¿Te has encontrado con bases de datos que tienen pequeños errores de transcripción? ¿Espacios de más, uso desordenado de mayúsculas y minúsculas, o registros que representan al mismo dato pero que fueron escritos con pequeñas diferencias? Con la herramienta OpenRefine puedes automatizar mucho del doloroso proceso de limpiar una base de datos. En este tutorial te enseñaremos una de sus funciones más útiles: la clusterización —o generación de agrupaciones automáticas— y los diferentes algoritmos que determinan las coincidencias entre registros.
El concepto de clusters (o agrupaciones, en español) se utiliza mucho en ciencias sociales y exactas para referirse a un tipo de análisis que toma un conjunto de datos y las reorganiza en grupos con características similares.
En OpenRefine, cuando uno hace clusters significa que el programa está encontrando grupos de valores diferentes que pueden ser representaciones alternativas del mismo valor. Por ejemplo, si hablamos de ciudades, “New York”, “new york” y “Nueva York” son tres valores diferentes pero que se refieren al mismo concepto, sólo con cambios de idioma y de uso de mayúsculas y minúsculas.
Vale la pena mencionar que las agrupaciones en OpenRefine sólo se generan automáticamente en la sintaxis (o sea, el orden y la composición de caracteres que tiene como valor una celda) y aunque estos métodos son útiles para encontrar errores e inconsistencias, no son lo suficientemente avanzados para determinar agrupaciones a nivel semántico (o sea, el significado de un valor).
Estos métodos se pueden aplicar determinando cuántos grados de cercanía -en otras palabras, qué tan estrechas o flojas quieres encontrar las coincidencias-. Al graduar la cercanía encuentras coincidencias más o menos exactas. Por eso es importante que si bien, los algoritmos ayudan a automatizar la tarea de limpieza, un ojo y cerebro humano va administrando qué tan agresivas deben ser estas uniones para encontrar coincidencias, para evitar que asocie datos que no deberían ir juntos.
Conozcamos los algoritmos: En qué consisten estas metodologías
Existen dos grandes metodologías para hacer clusters: la colisión clave y el vecino más cercano. Open Refine utiliza diferentes variantes de estos dos métodos. Aquí te explicamos cuál es el proceso detrás de cada uno.
Sección 1: Métodos de colisión clave
Estos se basan en la idea de crear una representación alternativa de un valor inicial, el cual se convierte en una clave. Una clave contiene las partes más distintivas y significativas de un valor. OpenRefine va buscando en los demás registros qué otros valores se parecen a esta clave para agruparlos. El procesamiento requerido para este método no es muy complejo, por lo que presenta resultados muy rápidos. Este método tiene varias funciones diferentes que se pueden administrar en OpenRefine.
- Fingerprint
Un método fácil y simple. Quita todos los espacios en blanco, cambia todos los caracteres a minúsculas, remueve toda la puntuación y normaliza cualquier caracter especial a una versión estándar. Luego, parte el texto y aplica espacios en blanco. Así encuentra las coincidencias.
- N-Gram Fingerprint
Es similar al anterior, pero en vez de separar los caracteres por espacios en blanco, usa una cantidad a la enésima (n) potencia de espacios que el usuario puede determinar.
- Fingerprint Fonético
Este método no revisa los caracteres textuales sino su pronunciación y fonética: la manera en que esa palabra se pronunciaría, en vez de revisar similitudes en la escritura. Es muy útil para limpiar datos con nombres particulares, ya sea de lugares y personas. En ocasiones, los errores de registro se deben a que se registran a partir de la pronunciación. Sirve para encontrar similitudes entre sonidos parecidos pero que se escriben muy distinto como el sonido de “sh” y “x”, que en ocasiones son similares.
Sección 2: Vecino más cercano (Nearest neighbor)
Estos métodos proveen un parámetro o radio de aproximación alrededor de un valor o palabra, y va encontrando los grados de similitud entre éste y otros registros. Debido a los cálculos necesarios, estos métodos son más tardados en procesar.
- Distancia Levenshtein
Este método se basa en el trabajo y proceso que implicaría cambiar a un registro A para que sea igual a un registro B. La distancia Levenshtein mide cuántas operaciones de edición -o cuántos pasos- le tomaría a alguien hacer que un dato se parezca al otro. Encuentra coincidencias entre los datos que están separados por la menor cantidad de pasos o cambios.
