promoviendo su uso en ministerios y agencias, así como en comunidades cívicas y locales.
Un año más de trabajo en equipo
El programa de Fellowships es un proceso complejo en el cual contamos con la ayuda de aliados, socios y financistas diversos que hacen posible este esfuerzo en tantos países. La generación 2018 de fellows de Escuela de Datos es posible gracias al apoyo de Hivos, el Banco Interamericano para el Desarrollo (BID), la Fundación Avina y la Iniciativa Latinoamericana de Datos Abiertos (ILDA) en Latinoamérica. El programa de School of Data cuenta también con el apoyo del programa de Open Contracting de Hivos Internacional.
![]()
A partir de un set de datos (que puede ser .csv, o .xls) puedes entrenar esta API para que trabaje para ti. En la interfaz web de MonkeyLearn puedes ir probando y entrenando para aplicar un modelo. Debido a que es una API, esta plataforma es integrable con otros lenguajes de programación que te permitirán procesar los textos de tu fuente de datos a tiempo real y publicarlos.
Una de las ventajas de esta plataforma es que no tienes que ser programador o un experto en Machine Learning para empezar a usarla. La interfaz de usuario te irá dando pasos que deberás seguir para crear un modelo y cuando entiendas la manera en que funciona, podrás ir avanzando en su uso.
Esta herramienta aprende a base de clasificadores de texto, una categoría o etiqueta que se asigna automáticamente a una pieza de texto. Aunque el programa ya cuenta con unos clasificadores comunes, puedes crear los propios.
Con base en estas etiquetas, MonkeyLearn hará una clasificación al leer el contenido de tu set de datos. Por ejemplo, en una base de datos sobre proyectos de compras de una institución pública, esta herramienta te podría ayudar a reconocer los rubros de los fondos, o a clasificar qué tipo de productos se compraron y clasificarlos en base a una jerarquía establecida.
Al leer el texto, MonkeyLearn aplica los parámetros establecidos en los clasificadores de texto y te provee un resultado. El resultado se muestra en lenguaje JSON, para la API. La categorización del producto puede ser en varias categorías, por ejemplo Compras / Materiales de construcción / Asfalto. Aparte de esta clasificación, el programa también te provee un valor de probabilidad, el cual determina el nivel de certidumbre sobre la predicción realizada para que puedas mantener control sobre el rigor con el que tu modelo se aplica y la manera en que funciona.
Los módulos
Esta herramienta te permite tres funciones principales que indican el tipo de módulo que creas:
- Clasificación: Es un módulo que toma el texto y lo devuelve con etiquetas o categorías organizadas en algún tipo de jerarquía
- Extracción: Es el módulo que extrae ciertos datos dentro de un texto, que pueden ser entidades, nombres, direcciones, palabras clave, etc.
- Pipeline: Es el módulo que combina otros módulos, tanto de clasificación como de extracción, para que puedas construir un modelo más robusto con mayor nivel de procesamiento.
Las tres funciones principales de esta plataforma son:
- Análisis de sentimientos: Te permite detectar sentimientos (positivos, negativos, etc) en un texto a través de machine learning.
- Categorización de temas: Identifica el tema de un texto y lo reconoce.
- Otras clasificaciones: Clasifica los contenidos de un texto y los asigna a una jerarquía.
Tutorial: Cómo crear un clasificador de textos a partir de una descripción
Para probar esta herramienta, vamos a crear un clasificador que lea un texto y lo asigne a una categoría y jerarquía establecida por nosotros. En este caso, trabajaré con los datos de las compras del estado de Guatemala. Aunque mi set de datos contiene mucha información, voy a trabajar solo con el campo “Descripción” que tiene contenidos como este: INTRODUCCION DE ENERGIA ELECTRICA, CASERIO PENIEL, TUCURU, A. V.
Para utilizar MonkeyLearn debes crear un usuario o vincularlo a tu cuenta de Github.
Al hacer click en +Create Module se te desplegarán las opciones para guardar tu primer clasificador.
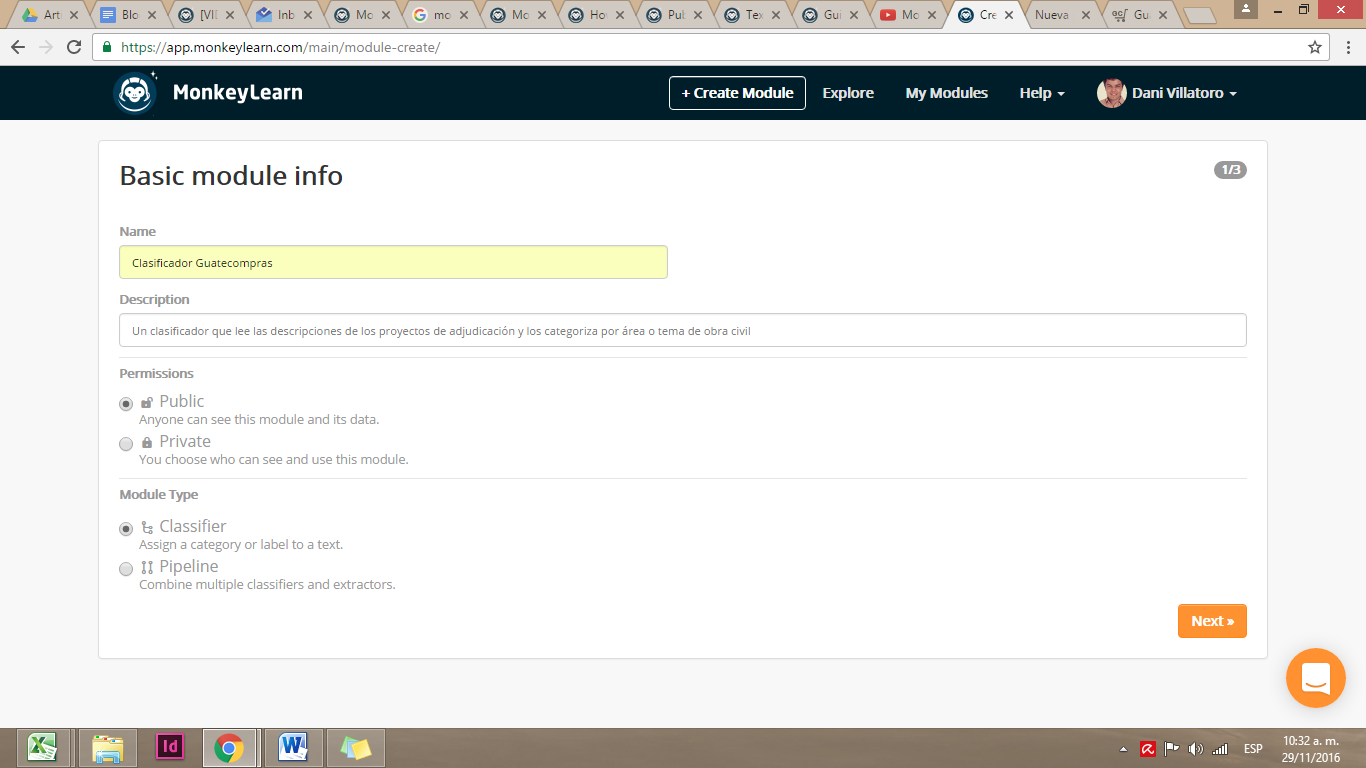
MonkeyLearn te va guiando paso a paso para que completes la información necesaria para crear un módulo. Al rellenar los datos de tu clasificador, da click en Next.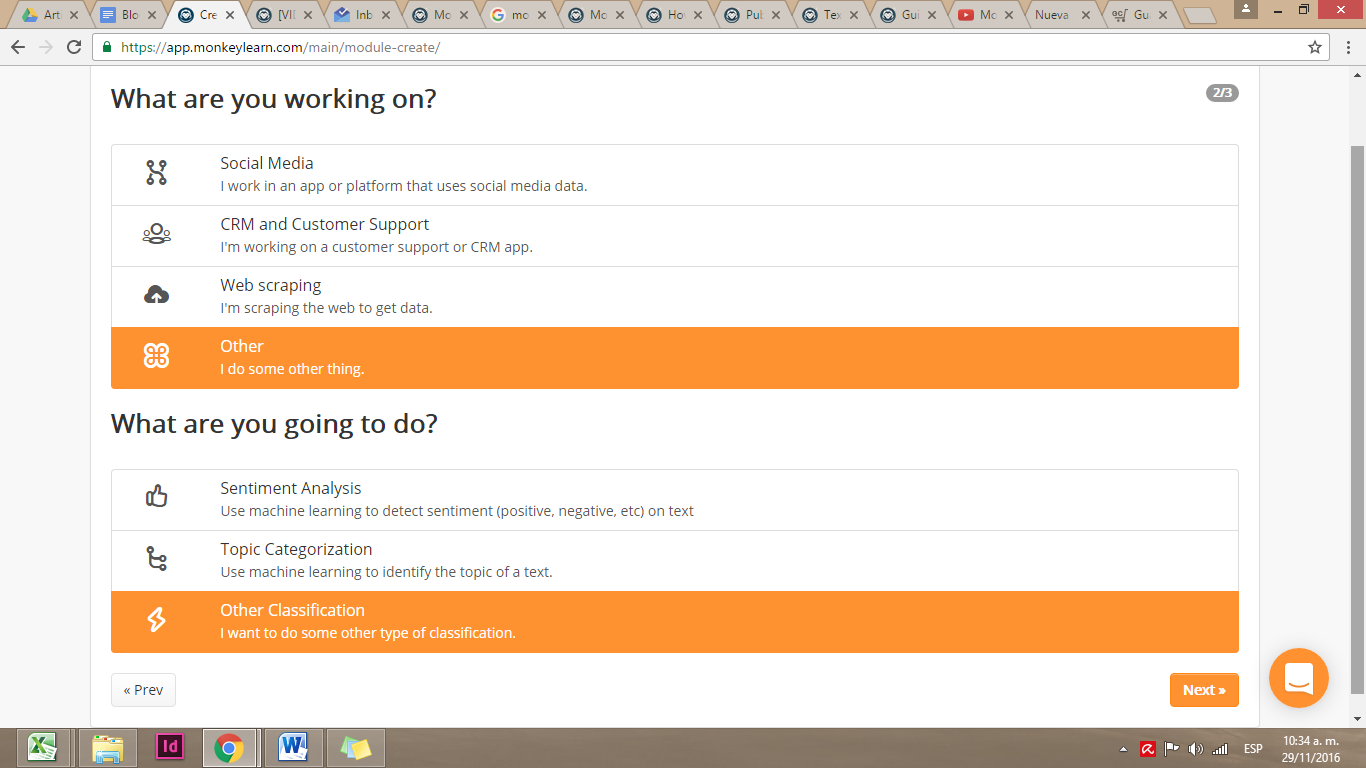
Responde a las preguntas que te hace sobre el tipo de trabajo que estás haciendo. En este caso, seleccionamos “otras clasificaciones”.
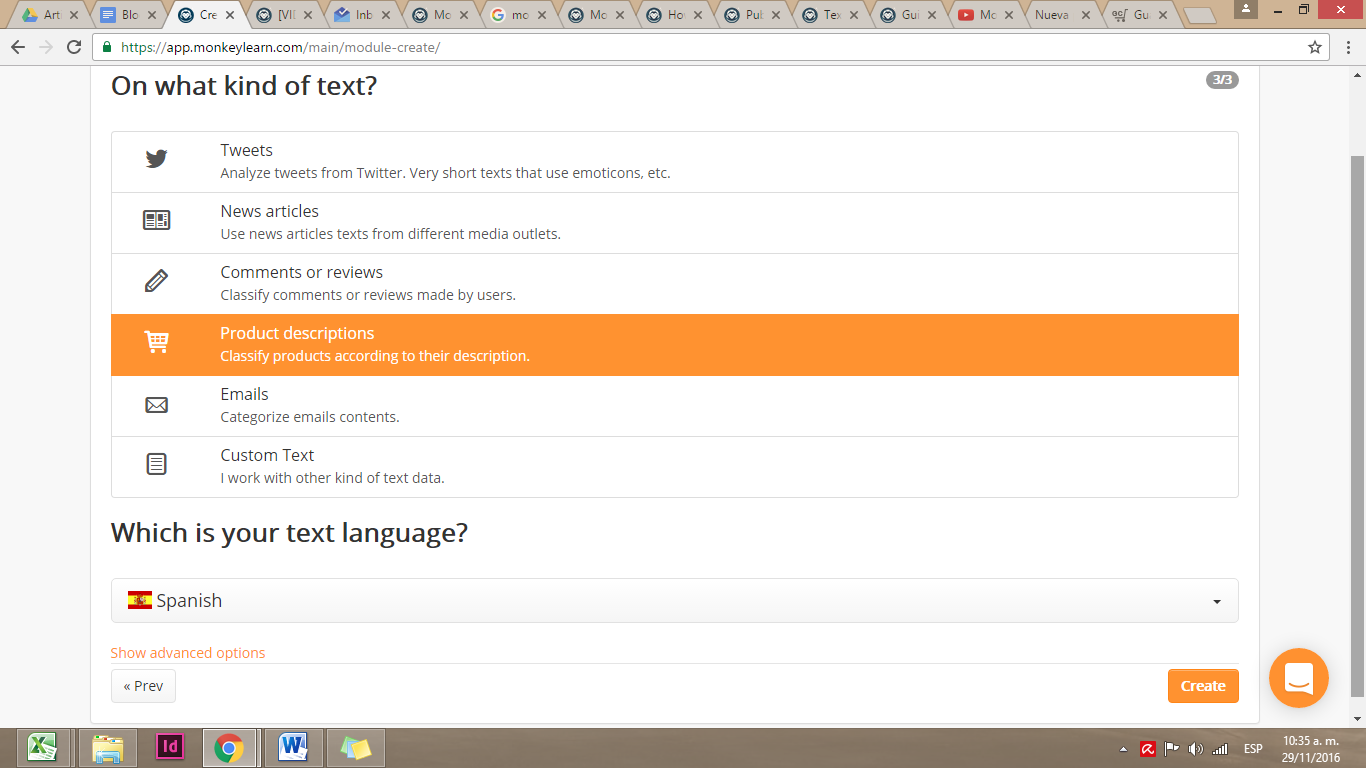
Selecciona la opción que más se ajuste al tipo de texto que vas a analizar, pueden ser tweets (textos cortos con emoticones), noticias de diferentes medios, comentarios o reseñas de usuarios, descripciones de productos, emails, o texto personalizado. Debido a que estamos trabajando las compras del estado, vamos a seleccionar Product Descriptions. También es importante que señales el idioma en que está tu texto.
