
Súmate a la conversación en redes con los siguientes hashtags #ODD18 #OpenDataDay
Para actualizaciones te recomendamos revisar el el mapa oficial del Open Data Day. ¡Si tu ciudad no aparece, aún estás a tiempo de organizar un evento! Escríbenos y te guiamos =)

Buenos Aires y Córdoba en Argentina
Eventos en Buenos Aires y ahora también en Córdoba, incluirán espacios de conferencias, capacitaciones y un Data Camp donde se plantearán desafíos, se analizarán y desarrollarán proyectos con el objetivo de aprender, idear y desarrollar proyectos de datos utilizando datos públicos.
La Paz, Bolivia
En La Paz, la comunidad local se reunirá para celebrar el ODD, revisa los detalles en Bolivia Tech Hub
Rio de Janeiro, Curitiba, Brasilia, Salvador de Bahía, Maceió y Sao Paulo en Brazil
La comunidad brasileña tendrá muchos eventos que incluyen charlas, talleres y un hackathon, en temas como femicidios, índice de datos abiertos, herramientas como Python, en ciudades como Rio de Janeiro, Curitiba, Brasilia, Salvador de Bahía, Maceió y Sao Paulo.
Bogotá, Quindio, Nariño en Colombia
Este año varios eventos ocurrirán en territorio colombiano, incluyendo eventos de Open Street Maps, #RallyColombia que es un hackathon para monitorear dinero público organizado por Open Knowledge Colombia, datos sobre lo rural y urbano en Quindio y exposiciones de visualizaciones en Nariño.
Santiago y Concepción en Chile
Este año los chilenos tendrán un Rally de Datos en la Calle: controlando con datos abiertos las obras públicas en Santiago, organizado por Data Chile y también habrá un evento de la comunidad datera en Concepción.
Quito en Ecuador
La comunidad datera ecuatoriana prepara una jornada de charlas, mentorías y talleres en el formato de expedición de datos. No importa si eres experto o no en el tema, Datalat y sus aliados tendrán algo para ti en Quito en el Open Data Day UIO
San Salvador en El Salvador
Además de charlas dateras, los salvadoreños tendrán eventos para abrir datos de investigación y presentación de resultados de transparencia en comprar públicas.
Ciudad de Guatemala en Guatemala
En este año el evento girará alrededor de contratos abiertos y dineros públicos, con varios proyectos que han sido desarrollados en estos últimos meses y con la idea de generar nuevos proyectos, pronto compartiremos más info en nuestras redes @escueladedatos
Ciudad de México, Veracruz, Jalisco y más en México
Habrá muchas actividades que van desde expediciones de datos, charlas, talleres hasta el Rally de #DatosEnlaCalle, que tiene increíbles premios. Revisa la web de SocialTIC para estar actualizado de los eventos en Ciudad de México, también hay evento en Veracruz y Jalisco.
Managua en Nicaragua
En Managua no te puedes perder el mapathon del norte del país que ayudará a la Asociación Mujeres Constructoras de Condega.
Lima en Perú
En Lima, un grupo local analizará los contratos del caso Lava Jato a nivel local y nacional, más información en Convoca.
Montvideo y Paysandú en Uruguay
Además del tradicional encuentro en la capital Montevideo, por segundo año consecutivo los uruguayos y argentinos buscarán desde los Datos Abiertos atender la problemática de las inundaciones del Río Uruguay. No te pierdas la hackathon de Paysandú
![]()

En un espacio dinámico para compartir experiencias, ideas e iniciativas realizamos dos expediciones de datos con toques un poco diferentes. La primera estaba enfocada a la visualización. Llevamos al espacio físico ideas abstractas y tablas de datos que suelen estar poco accesibles cuando no son llevadas a lo visual. La segunda estaba enfocada al análisis a través de programación y código.
Ambos grupos trabajaron con datos del programa Monitoreo Ciudadano que Hivos realiza en la prevención y atención de grupos vulnerables a la epidemia del VIH.
La plática
Para empezar el Visualizatón, hablamos sobre cómo visualizar información implica apuntar con un dardo a un propósito. “Visualizamos datos porque esto nos permite explicar mejor, reducir el esfuerzo cognitivo y facilitar la generación de conocimiento” fueron los mensajes claves de una primera charla que yo guié.
Luego, Sergio Araiza (México) nos acompañó para hablar sobre las narrativas y cómo la difusión de datos clave se puede nutrir con el uso de símbolos, contrastes e imágenes que nos hagan “ver la historia que los datos cuentan de una manera tan fácil y directa como una fotografía”.

La práctica
Luego de dividirse en los dos grupos, llegó la hora de trabajar.
Al primer grupo le esperaba una mesa llena de cartulina, estampas, marcadores y otros materiales que les permitiría llevar a lo físico esas ideas que estuvieron desarrollando a lo individual. Eran aproximadamente 60 personas entre las cuales habían trabajadores municipales invitados al evento por el Instituto Republicano Internacional, estudiantes universitarios y personas poco familiarizadas con el uso de datos.

Al segundo grupo lo esperaban mesas y conexiones para que llegaran con sus computadoras a trabajar y seguir la serie de ejercicios y retos que les tenían preparados. Partiendo de la misma información, esta sesión estaba enfocada en analizar estos datos pero utilizando código y fue liderada por Sebastián Oliva, programador y fellow de Escuela, junto al cientista de datos especializado en salud, Kevin Folgar.
Con un grupo de programadores y cientistas sociales que sabían usar código, Sebastian y Kevin repasaron cómo funcionan los tipos de datos y cómo manipularlos a través de Python.
Para ello utilizaron Pandas —la librería que permite operar y analizar tablas numéricas y series de tiempo— y los Notebooks de Jupyter —que permiten escribir, correr, combinar y republicar código—.
Con estas habilidades lograron hacer ejercicios en los que agruparon y filtraron los datos del programa de monitoreo en salud para también generar cálculos a través de tablas dinámicas.
Los resultados
Lo que queríamos lograr con el Visualizatón era que los usuarios poco acostumbrados a manejar datos perdieran el miedo, analizaran de qué manera enfocar la información y la pudieran plasmar de una manera creativa para luego explicarle al grupo un detalle o una situación particular de este conjunto de datos.

Al segundo grupo lo esperaban mesas y conexiones para que llegaran con sus computadoras a trabajar y seguir la serie de ejercicios y retos que les tenían preparados. Partiendo de la misma información, esta sesión estaba enfocada en analizar estos datos pero utilizando código y fue liderada por Sebastián Oliva, programador y fellow de Escuela, junto al cientista de datos especializado en salud, Kevin Folgar.
Con un grupo de programadores y cientistas sociales que sabían usar código, Sebastian y Kevin repasaron cómo funcionan los tipos de datos y cómo manipularlos a través de Python.
Para ello utilizaron Pandas —la librería que permite operar y analizar tablas numéricas y series de tiempo— y los Notebooks de Jupyter —que permiten escribir, correr, combinar y republicar código—.
Con estas habilidades lograron hacer ejercicios en los que agruparon y filtraron los datos del programa de monitoreo en salud para también generar cálculos a través de tablas dinámicas.
Los resultados
Lo que queríamos lograr con el Visualizatón era que los usuarios poco acostumbrados a manejar datos perdieran el miedo, analizaran de qué manera enfocar la información y la pudieran plasmar de una manera creativa para luego explicarle al grupo un detalle o una situación particular de este conjunto de datos.