Por ejemplo, “Paris” y “paris” tienen una distancia de edición de 1, ya que solo se debe cambiar la P mayúscula a una minúscula. Sin embargo, “Nueva York” y “nuevayork” tienen una distancia de 3 pasos: dos sustituciones y un borrón.
- PPM (Prediction by Partial Matching)
Este método se utiliza para encontrar coincidencias en secuencias de ADN. Estima la similitud entre textos y determina su contenido idéntico. Por ejemplo, con el ADN encuentra similitud entre dos muestras para indicar un grado de familiaridad. Es común en este campo que no se busque una coincidencia exacta (que implicaría trabajar con muestras de ADN de la misma persona) sino encontrar un alto grado de coincidencia y familiaridad.
Si dos cadenas A y B son idénticas, al concatenar A+B debería de producirse muy poca diferencia. Pero si A y B son diferentes, al concatenar A+B se deberían producir diferencias muy dramáticas en la longitud de la cadena.
Paso a paso. Aplicando los clusters en OpenRefine
 OpenRefine es un programa que corre a través de tu browser o navegador de internet. Para instalarlo, es necesario que lo descargues en este link y sigas las instrucciones para tu equipo. Usualmente, solo requiere que descargues la carpeta, la descomprimas y abras la aplicación.
OpenRefine es un programa que corre a través de tu browser o navegador de internet. Para instalarlo, es necesario que lo descargues en este link y sigas las instrucciones para tu equipo. Usualmente, solo requiere que descargues la carpeta, la descomprimas y abras la aplicación.
OpenRefine debería abrir una ventana negra con algunos códigos y abrirse automáticamente en tu navegador de internet. Si no funciona, prueba ir a la dirección http://127.0.0.1:3333/