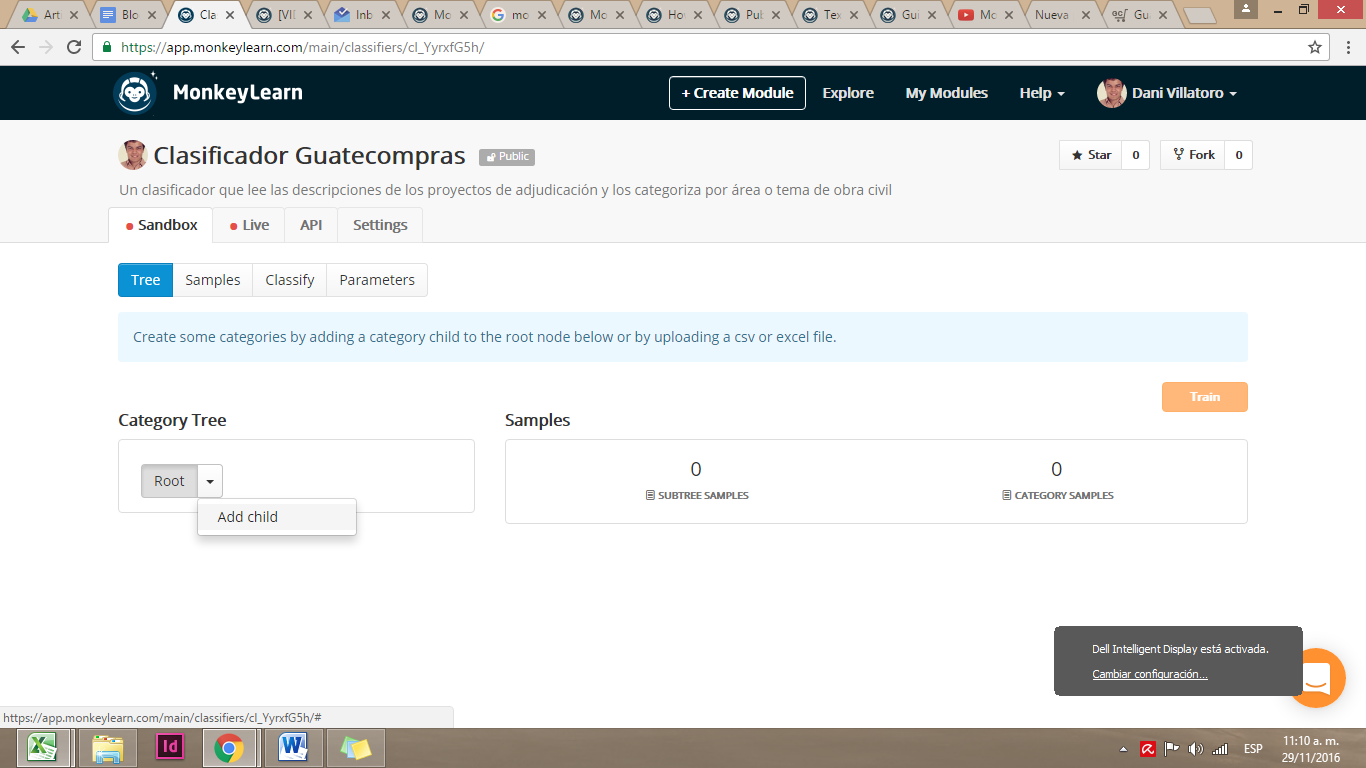
Al crear tu módulo, se abrirá un panel con diferentes opciones. En Category Tree se enlistan las diferentes categorías de tu modelo. Para crear nuevas categorías, haz click en el menú a la par de Root y selecciona Add child. Al hacer esto, creas nuevas categorías “hijas”. En este caso crearemos “Agua potable” “Caminos y carreteras” “Energía eléctrica” “Agricultura” y cuantas secciones queramos tener. MonkeyLearn también permite añadir subcategorías dentro de las categorías.
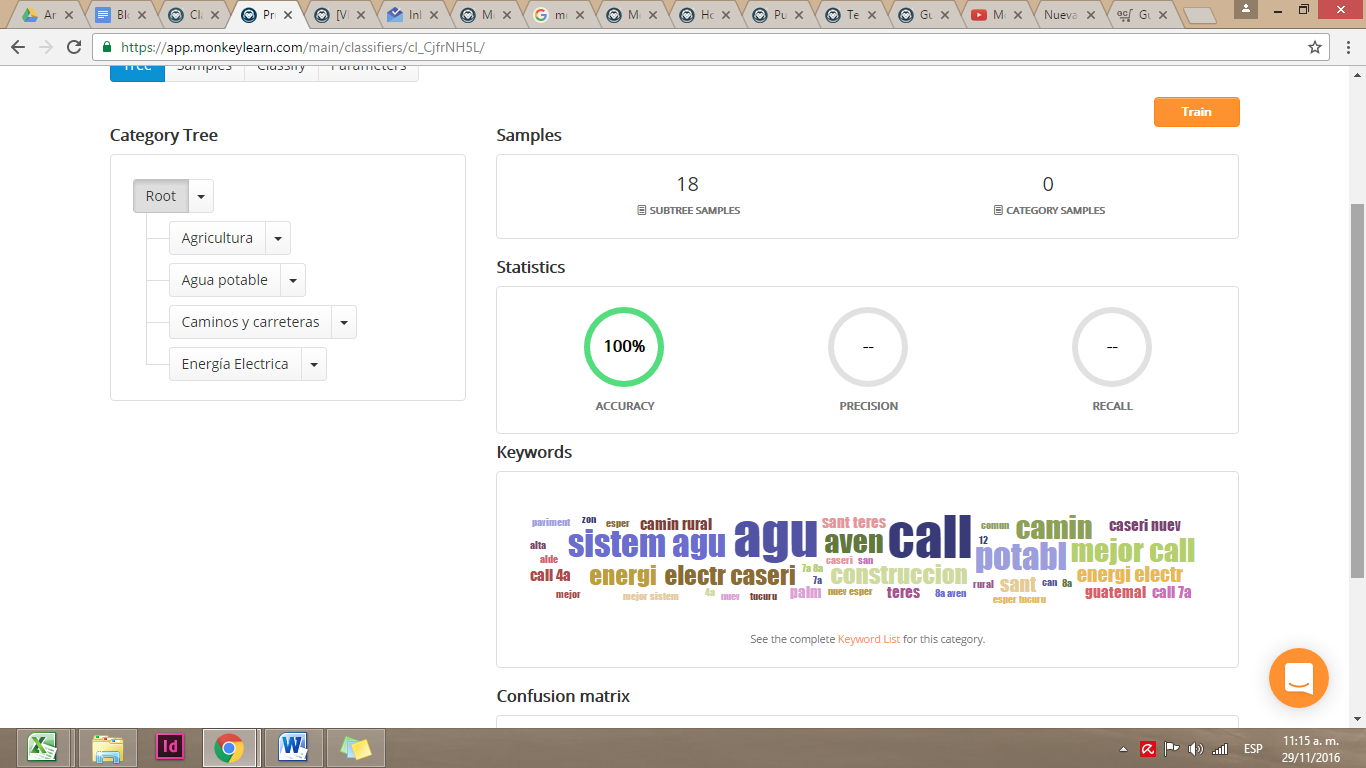
Para que nuestro modelo funcione, debemos entrenar cada categoría con ejemplos que le permitirán al programa reconocer automáticamente textos similares a los ejemplos que le dimos. Al hacer click en el menú desplegable a la par de cada categoría se muestra la opción Create sample, que te permite ingresar ejemplos.
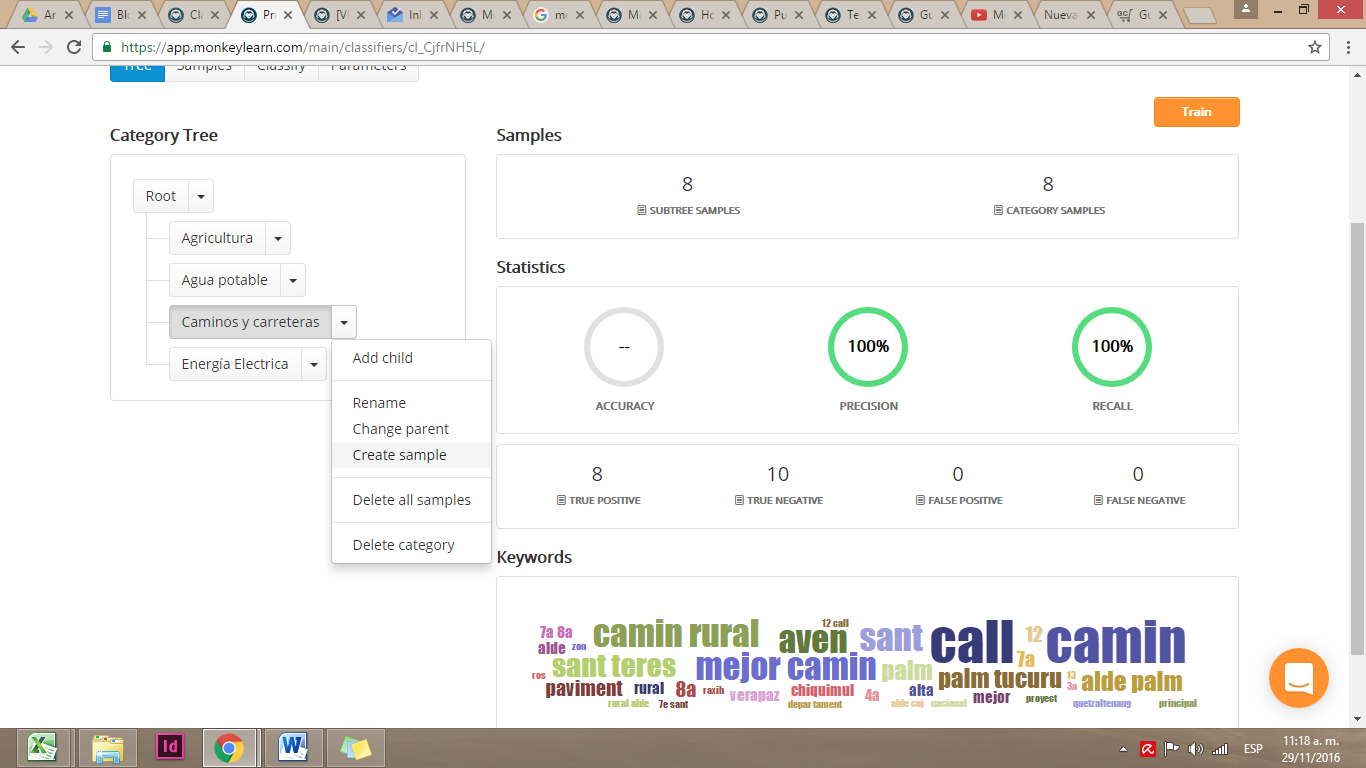
Para entrenar la categoría “Caminos y carreteras” vamos a añadir cuantos ejemplos podamos de descripciones que se ajusten a esta sección. Por ejemplo, “MEJORAMIENTO CALLE PAVIMENTADO Y ENCUNETADO…”. El agregar muchos ejemplos robustece la capacidad de que nuestro modelo identifique con mayor celeridad las categorías.
El panel principal de MonkeyLearn muestra las categorías en la sección Tree. Al hacer click en Samples, podemos ver los ejemplos que añadimos para cada categoría.