Aunque el segundo grupo estaba mucho más familiarizado al análisis de datos, no conocían muchas de las funciones que el lenguaje Python nos permite construir. Entre todos fueron siguiendo los ejercicios, conociendo las librerías y evaluando en qué ocasiones cierto código soluciona los problemas que encontramos en cualquiera de los pasos del Data Pipeline.
Sobre el festival de Gobierno Abierto
Esta fue la primera edición del Festival de Gobierno Abierto en Guatemala. Escuela de Datos se unió a este esfuerzo en otras actividades también y a lo largo del Festival participamos en distintas mesas y charlas.
Sergio Araiza moderó un conversatorio sobre cómo el periodismo se ha vuelto más colaborativo e involucra a otros actores para compartir métodos, datos y verificaciones. A él se le unieron dos de los cuatro proyectos que la fellowship de Escuela de Datos en este año ha asesorado para aplicar el Open Contracting Standard. “La colaboración, los datos abiertos y la tecnología permiten intercambiar conocimiento que mejore los procesos y niveles de investigación desde los medios de comunicación en el mundo digital” fue una de las conclusiones”.
Por la noche, los becados al festival de otros municipios y algunos de El Salvador y Honduras pudieron tener una plática más abierta sobre tecnología cívica y de qué manera su uso puede ayudarles a solventar los problemas que afligen a sus ciudadanos.
Aprovechamos la oportunidad para recordarles a todos que existen los “10 mandamientos del Open Data” y hubo siempre una oportunidad para aprender en medio de las bromas del #OpenDataJesus. Y para cerrar, aprovechamos que en el festival también estaba otro personaje, el #OpenGovJedi para predicar a todas las galaxias que los datos tienen un rol importante para transparentar la gestión pública y fortalecer la participación de los ciudadanos en sus instituciones.

Este evento fue organizado por los proyectos Munis Abiertas y Congreso Transparente, con el apoyo de la DW Akademie, quienes nos invitaron e incluyeron en la agenda. Para saber más sobre todas las actividades que esta maratón de Gobierno Abierto incluyó puedes seguir el hashtag #FGA en twitter.
![]()
 En los últimos años, una cantidad creciente de información sobre los sectores mineros y petroleros se ha estado poniendo a disposición del público. Sin embargo, esta información puede ser difícil de encontrar, sistematizar e interpretar; ya sea para usarla en análisis, investigación, activismo o incluso implementar proyectos con datos.
En los últimos años, una cantidad creciente de información sobre los sectores mineros y petroleros se ha estado poniendo a disposición del público. Sin embargo, esta información puede ser difícil de encontrar, sistematizar e interpretar; ya sea para usarla en análisis, investigación, activismo o incluso implementar proyectos con datos.
En este taller en el marco de Condatos en Costa Rica, colaboramos con el Instituto para la Gobernanza de los Recursos Naturales (NRGI) y nos enfocaremos en un tipo concreto de información disponible de distintas fuentes: los pagos de las empresas mineras y petroleras a los gobiernos de los países productores de estos recursos naturales. Estos están desagregados por empresa, por país, por proyecto y por tipo de pago (regalías, impuestos, etc.)
¿Dónde encontramos esta información? ¿Qué significa? ¿Para qué la podemos usar?
Si te interesa saber la respuesta a estas preguntas, analizando casos concretos de proyectos mineros y petroleros en el Perú y en Colombia, ¡participa en el taller!
- Fecha: Viernes, 25 de agosto, 2017
- Lugar: Centro Nacional de la Cultura (CENAC), San José, Costa Rica.
- Horario: 9am – 11am
Sobre los facilitadores:
Claudia Viale
Licenciada en Economía por la Pontificia Universidad Católica del Perú, con una maestría en Gestión de Recursos Naturales y Medio Ambiente de la Universidad Libre de Amsterdam. Es Oficial de Programa del Instituto para la Gobernanza de los Recursos Naturales (NRGI), encargada de coordinar los proyectos de investigación relacionados a las industrias extractivas para la región América Latina. Ha trabajado temas como la distribución de los ingresos fiscales de la minería y los hidrocarburos a gobiernos subnacionales, su gasto e impacto en las economías locales.
Julio López Peña (@jalp_ec)
Economista ecuatoriano, investigador-consultor en el sector de energía, datos abiertos, y recursos naturales. Ha participado en varios proyectos en América Latina con el Banco Interamericano de Desarrollo (BID), la Organización Latinoamericana de Energía (OLADE) y varias ONGs y think tanks. Es fellow de la generación 2015 de Escuela de Datos y co-fundador de Datalat, desde donde ha trabajado con ciudadanos, organizaciones civiles y periodistas en el uso de datos abiertos en Ecuador y la región. Julio estudió una maestría en gestión de energía y recursos de la Universidad Colegio de Lóndres (UCL).
![]()

El 11 de marzo el evento estrella de Escuela de Datos y SocialTic llegó por primera vez a España después de decenas de rondas exitosas en Latinoamérica.
Las cañas fueron la excusa para reunir a periodistas de los medios y proyectos con periodismo de datos más importantes del país y conocer sus mejores trabajos.
Las cañas del Café de Ruiz fueron patrocinadas por El Faro y SocialTic, quienes representaron a Latinoamérica durante esa noche.
#DatosYcañas lleno de compañeros de medios y proyectos para hablar de periodismo de datos, hacktivismo, transparencia pic.twitter.com/rTwkkwtE0Z
— Juan Luis Sánchez (@juanlusanchez) 11 de marzo de 2017
Estas fueron las presentaciones:
El Confidencial – Crear bases de datos propias
Daniele Grasso, jefe de la unidad de datos, utilizó como ejemplo El Prometómetro, el trabajo sobre feminicidios y el comparador de tallas de ropa para explicar como en su medio crean temas a partir de bases de datos hechas desde cero por el equipo.
.@danielegrasso contando como dejan libres las bases de datos con las que trabajan para que los demás las puedan consultar ? #DatosYCanas
— Clara Jiménez Cruz (@cjimenezcruz) 11 de marzo de 2017
Eldiario.es – Los papeles de la Castellana
Juan Luis Sánchez, subdirector, y Raúl Sánchez, periodista de datos, presentaron las investigaciones sobre amnistía fiscal realizadas a partir de una filtración en el buzón seguro Filtrala.
Con #DatosyCañas aprendiendo de periodismo de datos con @eldiarioes en @cafederuiz #Madrid pic.twitter.com/kOwIXmzMyU
— Lidia García (@liligargar) 11 de marzo de 2017
Ana Tudela y Antonio Delgado, fundadores del proyecto, presentaron el trabajo que empezó hace algunos meses en el nuevo portal. Sus trabajos pueden ser a corto, mediano y largo plazo, con una sección de investigaciones basadas en datos abiertos.
.@danielegrasso @elconfidencial @juanlusanchez @raulsanchezglez @eldiarioes Turno en #DatosYCañas para @latule y @adelgado con su proyecto @datadista pic.twitter.com/udWodQ2y5e
— Stéphane M. Grueso (@fanetin) 11 de marzo de 2017
El Mundo – Football Leaks
Paula Delgado, periodista de El Mundo Data, presentó las lecciones que obtuvo después de la investigación transnacional que reveló, por ejemplo, algunos documentos fiscales del futbolista Cristiano Ronaldo.
Lecciones de #footballeaks en #DatosYCanas pic.twitter.com/clP1XXmLm6
— daniele grasso (@danielegrasso) 11 de marzo de 2017
El Faro
José Luis Sanz, director de El Faro, que patrocinó este evento también presentó los proyectos con datos realizados por el medio salvadoreño. Uno de los proyectos que más llamó la atención fue El Retrato de la Desigualdad que consistió en un levantamiento de datos autónomo para mostrar la movilización de 24 jóvenes en San Salvador.