Vamos a hacer un ejemplo con un conjunto de datos sobre financistas a las elecciones del 2017-2018 en Estados Unidos que puedes descargar aquí.
Para subir el archivo, solo sigue los siguientes pasos:
Create project > Elegir archivo (selecciona el archivo ZIP que descargaste) > Next
OpenRefine te mostrará una previsualización de tu conjunto de datos. En este caso, deberás desmarcar la opción >Parse Next para indicar que tu base de datos no tiene títulos de columna en la primera fila.
En >Project Name, escribe “Financiamiento político_Estados Unidos 2017-2018” y da click a >Create project para guardar este proyecto.
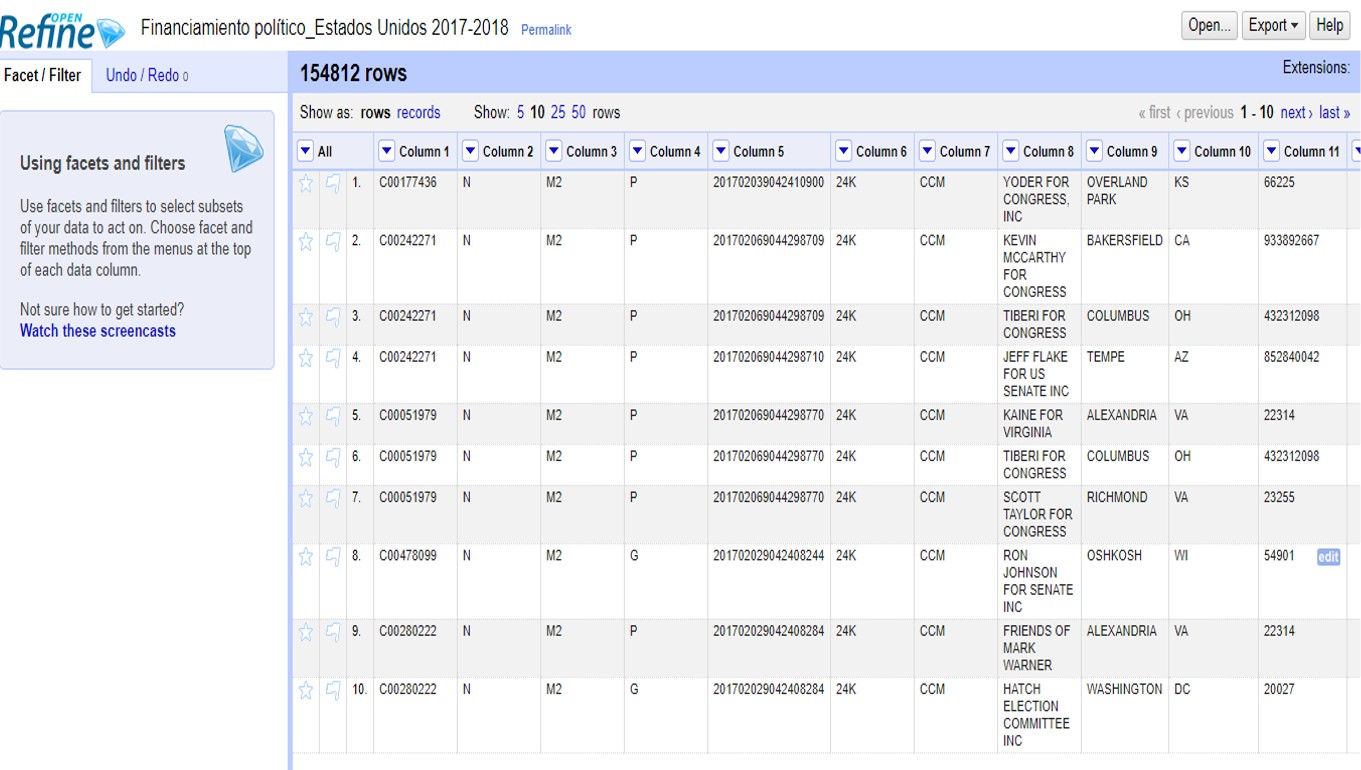
En la columna 8 encontrarás el listado de financistas. Haciendo click en el triángulo a la par del título de esta columna, selecciona >Facet >Text facet para generar un filtro de texto.
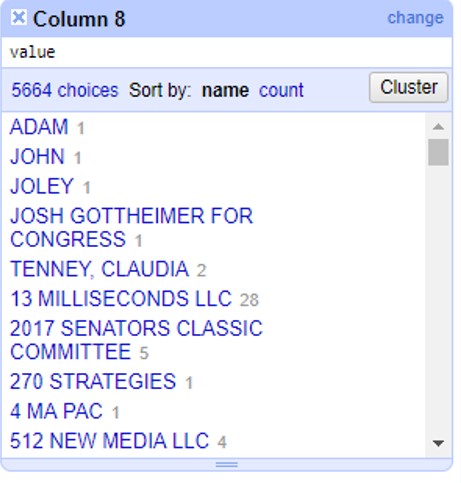
A un lado, te aparecerán todos los registros de financistas en orden alfabético, con un número a la par que indica cuántas veces aparece este nombre en la base de datos. Haz click en el botón >Cluster para empezar a generar agrupaciones automáticas.
En la siguiente ventana puedes aplicar todos los métodos de clusters que te enseñamos. Puedes administrarlo cambiando las opciones >Method, >Keying Function o >Distance Function.
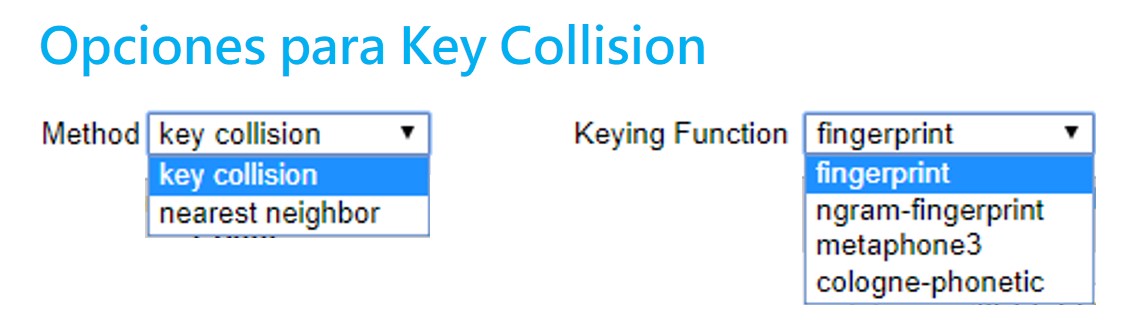

Con estos controles podrás ir determinando qué tan agresivos son tus clusters. Independientemente del método que eligas, el proceso es el mismo. Al seleccionar el método y sus opciones, OpenRefine comenzará a procesar los datos para encontrar coincidencias y armarlas en un cluster o agrupación.