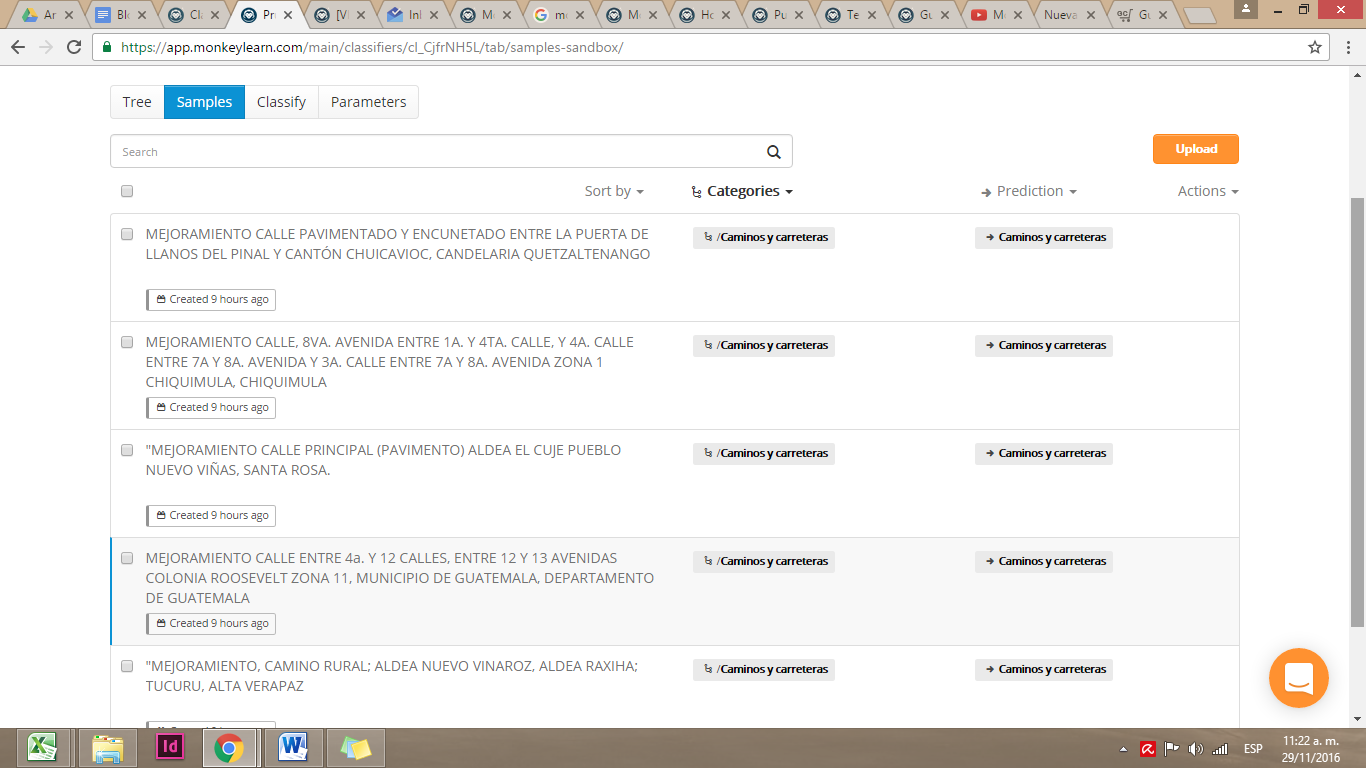
Luego de añadir varios ejemplos a todas nuestras categorías, dejamos que las capacidades de machine learning se ajusten al hacer click en Train
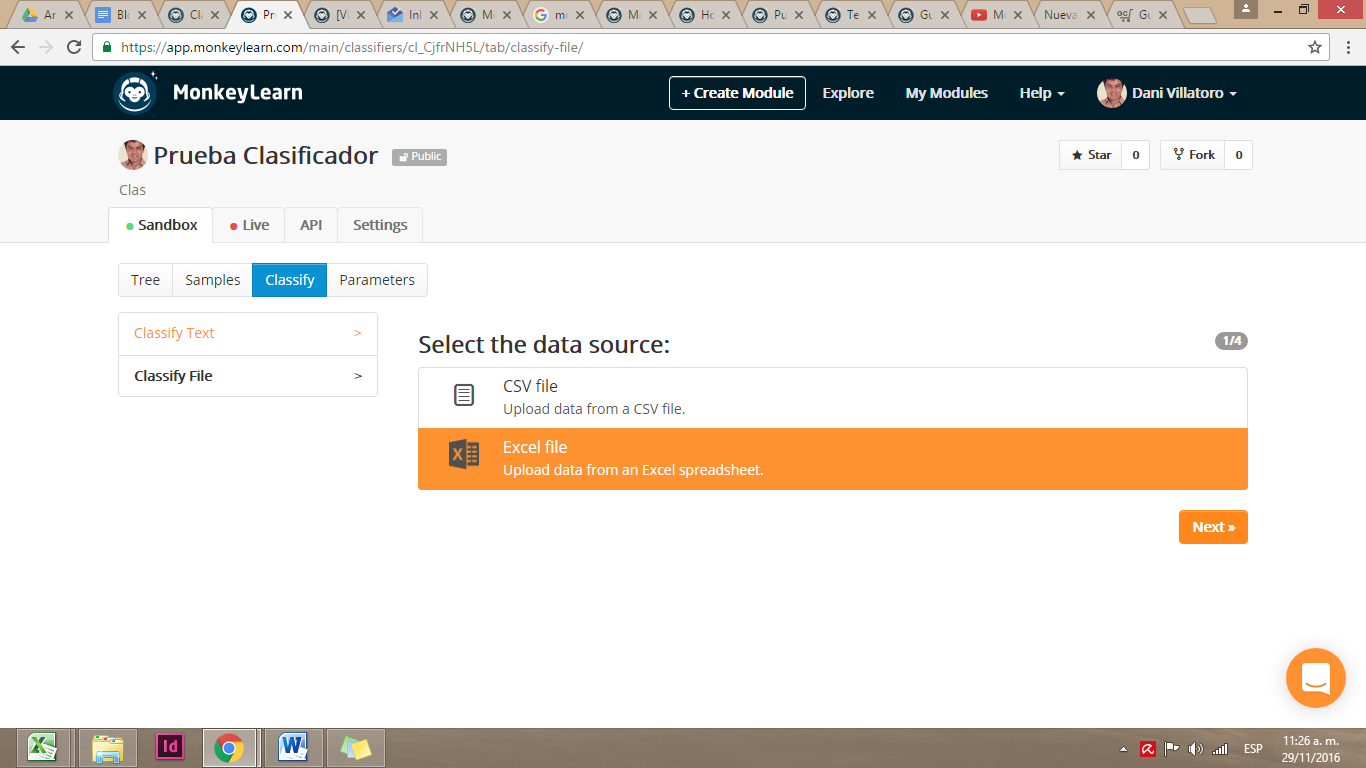
Con nuestro modelo ya entrenado, nos vamos a la secció Classify para aplicar este modelo a un set de datos. La fuente de datos puede ser un texto corrido o un archivo csv o xls.
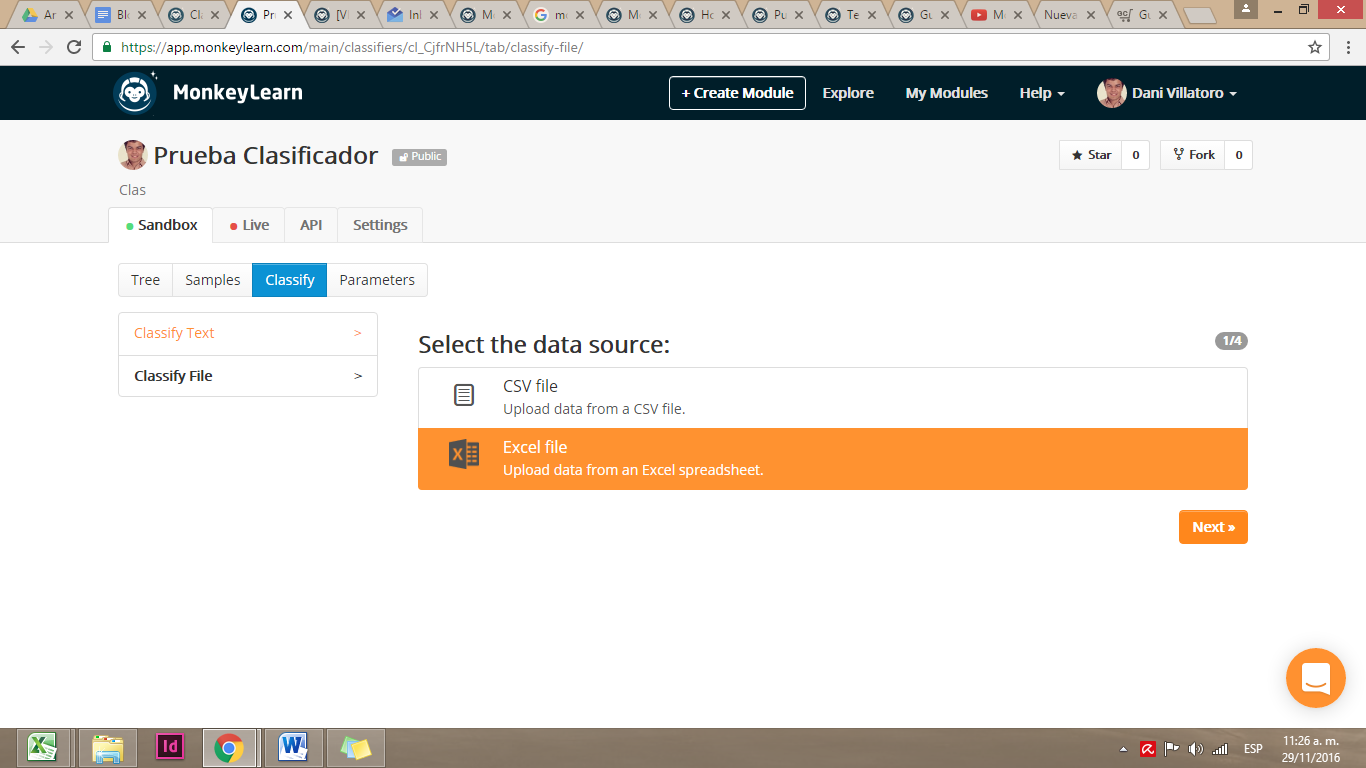
Seleccionamos nuestro archivo y nos presenta una muestra de nuestro set de datos y nos pregunta qué columna es la que vamos a analizar. Para seleccionar nuestra columna debemos marcar la opción Use as text que se muestra en la primera fila. Y para aplicar el modelo pulsamos Next.
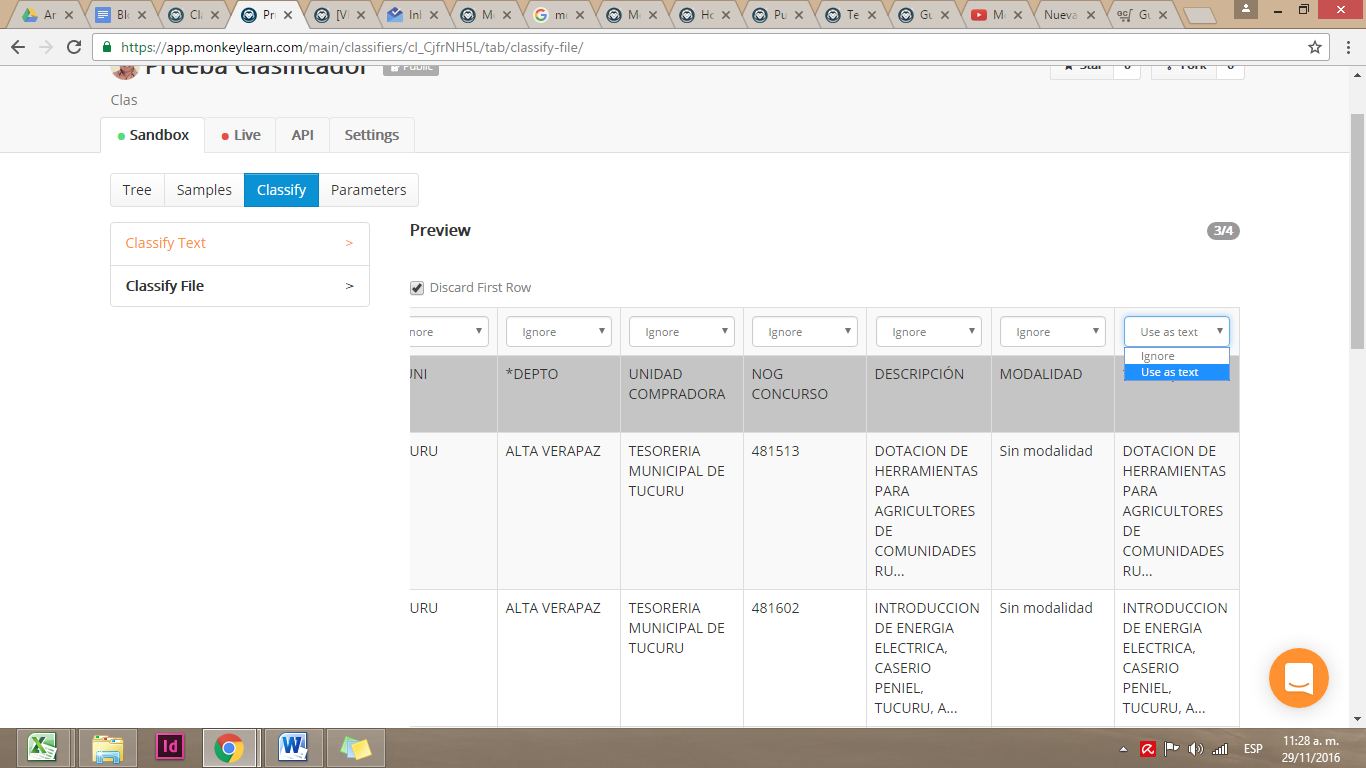
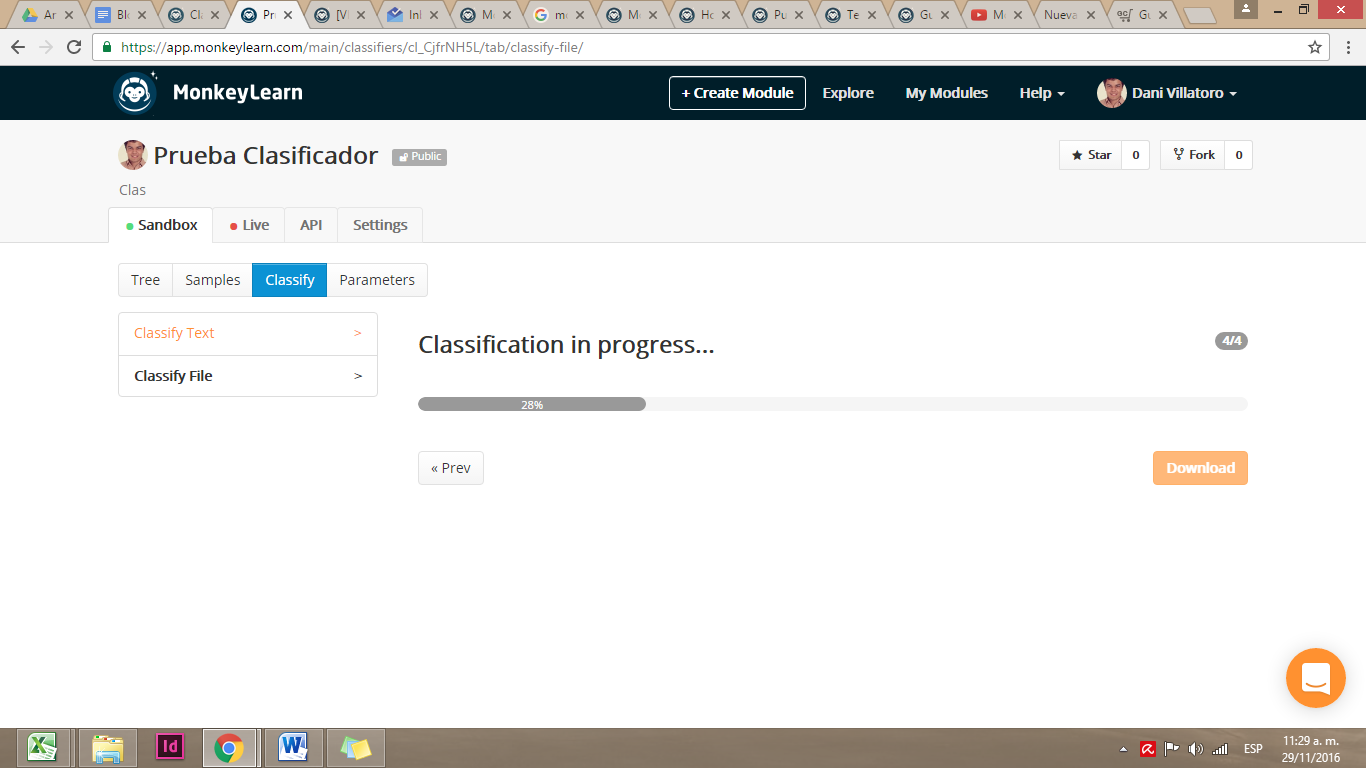
MonkeyLearn aplicará el modelo de clasificación que creamos y devolverá un archivo descargable.