#DatosYCanas aquí @jlsanz presentando retrato de la desigualdad. Proyecto basado en levantamiento de datos autónomo pic.twitter.com/FmmYtkXTKg
— Metz (@mexflow) 11 de marzo de 2017
Los aires del cáncer – Máster de periodismo de investigación, datos y visualización de El Mundo
Manuel Varela, ex estudiante del máster, presentó la investigación que realizó como trabajo final del curso acerca de cómo el cáncer de pulmón aumenta en las zonas industriales con mayor contaminación en el aire.
En #DatosYCanas @manuel_varfar cuenta su proyecto sobre el cáncer, a partir de datos del INE. Lo podéis leer aquí: https://t.co/GOCLotILnU pic.twitter.com/GjFYjgHF8A
— daniele grasso (@danielegrasso) 11 de marzo de 2017
Maldito Bulo
(https://twitter.com/malditobulo?lang=en)
Clara Jiménez y Julio Montes, fundadores también de Maldita Hemeroteca, presentaron cómo identificar “fake news”, las razones por las que se crean y cómo medir la cantidad de mentiras de un medio de comunicación.
#DatosYCanas presentando @malditobulo (bulo =mentira) cómo medir las mentiras de un medio #respect pic.twitter.com/TDEZXOplha
— Metz (@mexflow) 11 de marzo de 2017
El País – The New Arrivals
http://elpais.com/agr/la_odisea_de_los_nuevos_europeos/a
Guimar del Ser, periodista de El País, presentó el trabajo hecho en conjunto con The Guardian y Der Spiguel que usa la historia de un equipo de fútbol integrado por refugiados en Jerez de la Frontera, España para plantear un escenario general con datos sobre la situación de los refugiados en Europa
@elpais_espana trabaja innovando en inmigración y datos en #DatosYCanas @cafederuiz pic.twitter.com/yagvG6wlFv
— Lidia García (@liligargar) 11 de marzo de 2017
Populate Tools – portal de peticiones de información
Martín González, de la empresa Populate Tools, presentó el portal de código abierto para realizar peticiones de información a el gobierno español, aunque puede adaptarse a cualquier país.
#datosycanas el equipo de @PopulateTools presentando peticiones abiertas. Una caña a su salud sin duda pic.twitter.com/qv4nWwoDmC
— Metz (@mexflow) 11 de marzo de 2017
![]()
Con ella, te lo prometo, pasarás menos tiempo limpiando y más tiempo analizando tus datos a la hora de elaborar bases de datos. ¿Te animas a probarla? Bueno, pues, lee y te cuento cómo la probé con una tabla de datos, sobre las primeras tres jornadas de CONCACAF 2016-2017, que extraje de Mismarcadores.com.
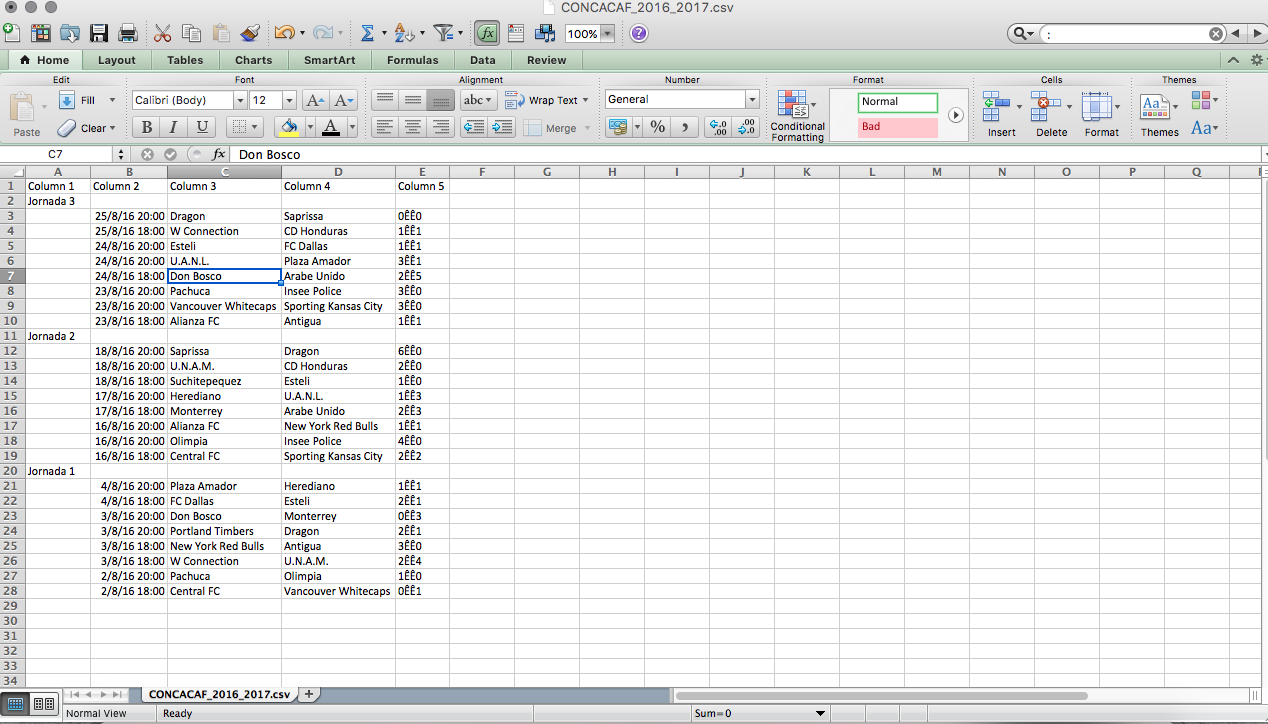
¡Menor tiempo, mejor limpieza!
Un profesor en la «U» solía decirme que, lo bueno si breve, dos veces bueno. Y eso es lo que evoca Wrangler al momento de utilizarlo. Para comenzar, ingresa a http://vis.stanford.edu/wrangler/, donde encontrarás un botón al que hasta el más curioso y entusiasta datero dará clic con su provocativo Try It Now (¡Pruébala ahora!).