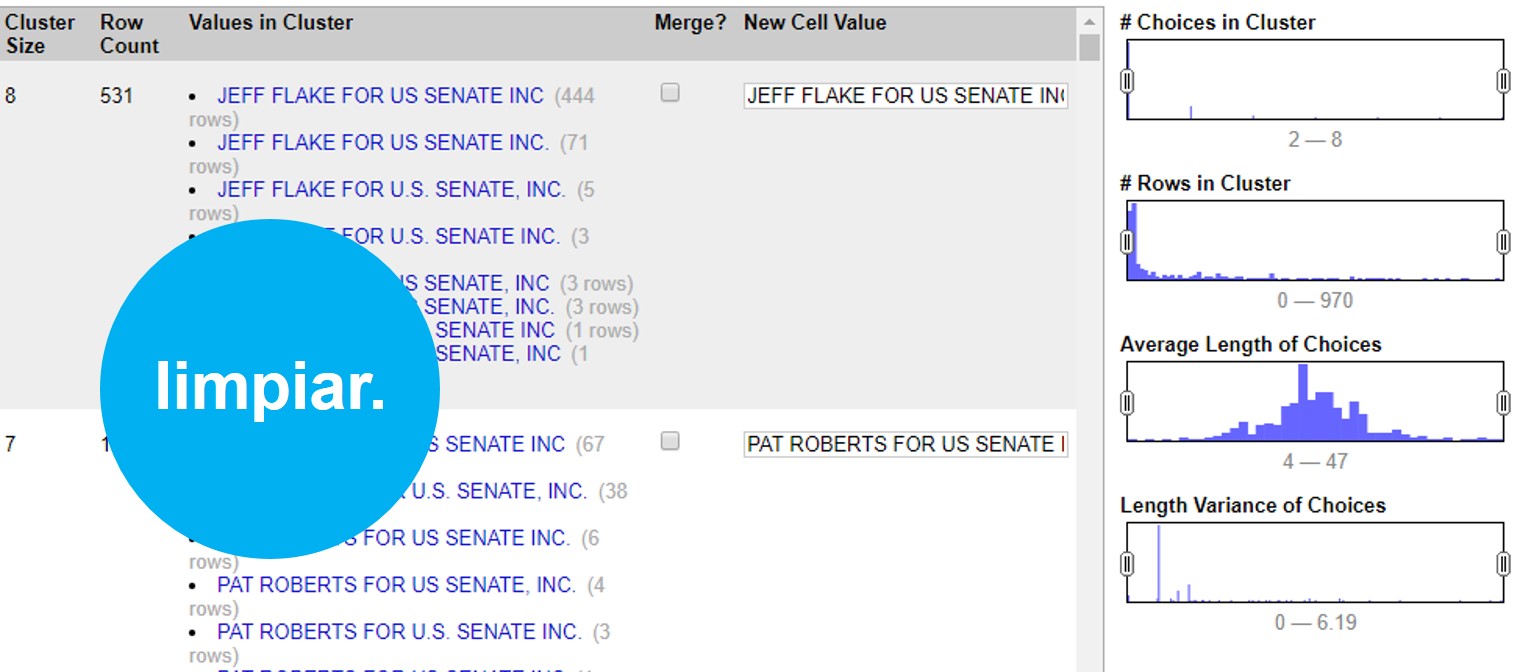
En este ejemplo podemos ver que el programa encontró 531 valores muy similares, escritos de 8 maneras diferentes para decir lo mismo: que un financista se llama “JEFF FLAKE FOR U.S SENATE, INC”. Como puedes ver, a la par de cada manera de escribir, OpenRefine te muestra cuántas veces aparece de esta manera el valor.