En nuestro ejemplo, utilizamos un set de datos de las adjudicaciones del estado a proveedores. Nuestra base de datos contaba con categorías útiles como la entidad compradora, modalidad, fecha de adjudicación, proveedor y descripción. Sin embargo, las descripciones son texto escrito no categorizado, por lo que buscábamos categorizar esas compras por el tipo de materiales que se compraban.
En el archivo que MonkeyLearn produce se agregan varios elementos. “Classification path” te muestra la categorización que realizó y, si tiene jerarquía, te muestra los diferentes niveles separados por / una barra diagonal. Te muestra también “Level 1 label”, la clasificación que realizó, y “Level 1 probability”, un índice de probabilidad sobre la similitud entre el texto que encontró y los ejemplos que le mostraste.
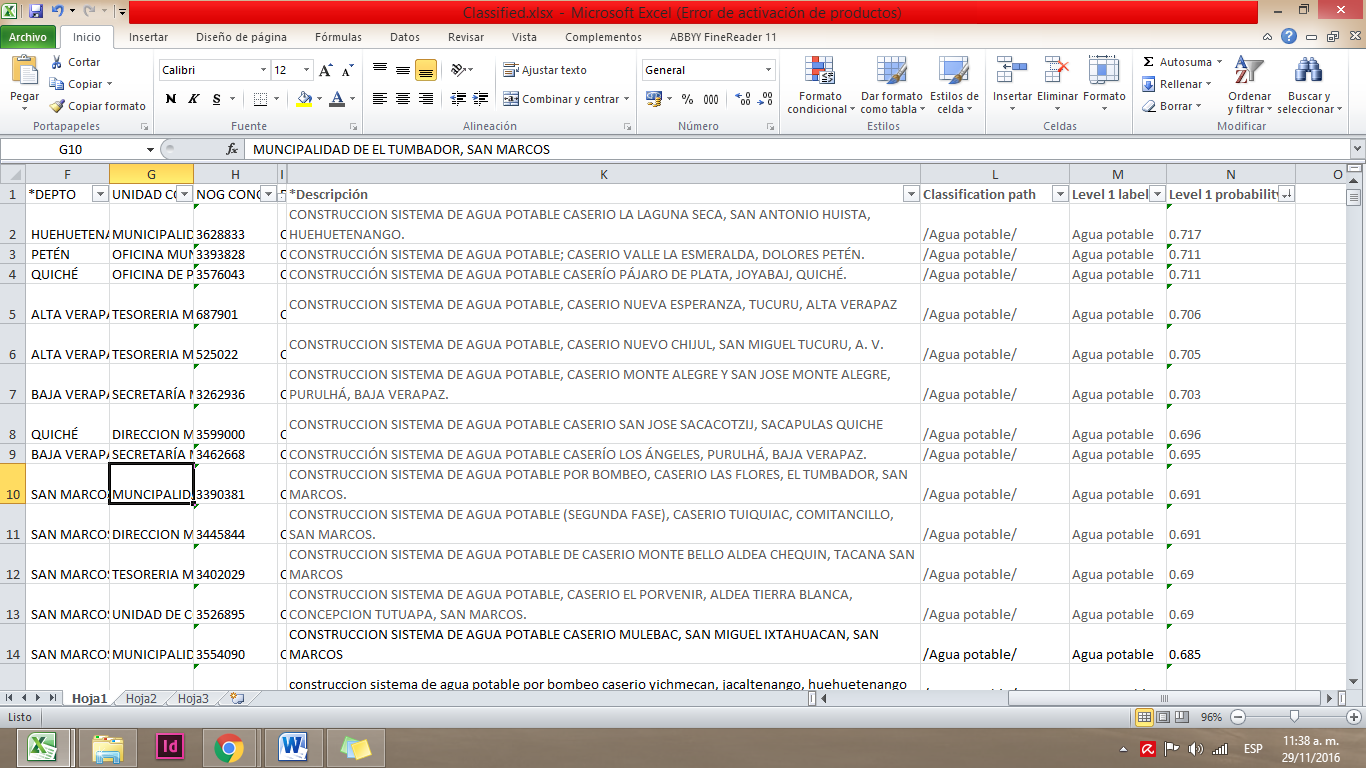
A medida que entrenes más cada categoría, tus resultados serán más certeros. Debido a la cantidad de registros de una base de datos, la clasificación manual sería un proceso muy tardado. Así que cuando tengas estos problemas puedes aplicar el machine learning para clasificar o tematizar bases de datos con texto.
Yo estoy aprendiendo a utilizar esta herramienta, pero si tienes dudas o ejemplos sobre cómo aplicar estas habilidades a un trabajo con datos, tuiteanos a @EscuelaDeDatos y @danyvillatoro. Nos gustaría saber de qué manera has podido aplicar esta herramienta a tu trabajo.
magazine.image = https://es.schoolofdata.org/files/2017/01/image07.png
![]()
Al combinar datos de manera automática te ahorras el tedioso trabajo de tener que emparejar de manera manual dos o varios set de datos.
Al combinar datos de manera automática te ahorras el tedioso trabajo de tener que emparejar de manera manual dos o varios set de datos.
- Instala el programa
Este programa gratuito te permite importar tus datos para crear visualizaciones interactivas. Todo tu trabajo se guarda en tu usuario y se puede compartir a través de códigos embed o iframes. Otra ventaja es que el programa está disponible para los sistemas operativos Windows y Mac. Para descargar la aplicación, entra en este link y sigue las instrucciones que el instalador te señala.
2) Asegúrate de que tus datos compartan un denominador común
Cuando quieres unir bases de datos debes asegurarte de que ambas compartan algún campo que vincule los dos sets de datos. Por ejemplo, si tienes dos set de datos sobre los países de Latinoamérica, tu denominador común puede ser el nombre del país. O si tienes datos sobre denuncias y delitos de los partidos políticos, el denominador común puede ser el nombre o las siglas del partido.
3) Repasa la teoría de los conjuntos
Tableau Public te permite realizar dos tipos de combinaciones.
La primera, es una unión interior.
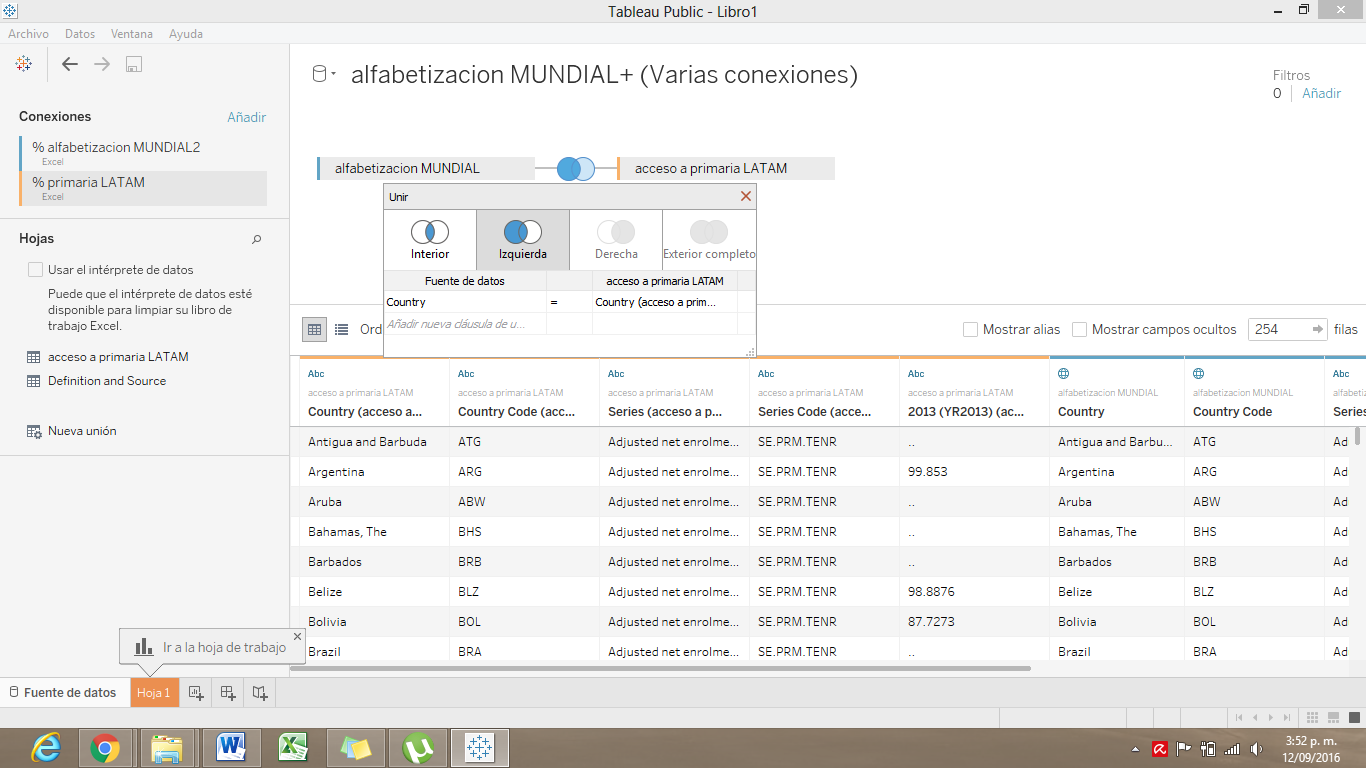
En este tipo de unión, sólo se copiaran los datos en los que el denominador común de ambas fuentes de datos coincida. Por ejemplo, si tenemos un set de datos sobre alfabetización en todos los países del mundo y lo combinamos con datos sobre el acceso a la educación primaria en los países de Latinoamérica, nuestra base de datos combinada solo mostrará los datos de los países de Latinoamérica.
La segunda, es una unión izquierda.
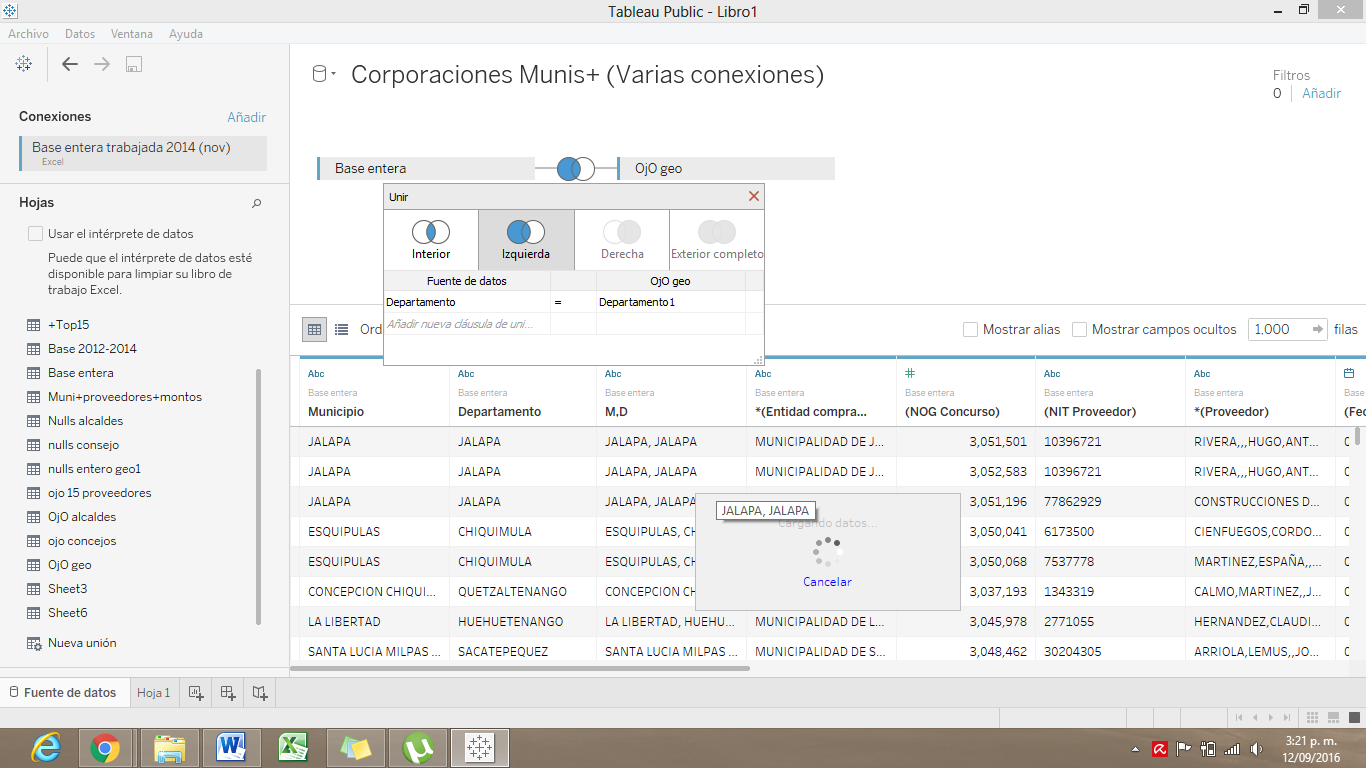
En este tipo de unión, se copiarán todos los datos de tu primera fuente de datos y sólo se agregarán los datos de la segunda fuente cuando estos coincidan en denominador común. Las filas que no tengan coincidencias se mostrarán como valores nulos. Siguiendo nuestro ejemplo, nuestra base de datos combinada mostraría los datos de alfabetización de todos los países del mundo, pero aquellos que no forman parte de Latinoamérica no contarían con datos sobre el acceso a educación primaria.