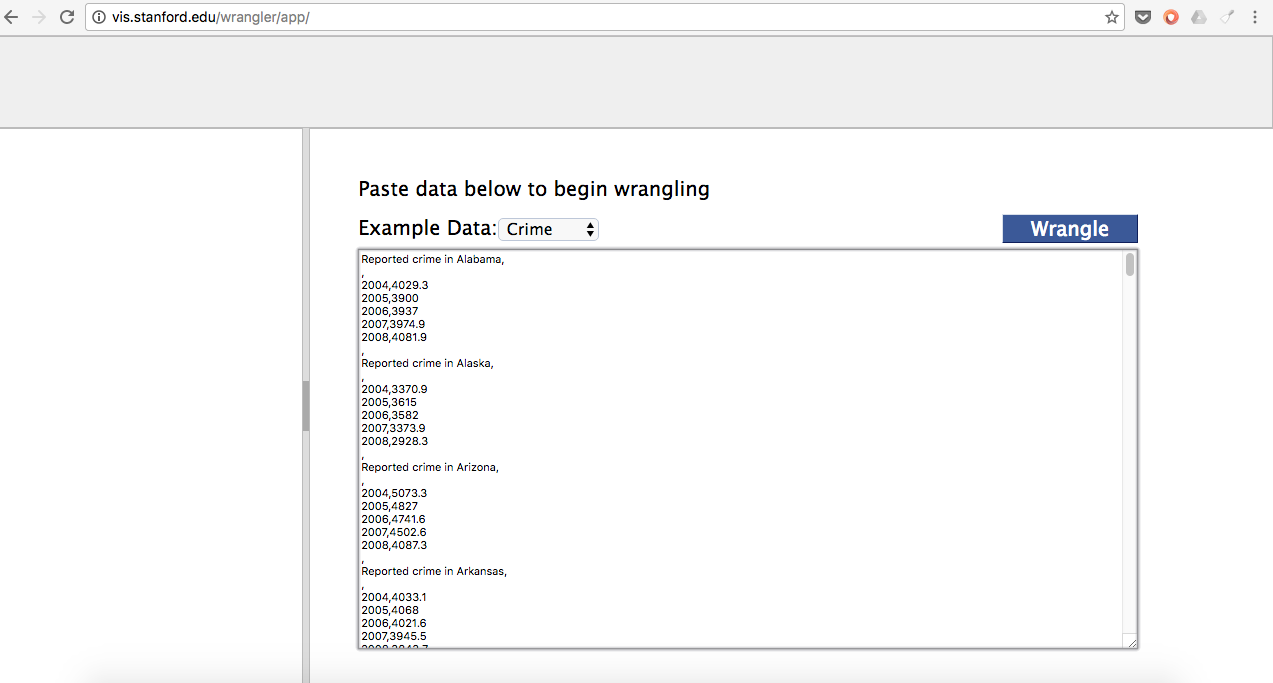
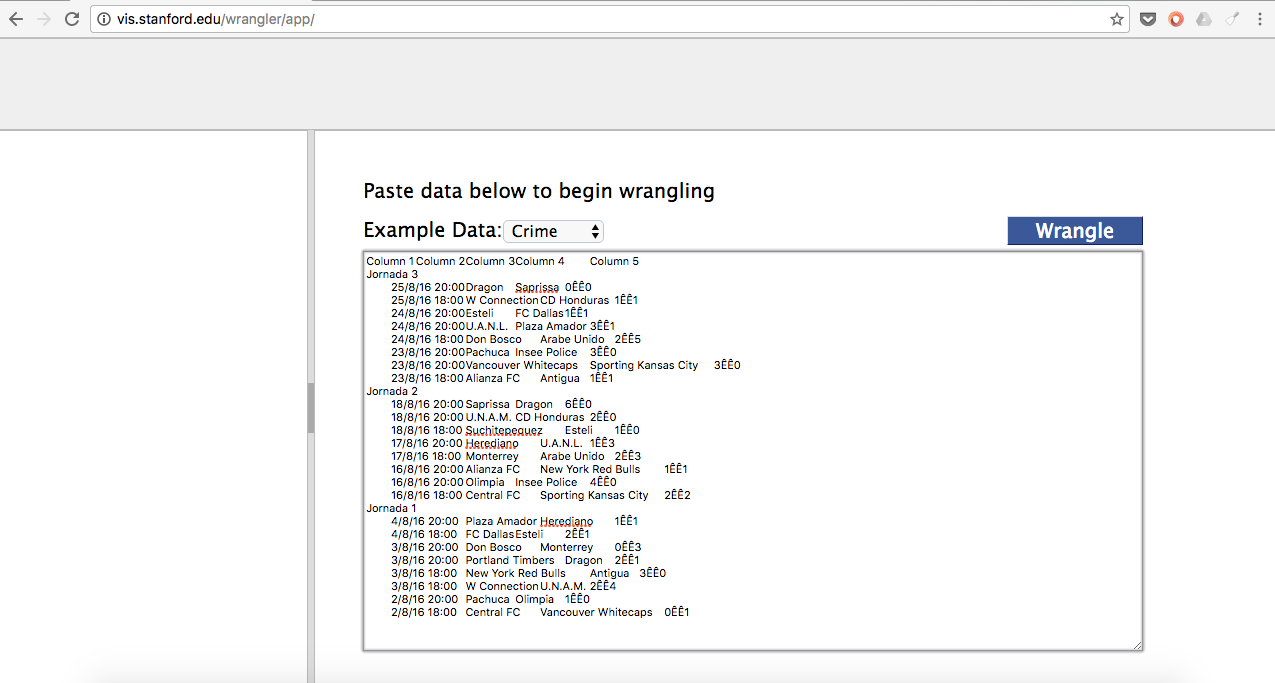
Como verás a continuación, la interfaz de Wrangler es sencilla. Un poco primaria para algunos, pero los resultados son prometedores para quienes deseamos limpiar datos rápido y bien. ¿Ves cómo está la tabla? Fea, ¿verdad?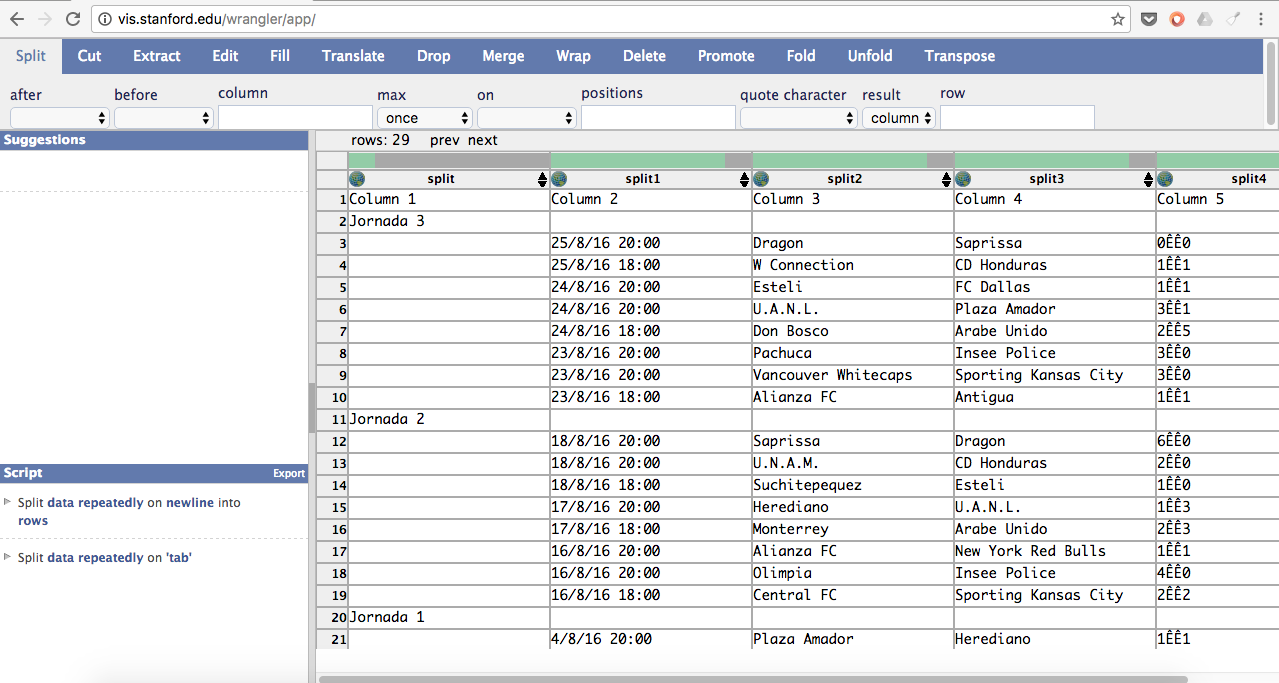
Para mejorarla, lo primero que hice fue seleccionar la primera fila de la tabla y acudí al auxilio de la opción Promote para que la primera fila sea el encabezado de cada una de nuestras columnas. Así, ya tenemos un encabezado con el cual la carpintería datera puede comenzar. ¡Eso sí! Para cambiar cada uno de sus nombres puedes dar doble clic y ¡listo! ¡Ya tienes categorías!