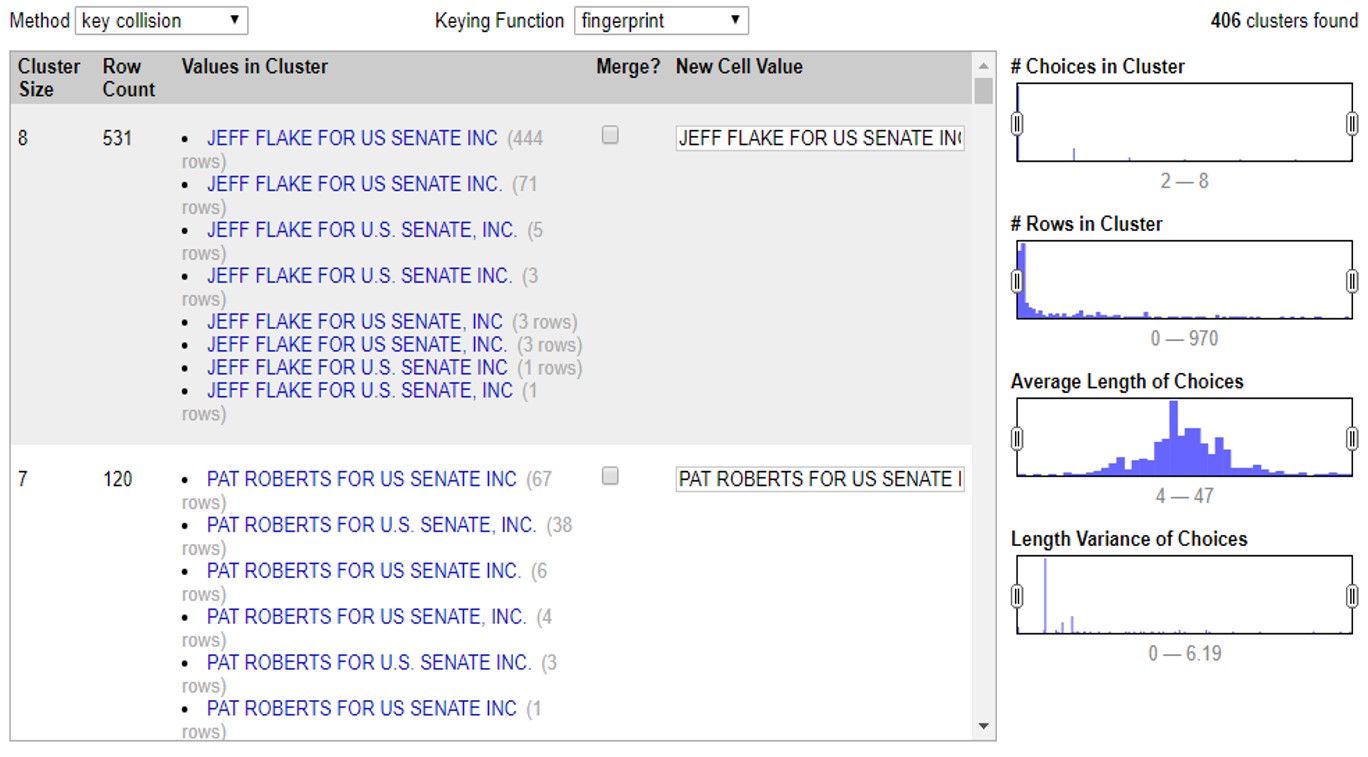
En este caso te muestra dos opciones. La primera, >Merge incluye una casilla que puedes seleccionar en caso de que sí quieras que OpenRefine una estos valores. En la segunda opción >New Cell Value, el programa te da la oportunidad de que edites y decidas de qué manera quieres que se reescriba este cluster. Así, irás administrando la agrupación valor por valor, decidiendo si quieres o no agrupar los valores con >Merge y la opción de escritura bajo la cual estos valores se agruparán con >New Cell Value
Con este ejemplo, si aceptas todas las agrupaciones de cluster que te permite el método >Key Collision >Fingerprint verás como la columna de financistas pasó de tener 5,664 opciones diferentes, a tener 5,136 registros diferentes. 528 valores menos que eran repetidos pero contenían errores gramaticales o de sintaxis que hacían que la computadora no los tomara como iguales.
Así, en estos sencillos pasos, OpenRefine editó los valores de 54,807 celdas que manualmente tomarían demasiado tiempo para limpiar y estandarizar.
Para finalizar, haz click en >Export para descargar tu base de datos limpia en el formato que prefieras.Ya sea valores separados por coma, o por tabulaciones; formato para Excel o HTML, OpenRefine te permite escoger entre diversos formatos para descargar la versión limpia de tu base de datos.
Cuéntanos en qué casos puedes utilizar los clusters y OpenRefine para limpiar tus datos. Escríbenos a [email protected] o por twitter @escueladedatos y estaremos compartiendo algunos ejemplos de usos de esta herramienta.
![]()