4) Abre el programa y conecta tu primera fuente de datos
Al iniciar, el programa te invita a conectar a un archivo de base de datos, que puede ser en formatos Excel (xls, xlsx), Archivos de texto (csv) o Access. Selecciona tu primer set de datos. En nuestro ejemplo, sería el archivo con el porcentaje de alfabetización de todos los países del mundo.
5) Añade tu segunda fuente de datos
Haz click en la palabra añadir y agrega una segunda base de datos. En nuestro ejemplo, es el archivo con el porcentaje de acceso a la educación primaria en los países latinoamericanos.
6) Arrastra ambos sets de datos y conéctalos
Al arrastrar las diferentes hojas de cálculo a la pantalla de Tableau Public, el programa te mostrará la relación que estás creando entre ambas bases de datos y te dará una muestra de cómo luce tu conexión de datos.
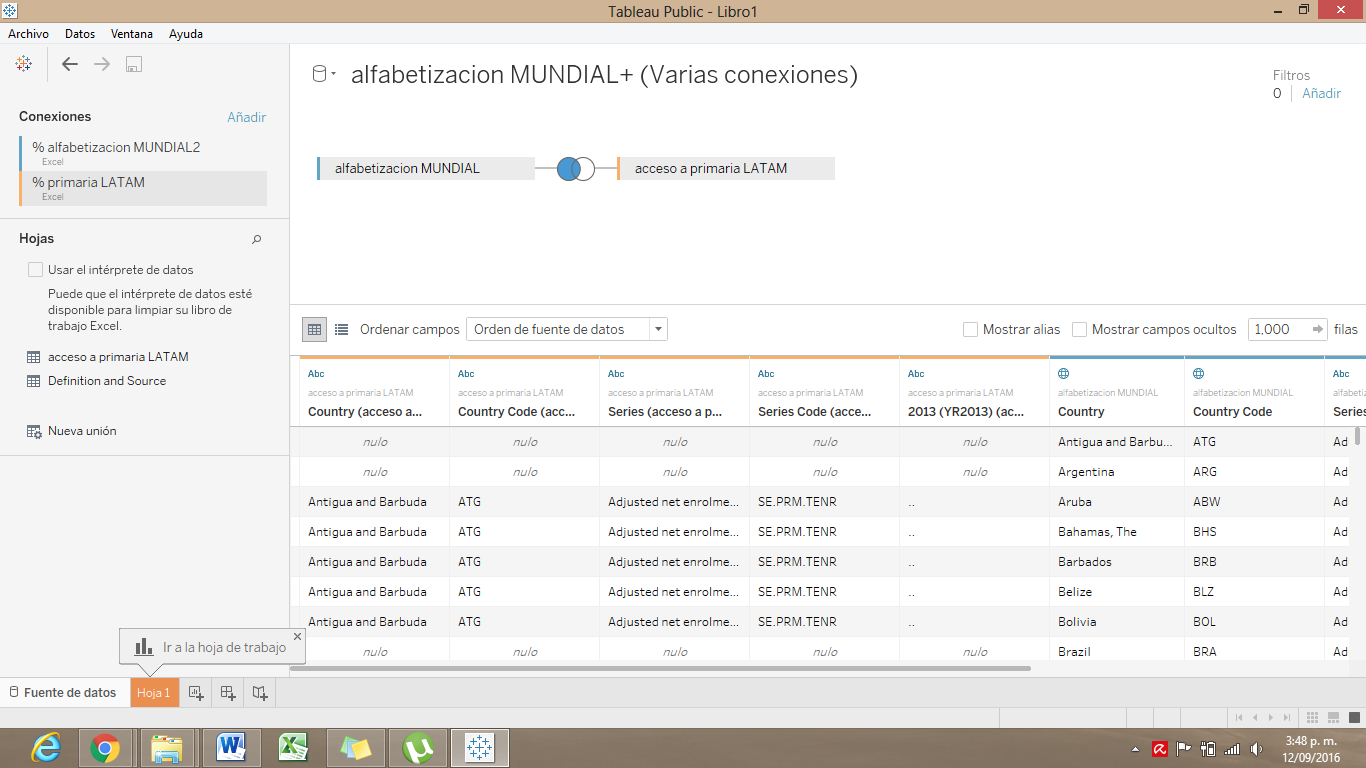
7) Edita la conexión
Haz click en los dos círculos unidos que se muestran entre tus fuentes de datos para abrir una ventana de edición de tu unión. En esta pestaña debes de decidir si quieres una combinación interior o una combinación izquierda. También debes de indicar cuál es la categoría en tus fuentes de datos que coincide o es igual en ambas. En este caso, seleccionamos el campo Country (País) para que combine los datos de cada país de manera automática.
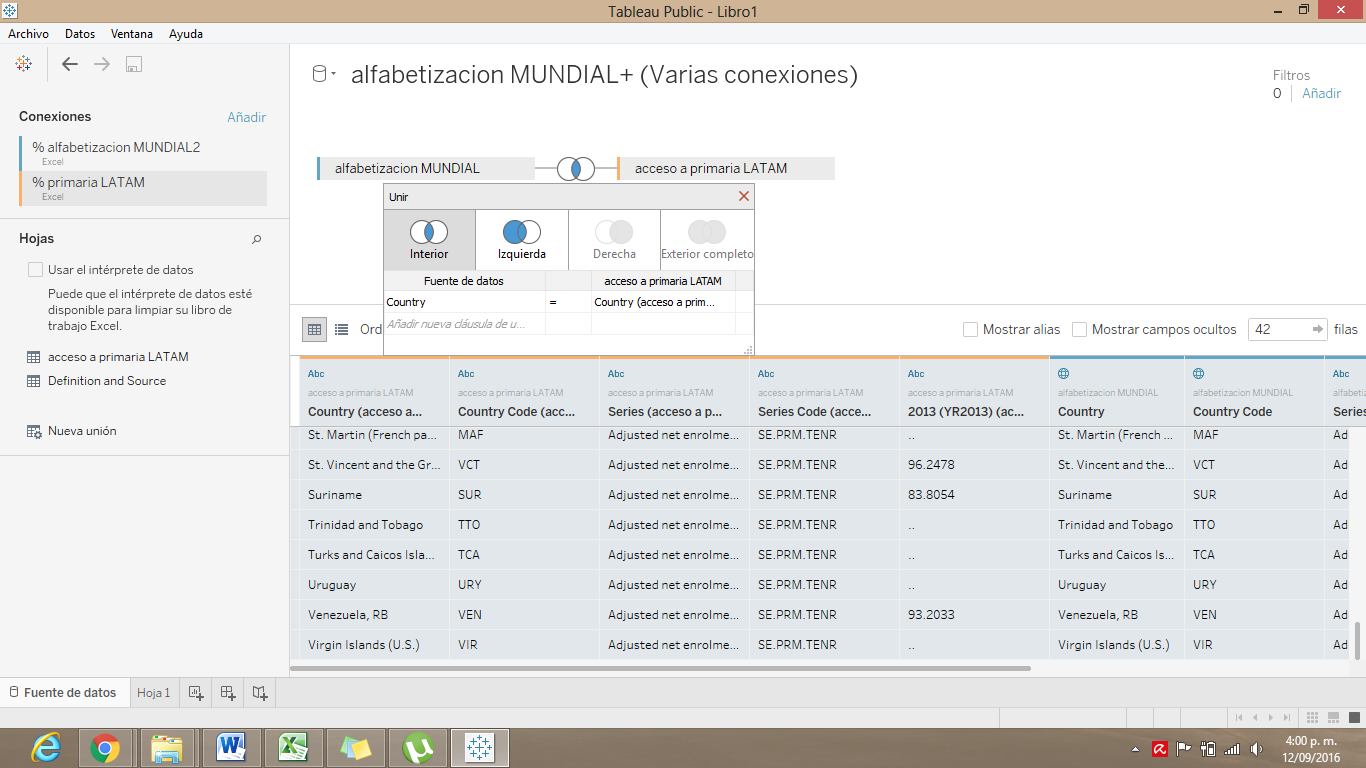
Siguiendo el ejemplo, si decides hacer una conexión interior, la combinación de estas dos bases de datos sólo te mostraria 42 filas con los datos de alfabetización y acceso a educación primaria de los 42 países de Latinoamérica y el Caribe.
En cambio, si eliges una conexión izquierda, el set de datos resultante te mostraría 254 filas con los nombres de todos los países del mundo y sus datos sobre alfabetización, pero los datos sobre acceso a educación primaria solo estarían en los países latinoamericanos. El resto de países tendría un valor nulo en esta categoría.
Durante todo el proceso, Tableau Public te muestra una previsualización de cómo se ve tu set de datos combinado debajo de la sección en la que editas las uniones.
8) Copiar y guardar.
Selecciona todas las filas y columnas de tu base de datos combinada haciendo click en la esquina superior izquierda de la previsualización que te muestra el programa. Copia el contenido con la combinación Ctrl+C o ⌘+C, pégalo en el editor de hojas de cálculo de tu preferencia y guárdalo.
Así, de manera sencilla, puedes combinar bases de datos con muchos campos y sin tener que prestar atención y copiar manualmente las coincidencias. Esta práctica es de mucha utilidad cuando quieres combinar diferentes estadísticas sobre varios lugares, o cuando quieres combinar una base de datos con datos georeferenciales con una que contenga estadísticas.
La combinación izquierda te puede servir para identificar valores que coincidan entre dos bases de datos. Esto es de mucha utilidad cuando estás creando hipótesis para investigaciones o quieres comprobar relaciones entre listados de personas o entidades.
![]()
Es por eso que los que hacemos mapas en países latinoamericanos tenemos una misión un poco más complicada, debemos conseguir la información cartográfica y unirla con nuestras bases de datos.
A continuación describiremos el proceso para unir el archivo con la información cartográfica y una base de datos en Excel.
El archivo con los polígonos de los municipios de Guatemala en formato Shape (.shp) lo obtuve de la página web de la Secretaría de Planificación de la Presidencia, si necesitas un mapa de tu país puedes descargarlo en este enlace.
Sube el archivo .zip que contiene el archivo .shp a Carto para empezar a usarlo.
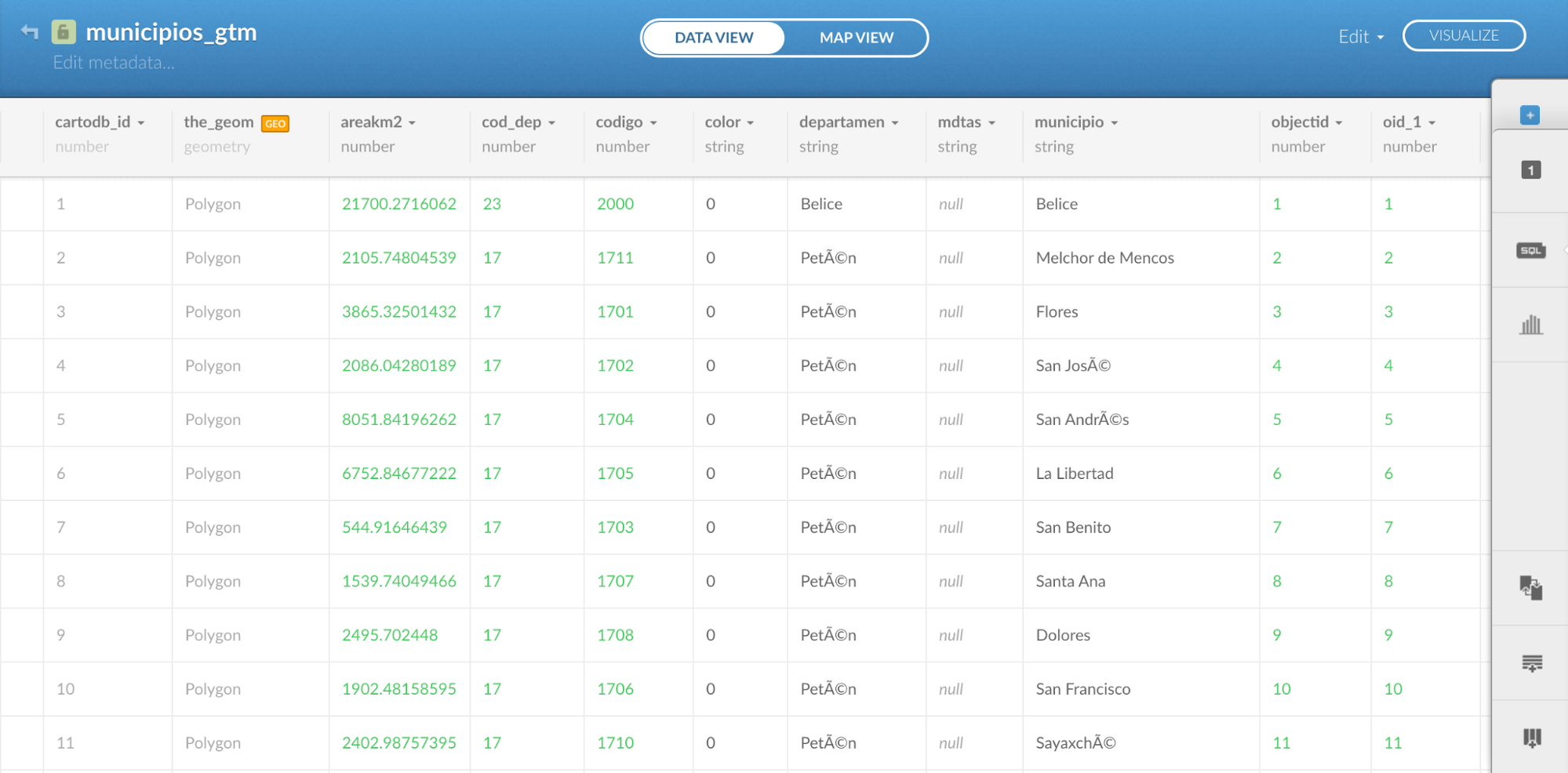
Como podrás ver en la columna quinta columna “código” están los códigos asignados por el gobierno de Guatemala a cada municipio.