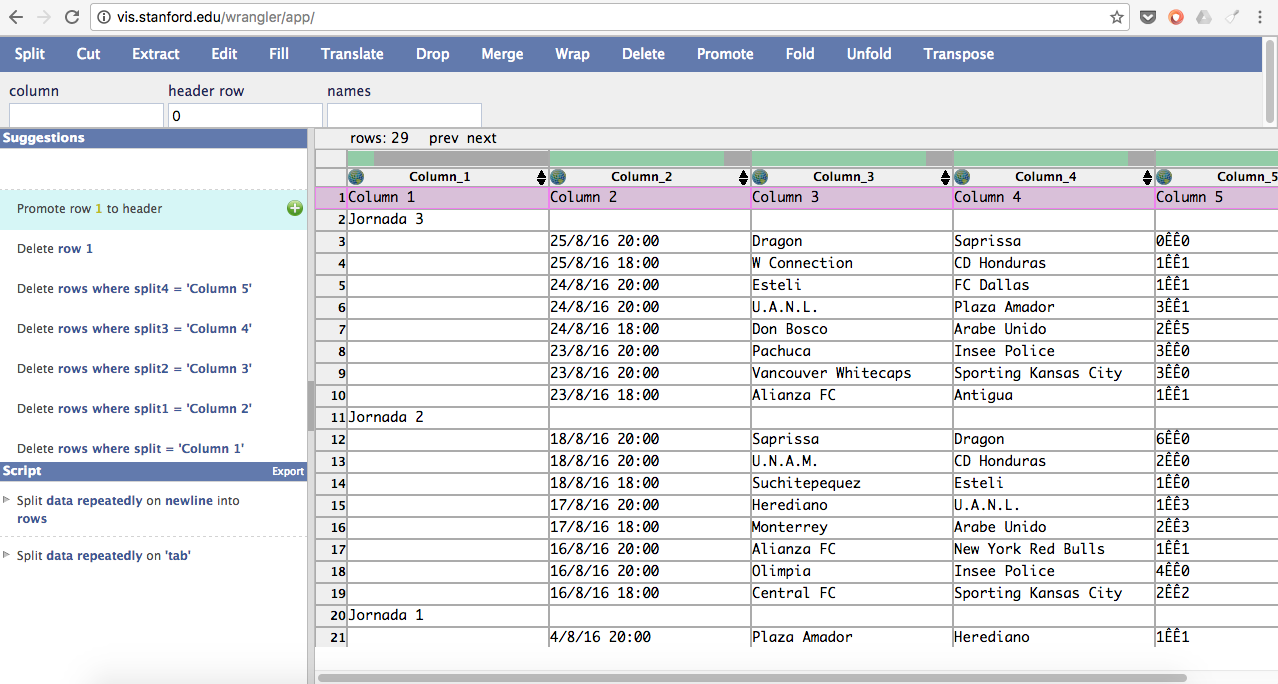

Ahora, rellenemos los espacios en blanco de cada jornada. Para eso, sombreé la columna JORNADA. Y me fui a la opción Fill, con la cual puedes reemplazar las columnas/filas en blanco por insumos de valor. Para este caso, le indiqué que debía rellenar todo espacio debajo de JORNADA que estuviera en blanco.
¿Cómo? Colocando lo siguiente en su barra de opciones:
Column JORNADA
Direction: above
Row: JORNADA is null
Finalizado esto, aparecerá una opción con nuestros comandos en el menú SUGGESTIONS. Dale clic al signo de «más» y verás cómo empieza a tomar forma la cosa.
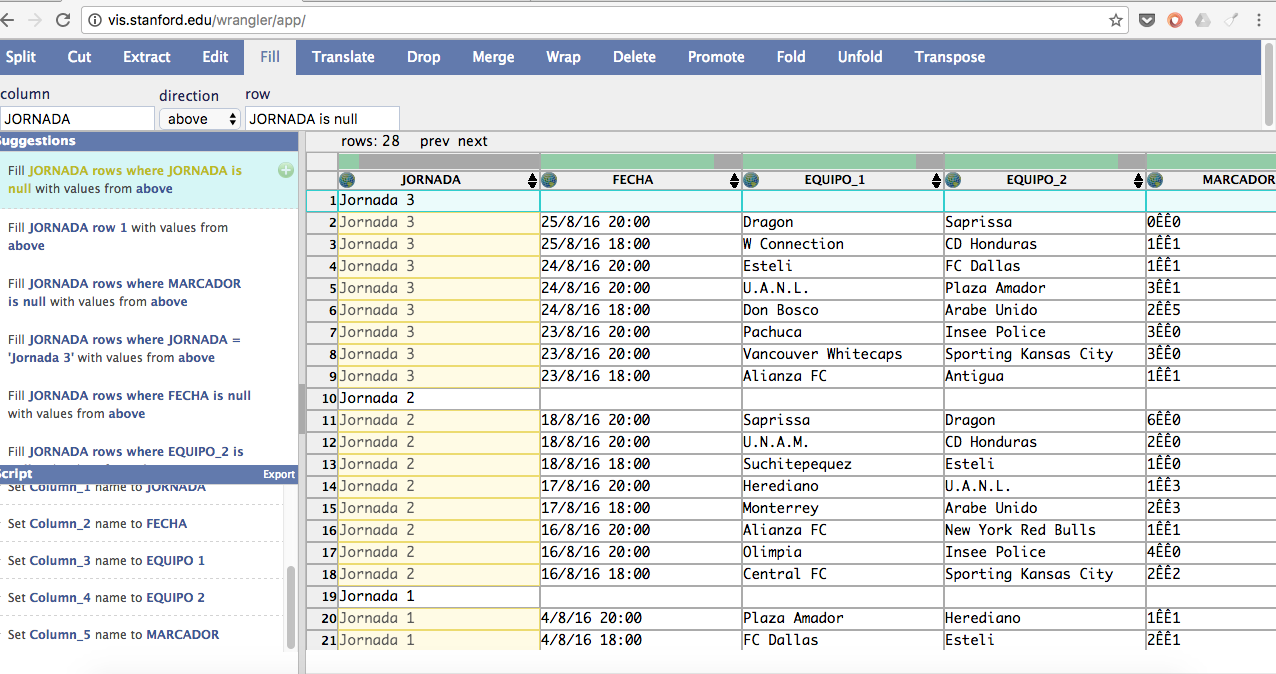
Sí, yo también vi esas filas en blanco que no aportan nada en cada JORNADA. Para eliminarlas, selecciona cada una de las columnas e ingresa a la opción DELETE, donde podrás prescindir de cada una de ellas en el menú de la izquierda, dando clic al signo más en el menú SUGGESTIONS.
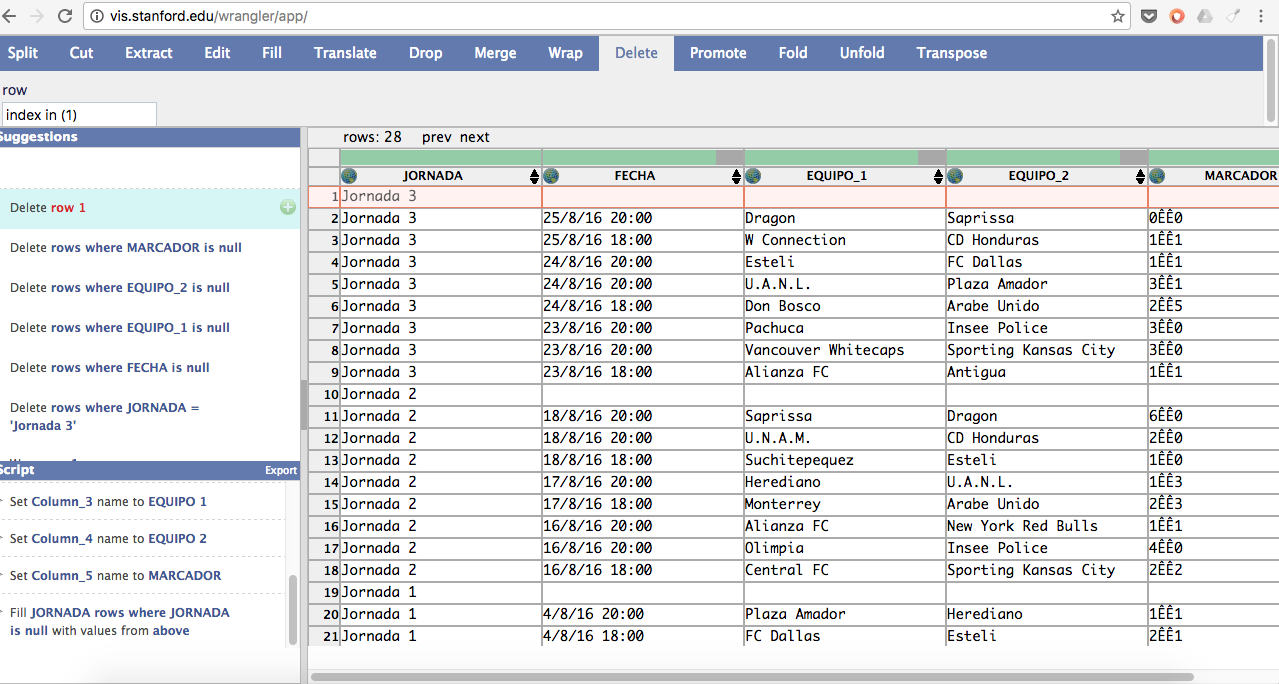
Mejor, ¿no? Ahora, tenemos otra piedrita en el camino: ¡Fecha y hora están unidas! Pero, que no panda el cúnico. Para separarlas, me di a la tarea de hacer lo siguiente:
1) Seleccioné la columna FECHA
2) Fui a la opción SPLIT y coloca WHITESPACE en la variable after.
3) Y voilá…

¡Eso sí! No pases por alto cambiar las columnas SPLIT a FECHA y HORA respectivamente. Ahora, veo que el MARCADOR está igual de sucio. Por tanto, tendremos que separar cada uno de esas ÊÊ que les mantienen unidos. ¡Empecemos entonces! Yo comencé por el marcador del equipo 2 e hice esto:
1) Sombreé la columna MARCADOR
2) Fui a la opción SPLIT y coloca ÊÊ en la variable after.
3) ¡Listo! ¡Ya me lo separó!
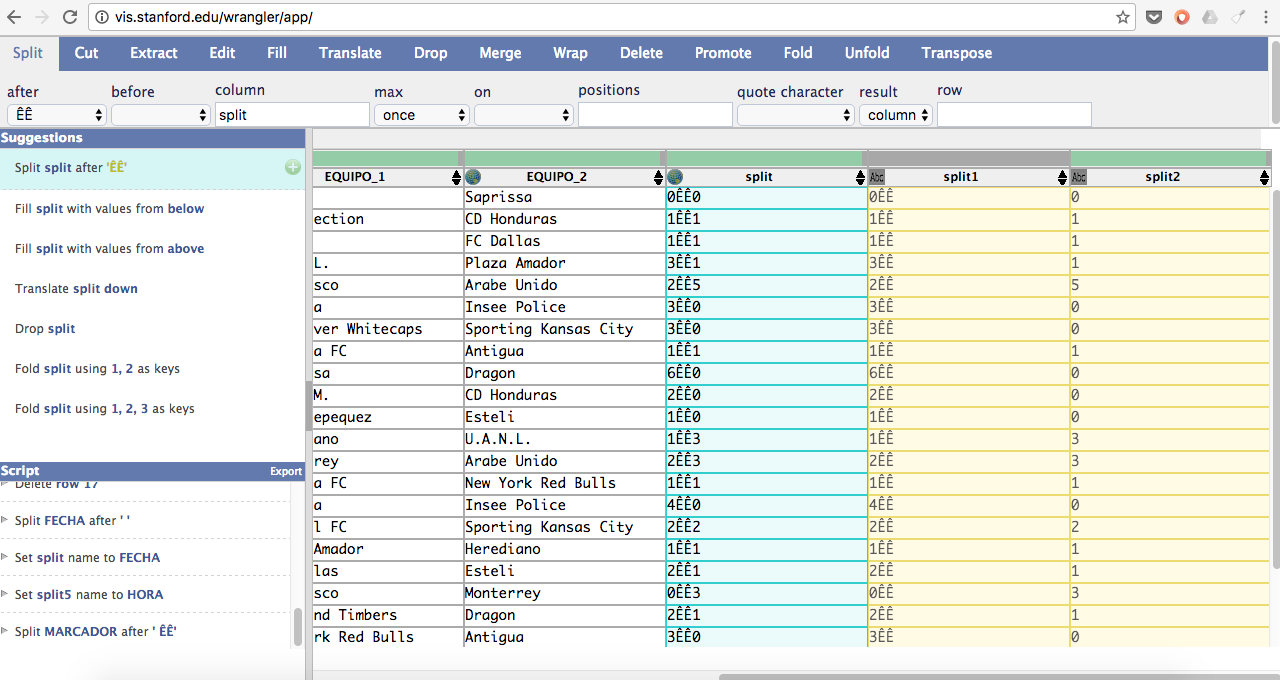
Ahora, viene lo mejor: ¿cómo quitamos esas ÊÊ del marcador del equipo 1? Antes de separar, sombreemos las ÊÊ y sígueme con lo siguiente:
1) Vamos a la opción SPLIT
2) Coloquemos ÊÊ en la opción on
3) ¡Mira qué padre! ¡Nos separó las ÊÊ del marcador!
4) ¡No olvides renombrar la columna separada como MARCADOR EQUIPO 1!

¡Solo nos queda prescindir de la columna en blanco del anterior SPLIT! Y, para eso, ve a la opción DROP y dale clic a la primera opción que te presenta el menú SUGGESTIONS.