Estos son códigos estandarizados que debe tener el Instituto Nacional de Estadística de tu país. Estos son los códigos estandarizados de los 340 municipios de Guatemala.

En el caso de Guatemala utilizamos los códigos porque normalmente ninguna base de datos de información gubernamental tiene los mismos nombres para todos los municipios, como en el caso del archivo .shp y la base de datos.
Ahora debes abrir la base de datos que quieres visualizar en el mapa. En mi caso usaré una que tiene información sobre las escuelas preprimaria del país.
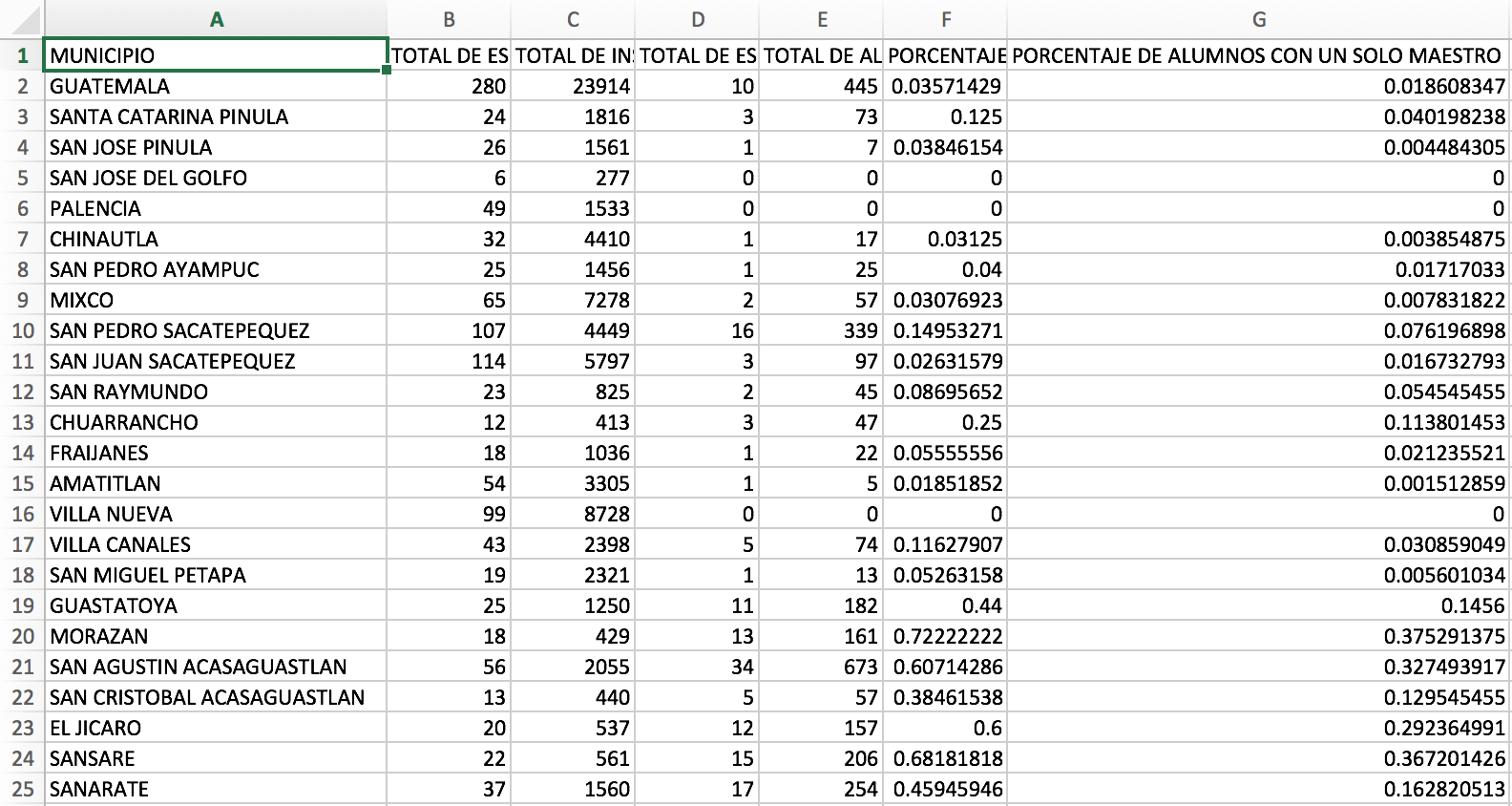
Para agregar los códigos estandarizados a la base de datos agregaremos una columna y usaremos la fórmula BUSCARV para localizar los códigos en el archivo anterior.