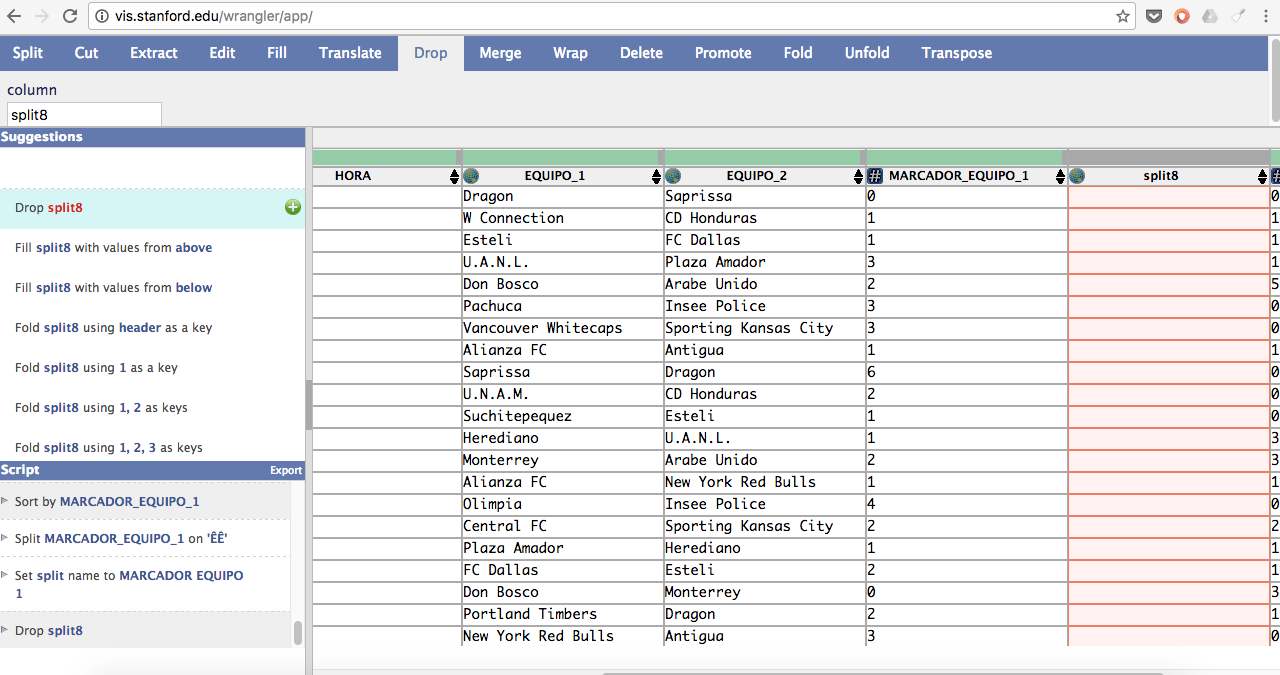
¿Qué hacemos ahora? Ve a la opción EXPORT que se encuentra debajo de SUGGESTIONS y haz clic. Te saldrá una pantalla con la tabla de datos limpia. Copíala y llévala a tu Text Edit (Mac) o Bloc de Notas (Windows). Pega el archivo y guárdalo como un texto sin formato con extensión .csv.
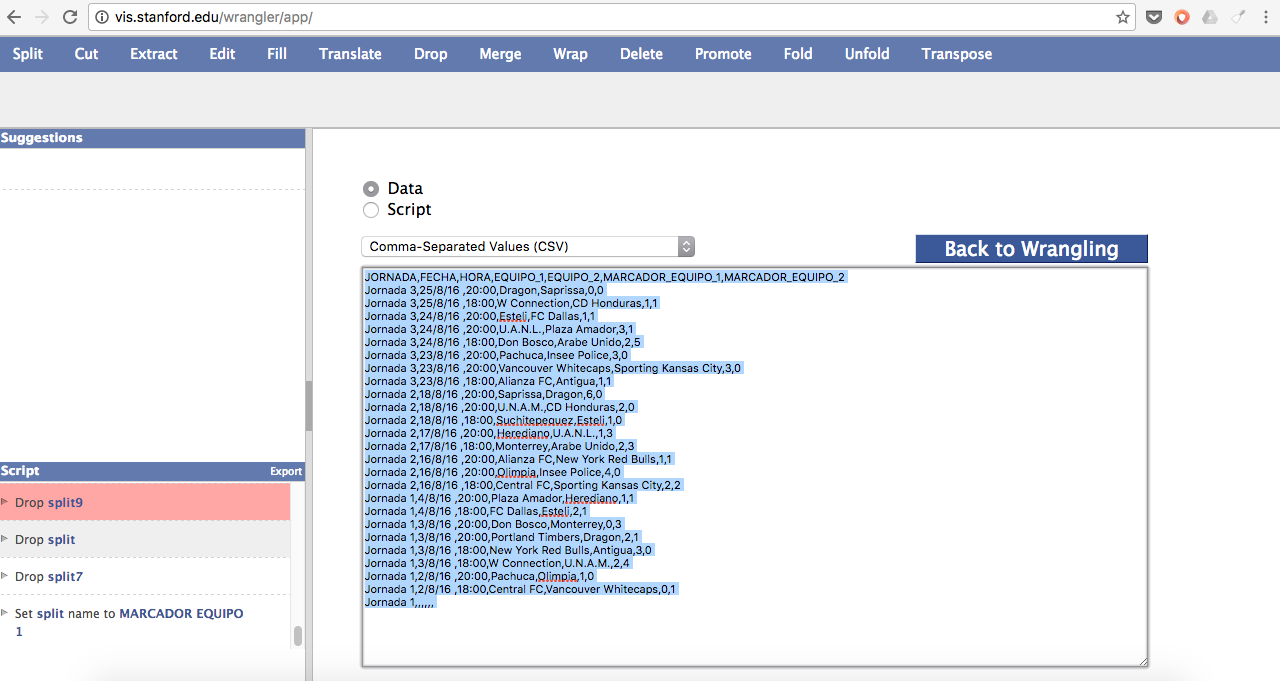
Ahora, si la curiosidad te mata como a mí me pasó, abrí el .csv en Excel… ¡Y este fue el resultado!

¡Justo algo con lo cual podemos trabajar! ¡Gracias por oír mis plegarias dateras, Wrangler!
¿Por qué confiar en Wrangler?
«¿Para qué tanto problema?», dijo sabiamente Juan Gabriel. Y yo le creo… yo te invito a darle un voto de confianza a Wrangler. ¿Por qué? Porque me ha pasado que se me va el tiempo (¡y la vida!) manipulando datos exclusivamente para que las herramientas de visualización y análisis las leen. Pero, ¡oh, sorpresa! Muchas veces, el resultado no es el esperado porque la limpieza no fue lo que yo deseaba.
Y, en esos deseos de cosas imposibles, Wrangler está diseñadas para acelerar esos procesos; más, si tienes a un editor o a tu jefe exigiendo bases de datos y visualizaciones rápidas y bien ejecutadas. Con este insumo, pasarás menos tiempo lidiando con tus datos y mucho más aprendiendo de ellos al tener las preguntas correctas que te ayuden a sustentar/refutar hipótesis de periodismo de datos.
También, te permite la transformación interactiva de información sucia que puedes encontrar a diario en insumos de análisis para cualquier proyecto en el cual te encuentres trabajando. Y, lo que más me encanta, te ayuda a exportar datos para su utilización en mis dos inseparables amigos: Excel o Tableau. ¡Yeeeeeeeeeeeeeey!
Por los registros, ¡no te preocupes! Una vez exportes la data trabajada, la herramienta volverá a su fase original con las bases precargadas (¡otra razón para amarte, Wrangler!). Ya si esto no te convence, anímate a probarla y compartirnos qué te parece y que no. ¡No te quedes con las ganas y comparte con nosotros tus impresiones acá o en nuestro Twitter (@EscueladeDatos)! ¡Cambio y fuera!
![]()

Bolivia CC by SA NC MM
¿Cuánto invierte el municipio en seguridad ciudadana, cuánto ha crecido la tala de árboles en los últimos años, cuántas lenguas indígenas se hablan por ciudad? El qué, cómo, cuándo y cuánto son preguntas en torno a las que gira la labor de organizaciones de la sociedad civil, activistas y estudiantes.
Dar respuesta a estas indagaciones viene de la mano del aprovechamiento de los datos existentes para generar valor e incidencia pública a partir de los hallazgos.
Por ello, con Escuela de Datos organizamos el “Tour Datero Bolivia” que se realizará este mes de agosto en las ciudades de Santa Cruz, Cochabamba, El Alto y La Paz. En cada ciudad hay espacio para 40 participantes.