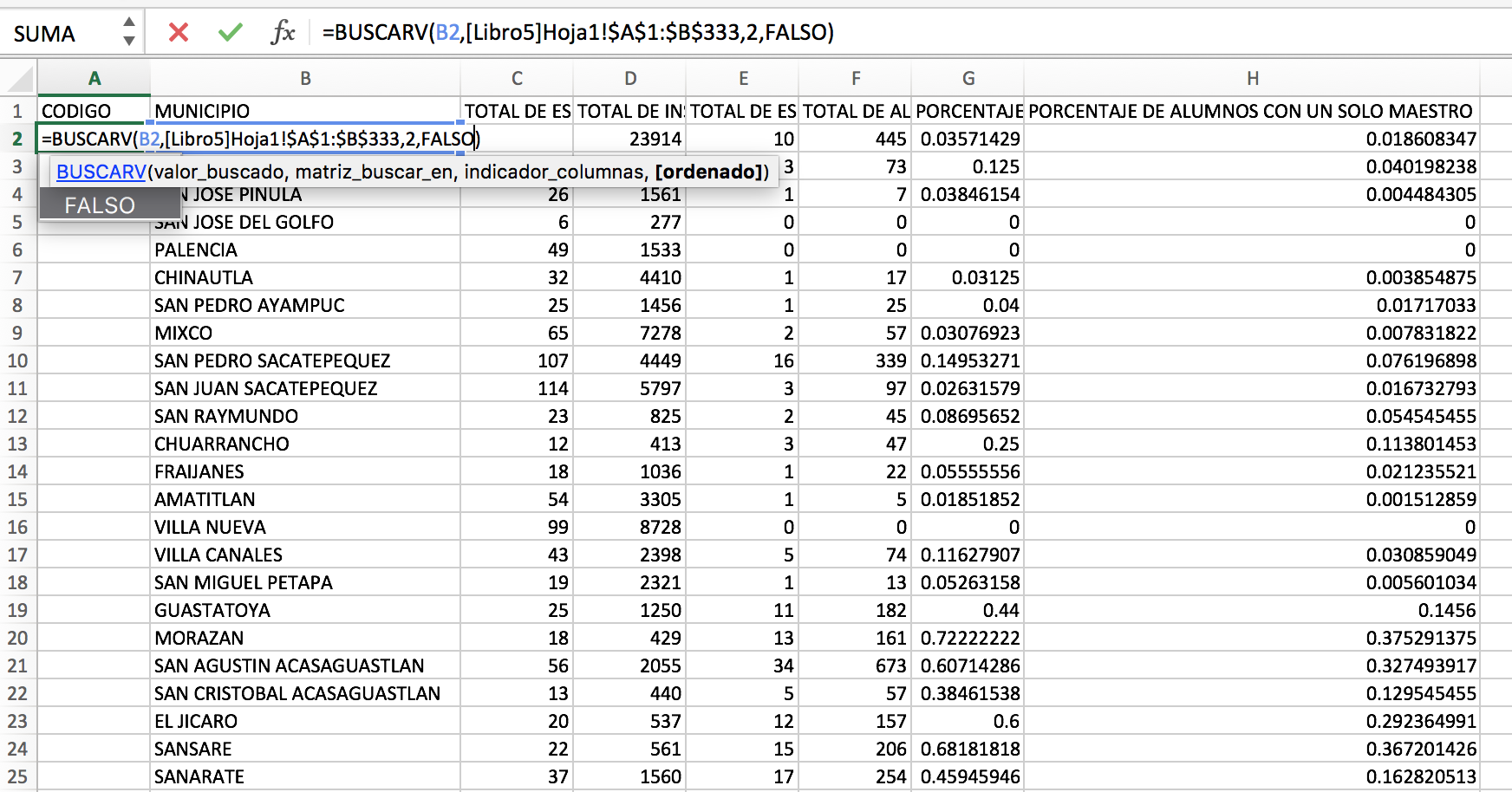
Ya con los códigos en todos los municipios deberás subir el archivo a Carto.
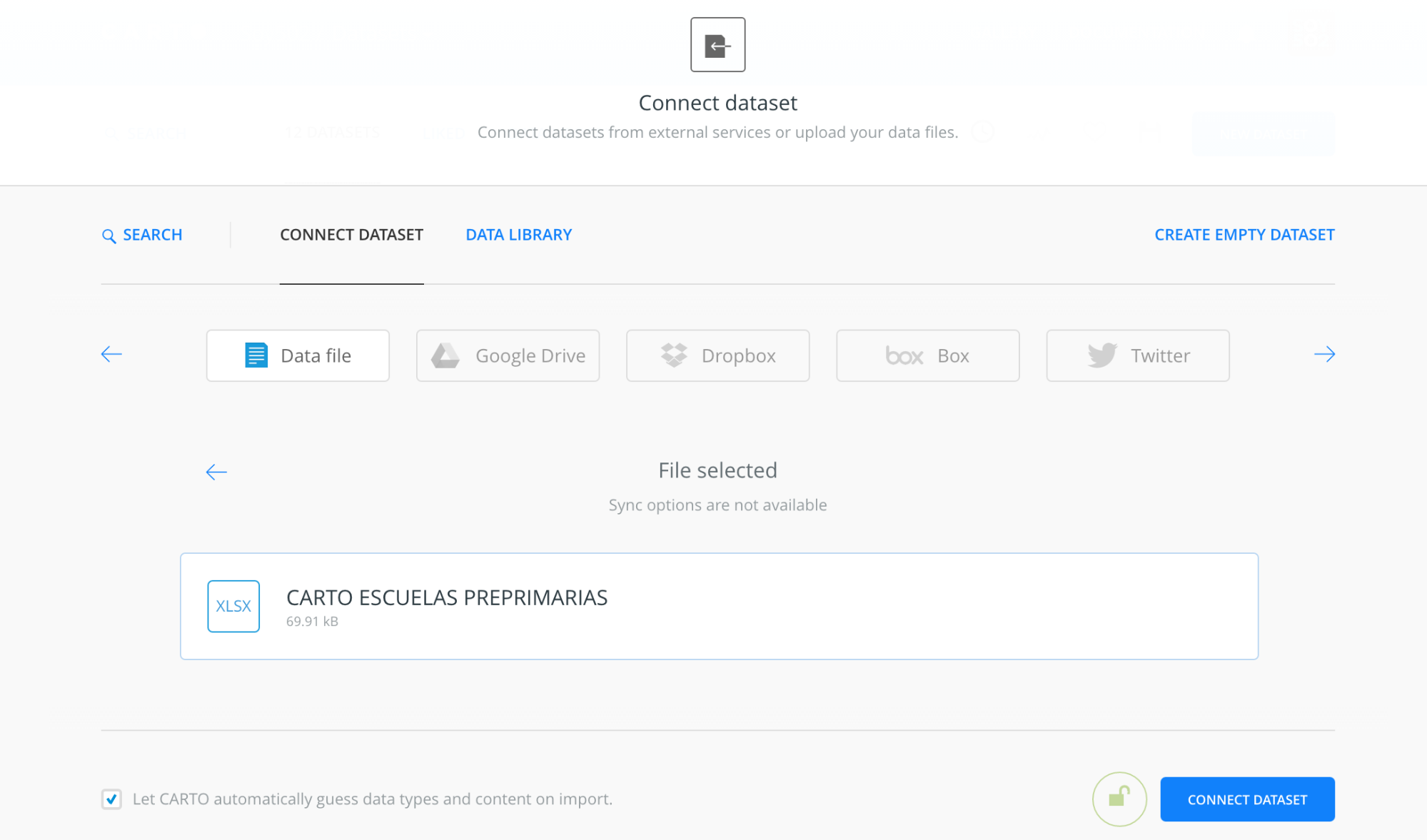
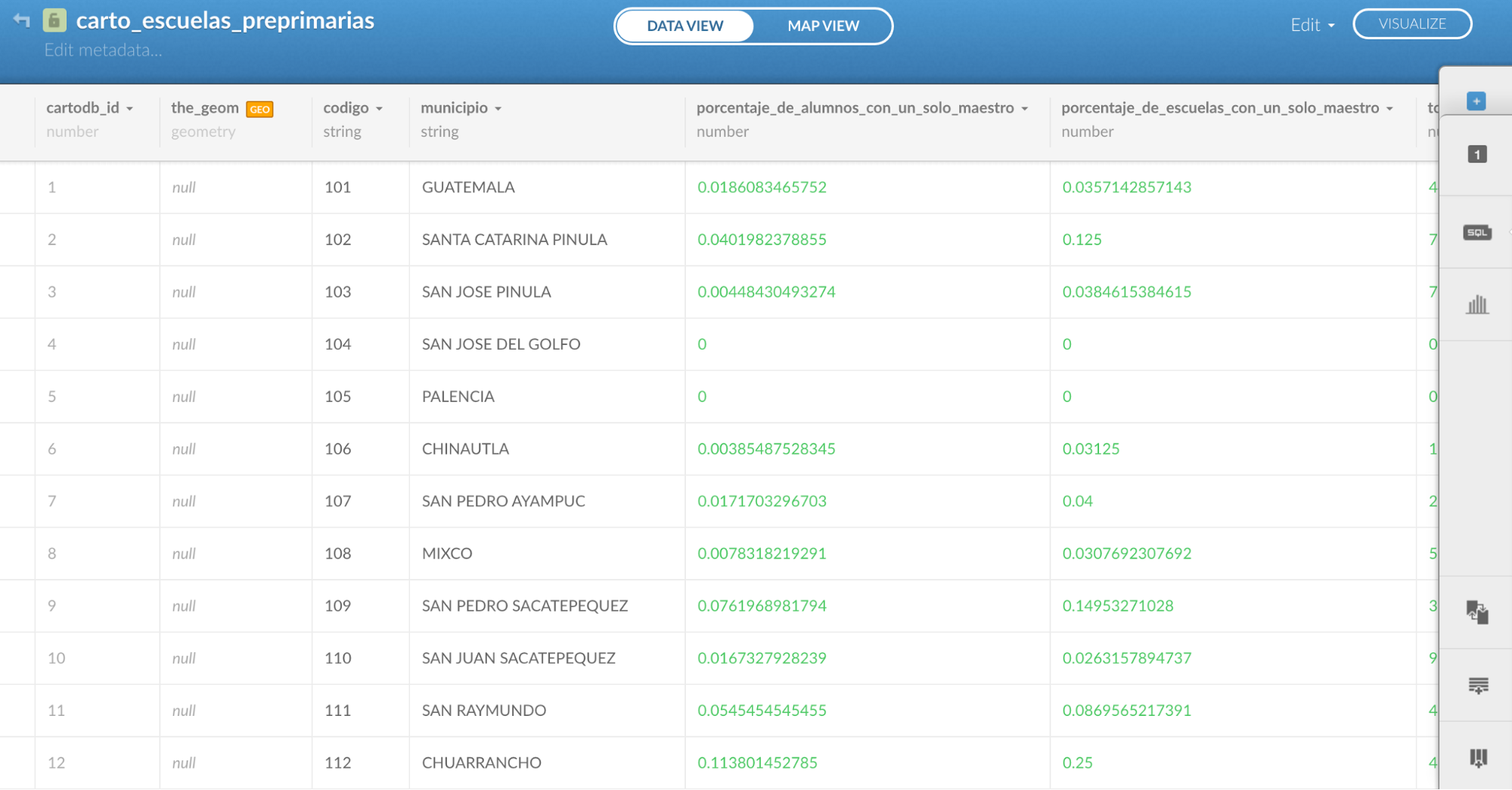
Ahora debes dar click en “edit” y a “Merge with dataset”
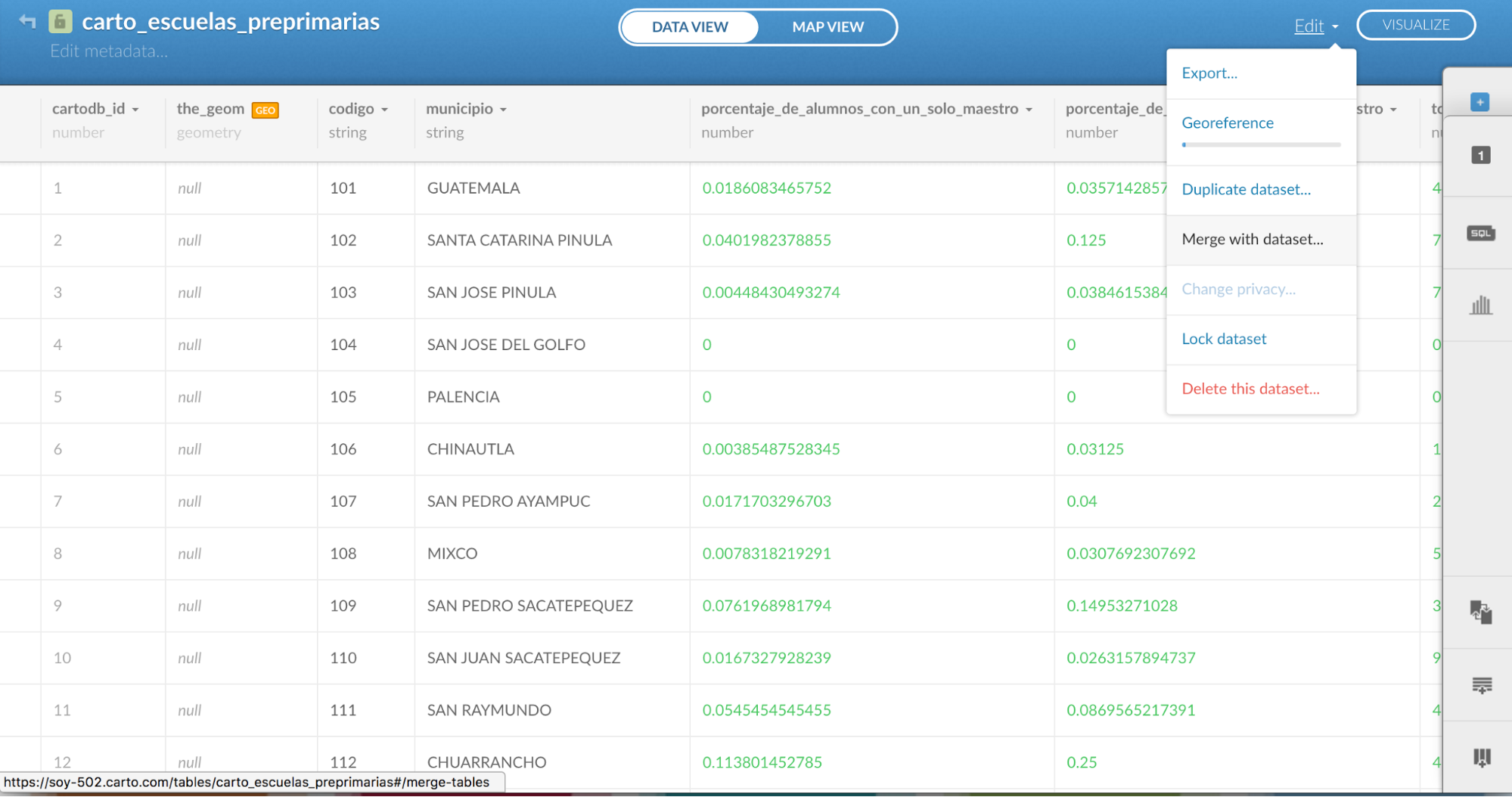
Debes elegir la opción “Column join” para unir los dos archivos

Y seleccionar en la segunda columna el archivo “municipios_gtm” que fue el que subiste del archivo .shp.
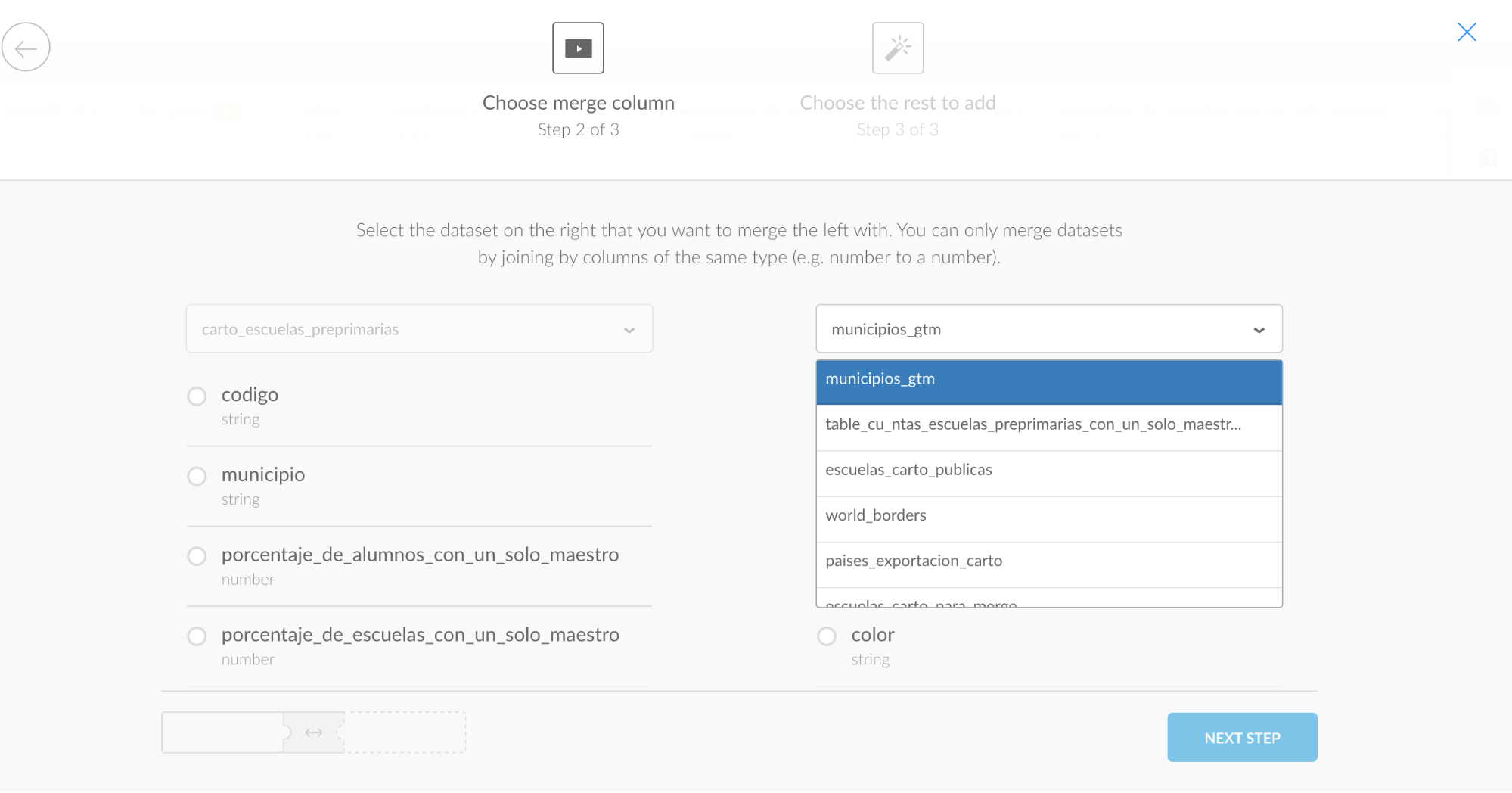
Debes seleccionar que utilice la geometría del archivo “municipios_gtm” que es el que tiene la información cartográfica.
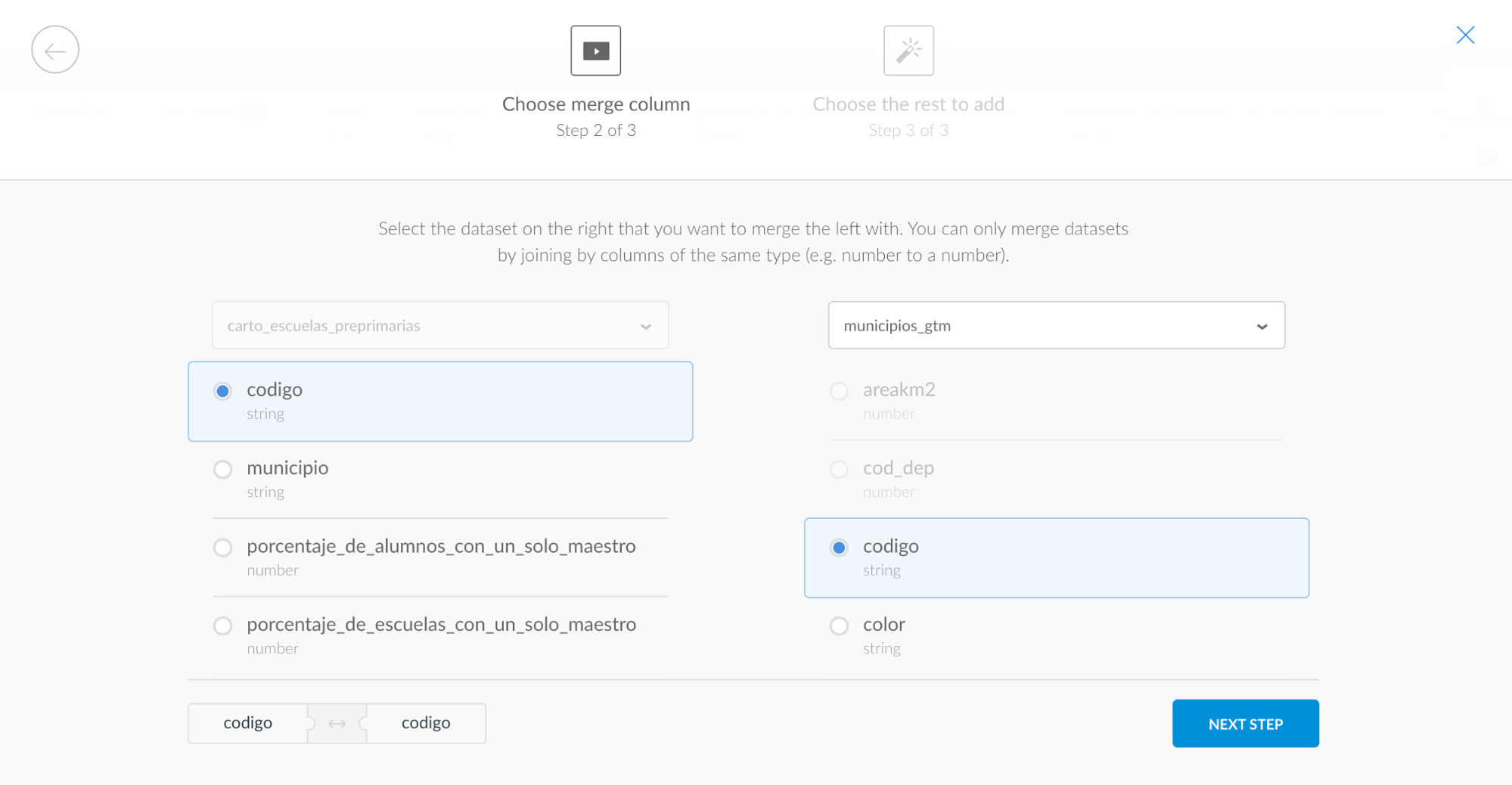
Y ahora viene la magia. Debes hacer click en “Merge Datasets”. Así quedan las dos tablas unidas.

Ahora debes hacer click en “Map view”. Todos los polígonos de los municipios estarán marcados.
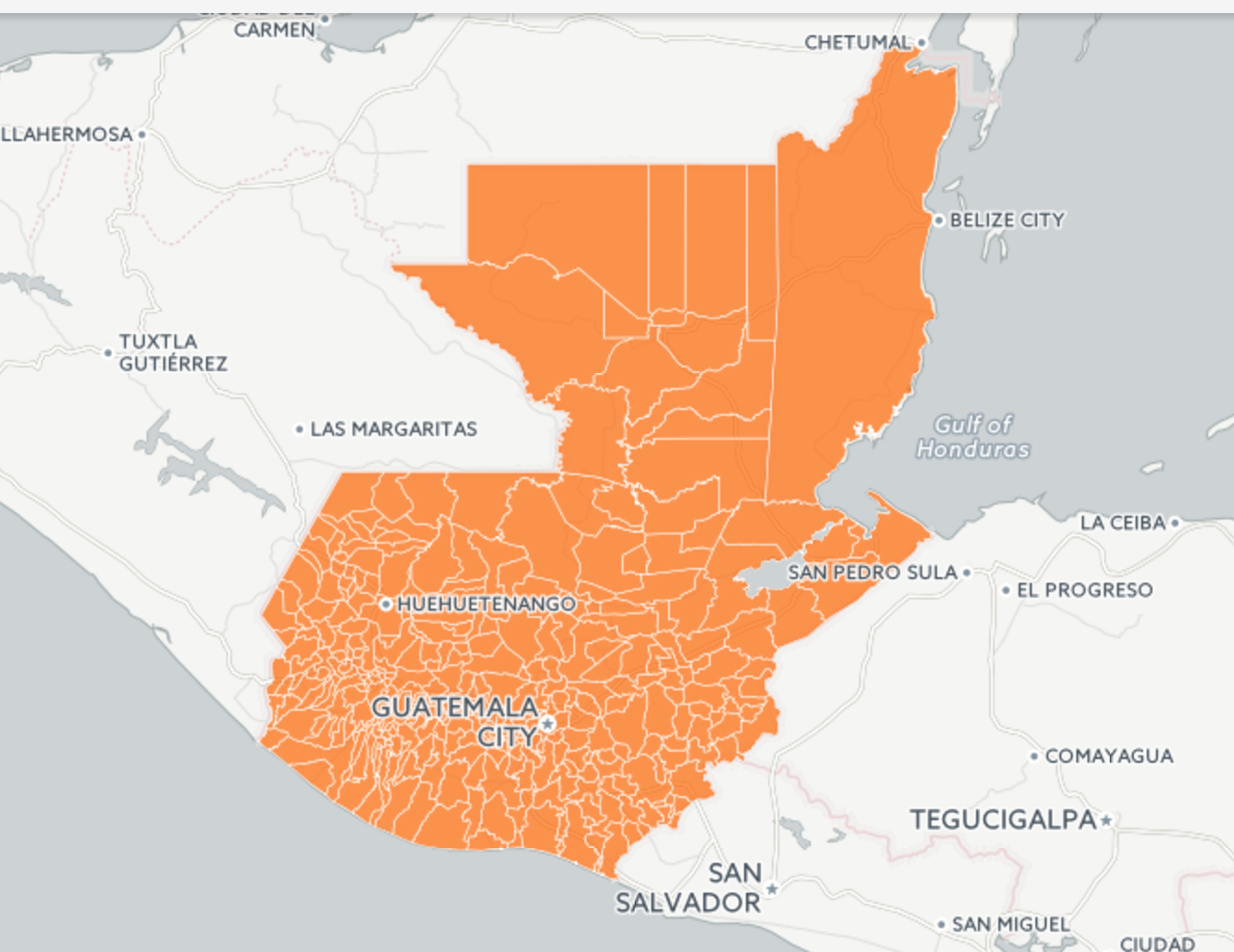
Luego ya deberás personalizar tu mapa como quieras utilizando los datos de tu base de datos.
Este fue mi resultado:

![]()

Fellowship 2016
Postúlate ¡AHORA!
Fecha límite: 10 de marzo 2016
Duración: abril a diciembre 2016
Link: http://bit.ly/fellowship_2016
Escuela de Datos invita a periodistas, sociedad civil y cualquier persona interesada en impulsar la alfabetización de los datos a postularse al programa de Fellows 2016, que abarca de abril a diciembre 2016. Hay hasta 10 selecciones abiertas y la fecha límite para postular es el 10 de marzo, 2016.
¡Postúlate ahora!
Las fellowships son posiciones de 9 meses con entrenadores, especialistas y entusiastas de Escuela de Datos. Durante este periodo de tiempo, los y las fellows trabajan como parte de la red de Escuela de Datos desarrollando nuevas habilidades y conocimientos ya sea relacionados con una temática social, la construcción de comunidades de datos y la formación para alcanzar un mayor uso de datos.
Como parte de este fellowship, nuestro objetivo conjunto es incrementar la alfabetización de datos y construir comunidades de práctica que cuenten con las habilidades en el uso de datos para poder cambiar su entorno.
Una fellowship temática
Para enfocar el entrenamiento y experiencia de aprendizaje de las y los Fellows de Escuela de Datos 2016, este año se contempla un enfoque temático. Como resultado, se priorizará la selección de postulantes que:
- cuenten con la experiencia en y entusiasmo por un área específica en el entrenamiento de datos
-
Muestren vínculos con organizaciones que se desempeñen en un tema específico o muestren que tienen vínculos cercanos con quienes abordan esta temática de manera directa
Estamos buscando a individuos involucrados que ya cuentan con conocimiento profundo de un sector o tema, y que activamente han influenciado el uso de los datos en esa temática dada. Este enfoque permitirá a las y los Fellows iniciar rápidamente actividades y alcanzar lo máximo durante su participación en la Escuela de Datos: ¡nueve meses pasan muy rápido!
Además, ya contamos con organizaciones aliadas dispuestas a apoyar a las y los Fellows interesadas en trabajar los siguientes temas: periodismo basado en datos, industrias extractivas y datos responsables. Estas maravillosas contrapartes orientarán, darán mentoría y brindarán mayor conocimiento en cada uno de estos temas.
< Conoce más sobre el enfoque temático >
Nueve meses para generar un impacto
La Fellowship es de abril a diciembre de 2016 y comprende por lo menos 10 días al mes del tiempo de cada Fellow para trabajar offline y online. La o el Fellow debe fortalecer su comunidad local a través de entrenamientos, apoyando proyectos basados en datos y satisfaciendo sus necesidades para el uso de datos. Virtualmente, la o el Fellow debe participar activamente en la red global de School of Data, compartiendo conocimiento a través de sesiones online, posts en el blog y contribuyendo con la generación y actualización de los recursos de enseñanza de la comunidad. Cada Fellow recibirá un apoyo mensual de $1,000usd por su trabajo.
En mayo de 2016, todos los Fellows seleccionados participarán presencialmente en el tradicional Campamento de Verano (ubicación por definir) en donde se conocerán, compartirán conocimientos y habilidades, aprenderán sobre métodos, tácticas y enfoques de entrenamiento de Escuela de Datos.
¿Qué estás esperando?
Postúlate Ahora
Información clave:
- Fellowships disponibles: hasta 10 fellows, 5 reservados para realizar periodismo basado en datos
-
Fecha límite de postulaciones: 10 de marzo, 2016, medianoche GMT
-
Duración del Fellowship: del 1 de abirl 2016 a diciembre 31, 2016
-
Nivel de actividad: por lo menos 10 días al mes
-
Estipendio: $1,000 usd al mes
Este post es una traducción de https://schoolofdata.org/2016/02/10/apply-now-for-school-of-datas-2016-fellowship/
![]()
El pasado 21 de febrero, el mundo celebró el día de los datos abiertos. Natalia Ortíz, investigadora de Congreso Transparente, nos comparte todo sobre la celebración en Guatemala.

Fotografía: Gabriel Woltke/Congreso Transparente
Desde Guatemala nos unimos a los eventos realizados en toda la región para celebrar el Día de los Datos Abiertos.
Con la frase “¿y deai? ¿Qué datos hay?, un juego de palabras que surgió en la planificación de esta actividad, nos hicimos la pregunta, acerca de qué iniciativas de datos hay en Guatemala. Una actividad organizada por Congreso Transparente, el Instituto Republicano Internacional y Hacks Hackers Guatemala.
El objetivo propuesto fue realizar una convocatoria abierta para conocer las distintas experiencias de organizaciones, universidades, instituciones de gobierno y todos aquellos que han trabajado en distintas iniciativas con datos abiertos, establecer cuáles han sido los principales desafíos y las perspectivas a futuro sobre la apertura de datos en el país.
Así, conocimos una diversidad de experiencias en el uso de datos: desde la creación de plataformas de recopilación de datos y aplicaciones cívicas que contribuyen a generarlos, hasta su uso para ciudades más sostenibles y fines de investigación académica.
Una de las principales conclusiones de esta actividad es que la apertura de datos puede llevarnos a generar nuevas sinergias, a marcar una diferencia no solo en el país, sino en la región. Por lo que uno de los retos a los que nos enfrentamos actualmente es a potencializar la apertura de datos en Guatemala para fortalecer la auditoría social y el empoderamiento ciudadano.
Como resultado de esta actividad, esta semana se realizará una primera reunión en la cual se busca coordinar esfuerzos ante un evento importante para el país: las Elecciones Generales 2015.
Ya dimos el primer paso, el desafío ahora es realizar acciones conjuntas para así continuar avanzando en la conformación de una comunidad datera en Guatemala.
 Fotografía: Natalia Ortíz/Congreso Transparente
Fotografía: Natalia Ortíz/Congreso Transparente
![]()

Desde hace tiempo, Escuela de Datos participa en conversaciones de muchas de las comunidades de datos distribuidas por varias regiones del mundo. Ahora de la mano de nuestros amigos de Desarrollando América Latina (DAL), emprendemos una aventura que nos lleva a visitar Guatemala, El Salvador y Nicaragua para seguir promoviendo la cultura de los datos abiertos en el marco del Apps Challenge de la región.
En todas estas actividades estarán participando nuestros data sherpas Rubén Moya, actual fellow de Escuela de Datos, y Sergio Araiza, líder datero en SocialTIC.
La aventura comienza en tierra Chapín
La primer parada es Guatemala, y ahí, en colaboración con Congreso Transparente y Plaza Pública estaremos participando en la primer sesión de ideación y hackatón DAL el día sábado 25 de octubre. Impartiendo la charla “Hacking cívico en Latinoamérica” mostraremos muchos de los proyectos dateros que están sucediendo en varios países de LATAM y que hemos conocido gracias a las contribuciones que nos envían lectores y seguidores por nuestras redes sociales y la página (no dejen de hacerlo).
Los días lunes 27 y martes 28 de octubre en las instalaciones de la Universidad Landivar impartiremos la primera de las expediciones de datos que haremos en el tour. Compartiremos experiencias y conocimiento con Rodrigo Baires, editor del área de datos en Plaza Pública. La sesión está enfocada en que periodistas y programadores aprendan técnicas sobre manejo de datos y narrativas basadas en datos.
Si quieres participar o tienes dudas, puedes estar en contacto con los organizadores:
- Congreso Transparente: @CongresoT
- Plaza Pública: @PlazaPublicaGT
Escuela de Datos presente en El Salvador
Nuestro tour continúa en El Salvador con la compañía de la embajadora de OKFN y coordinadora local de DAL, Iris Palma. La actividad comienza el 29 por la tarde: nuestra segunda expedición de datos con la compañía de Alexis Rojas, líder técnico del portal http://www.datoselsalvador.org. La invitación está abierta para que ONG, periodistas y programadores nos ayuden a resolver la pregunta que da inicio a toda expedición: ¿qué dicen los datos?
Aún hay más en la tierra de las pupusas. El día 30 realizaremos una sesión de acompañamiento a los equipos de desarrolladores que están participando en la iniciativa local de DAL. Si tienes una idea o quieres ayuda con tu proyecto, escríbenos y participa.
Nicaragua: datos y hackatón… ¡¡Ea, ea!!
Nuestro tour concluye en Nicaragua, en donde nuestros amigos de IEEPP están organizando un verdadero festival de los datos abiertos para concluir la semana. Agárrense.
Todo inicia el viernes 31 con un panel sobre periodismo de datos en el que participan:
- Romina Colman, La Nación Argentina
- Juan Manuel Casanueva, director de SocialTIC A.C. y ICFJ Knight Fellow
- Hassel Fallas, La Nación Costa Rica.
Terminando la sesión, nos teletransportamos al primer Data Meetup en Nicaragua, en el que desarrolladores inscritos en DAL y expertos sociales presentarán los retos que serán atacados durante el hackatón de la iniciativa.
Y como ya mencionamos, el día sábado comienza el código con el arranque del hackaton DAL Nicaragua 2014 en el que, además de dar apoyo a los equipos, estaremos llevando una expedición de datos con grupos de ONGs y periodistas que participan en el evento.
¡Se viene una semana llena de datos y hacking! No se pierdan ni un detalle de las actividades en Twitter y Facebook, y no olviden que, si tienen algún proyecto que compartir o quieren participar en alguna actividad, pueden escribirnos a la dirección [email protected]
![]()