El objetivo de esta serie de eventos es descubrir lo que los datos pueden mostrar a través de la capacitaciones y mentorías en depuración, análisis y representación de los datasets en formatos abiertos, cómo crearles valor, de qué forma pueden ser aprovechados; todo ello sobre la base de dudas y planteamientos propios de las organizaciones, y a partir de datos generados por organizaciones públicas y no gubernamentales en Bolivia.
Cuatro ciudades
Si estás en cualquiera de las ciudades que enlisto, puedes participar de talleres, expediciones de datos, mentorías a iniciativas o sesiones más ligeras acompañadas de una bebida.
Este es el calendario para escoger tu actividad, todos los eventos son gratuitos. Solamente recuerda que es requisito registrarse en el formulario correspondiente hasta el sábado 13 de agosto a las 20:00 (GMT -04:00).
Primero en Santa Cruz
Dos eventos abiertos y gratuitos orientados a colectivos, activistas, organizaciones de la sociedad civil y personas interesadas en mejorar sus capacidades para usar los datos de manera efectiva y eficiente.
Para cualquiera de ellos debes registrarte en este enlace: http://bit.ly/SantaCruzTourDatero
Solo requieres llevar tu laptop.
Cómo dar valor a los datos desde organizaciones de la sociedad civil
Dónde: Fundación Trabajo Empresa, Calle Moldes esquina Cobija (Edificio Telecentro Santa Cruz).
Fecha: 16 y 17 de agosto
Hora: 9:00 a 18:00 y de 10:00 a 13:00
Qué verás: 16/08 Taller con ejercicios prácticos para que los asistentes puedan absorber los conocimientos sobre los lineamientos básicos y el proceso para la utilización de datos abiertos.
17/08 Sesiones de mentoreo para iniciativas que deseen crear valor y aprovechar los datos abiertos para sus organizaciones y proyectos.
Organiza Escuela de Datos; apoyan Colectivo Rebeldía y Fundación Trabajo Empresa.
También “Datos y Cervezas” el 16 de agosto desde las 20:00 en La Esquina del Cronopio (calle Colón esq. Lemoine); conoce proyectos de datos abiertos (emergentes y consolidados) a nivel regional compartiendo una cerveza.
Cochabamba, tecnologías y género
En Cochabamba, nos lucimos con una serie de eventos de van desde la capacitación y expedición de datos con temas de género hasta sesiones más ligeras de mentoría de iniciativas o solamente hablar de datos comiendo un picado. Si tu interés está en temas de género o simplemente quieres aprender cómo trabajar con datos, registrate en este enlace: http://bit.ly/TourDateroCochabamba. Para el caso de la capacitación y expedición de datos, el equipo coordinador tomará contacto contigo para confirmar tu participación.
Solo requieres llevar tu laptop.
Datos que narran la violencia de género
Dónde: Centro de Estudios Superiores Universitarios, Calle Calama 235
Fecha: 18 y 19 de agosto
Hora: 9:00 a 18:00
Qué verás: 18/08 Taller con ejercicios prácticos para que los asistentes puedan absorber los conocimientos sobre los lineamientos básicos y el proceso para la utilización de datos abiertos.
19/08 Expedición de datos a partir de datos sobre violencia de género de organizaciones públicas y no gubernamentales para producir narrativas, visualizaciones y otros productos.
Organiza Cuántas Más, Escuela de Datos y SLIM Cochabamba; apoyan CESU-UMSS, Coordinadora de la Mujer, Udabol.
Conversatorio sobre Nuevas Tecnologías e Investigación en Ciencias Sociales
Dónde: Centro de Estudios Superiores Universitarios, Calle Calama 235
Fecha: Jueves 18 de agosto
Hora: 19:00
Organiza Cuántas Más, Escuela de datos , CESU-UMSS
También “Picando Datos” el 19 de agosto desde las 20:00 en Café Bistró El Caracol (calle Mayor Rocha Nº 286 casi esquina España); conoce proyectos de datos abiertos (emergentes y consolidados) a nivel regional acompañado de picados.
Mentoría express
Dónde: Centro de Estudios Superiores Universitarios, Calle Calama 235
Fecha: 20 de agosto
Hora: 09:00 a 12:00
Qué verás: Mentoría para iniciativas que deseen crear valor y aprovechar los datos abiertos para sus organizaciones y proyectos.
Organiza Escuela de Datos y Cuántas Más.
Estudiando en El Alto
Si vives en El Alto y estudias en comunicación, periodismo, sistemas e informática y diseño, o eres parte de colectivos activistas u otras organizaciones de la sociedad civil y principalmente; este evento te interesa. De la A a la Z, aprenderás los elementos esenciales para empezar tu trabajo con datos desde un enfoque de aplicación con datos de la vida real.
Debes registrarte en este enlace para participar: http://bit.ly/TourDateroElAlto
Solo requieres llevar tu laptop.
Cómo y dónde empezar a trabajar con datos
Dónde: Casa de las Culturas Wayna Tambo, Zona de Villa Dolores Calle 8 No 20
Fecha: 22 de agosto
Hora: 9:00 a 18:00
Organiza Escuela de datos; apoya La Pública y Wayna Tambo.
Qué verás: Taller con ejercicios prácticos para que los asistentes puedan absorber los conocimientos sobre los lineamientos básicos y el proceso para la utilización de datos abiertos.
Las experiencias de La Paz
En La Paz nos enfocaremos en los proyectos e iniciativas ciudadanas que ya empezaron a tomar impulso con dos eventos: el primero más relajado para conocer lo que se está haciendo en cuanto a datos abiertos en Latinoamérica; y el segundo, una sesión para resolver dudas específicas de cada proyecto.
Debes registrarte en este enlace para participar: http://bit.ly/TourDateroLaPaz
Solo requieres llevar tu laptop.
“Datos y Singanis” el 22 de agosto desde las 20:00 en La Obertura Café Arte Rock (Calle Boyacá #2286, sobre Medinacelli. Entre 20 de Octubre y Rosendo Gutiérrez); conoce proyectos de datos abiertos (emergentes y consolidados) a nivel regional más un vaso de singani.
Impulsando iniciativas y proyectos ciudadanos de datos abiertos
Dónde: Bolivia Tech Hub, Av. Sanchez Lima (final) esquina Pasaje Fabiani 2687
Fecha: 23 de agosto
Hora: 16.00 a 19.00
Qué verás: Sesiones de mentoría express para iniciativas que deseen crear valor y aprovechar los datos abiertos para sus organizaciones y proyectos.
Organiza Escuela de datos; colabora Bolivia Tech Hub.
![]()

Aprende en 5 minutos a colaborar aunque no estés en Ecuador
El 16 de abril un terremoto de alrededor de 7.8 grados golpeó la región costera en Ecuador.
La comunidad de Datos Abiertos del mundo y de América Latina se organiza para hacer su contribución con la construcción de un mapa base para labores de rescate, humanitarias y conocimiento para la población en general. Aún queda bastante por hacer.
Si no sabes cómo hacerlo, aprende en cinco minutos con este video de Juan Carlos Calderón en español. No es necesario localizarte en Ecuador, puedes mapear desde cualquier lugar del mundo.
El chat de Telegram donde se discute logística, así como todos los detalles del mapeo están en el documento wiki del Terremoto en Ecuador.
El mapa de Open Street Maps (OSM) se construye primordialmente con la conversión de imágenes satelitales a mapas editables abiertos a través de la herramienta Open Street Maps. A su vez, esta digitalización es convertida en una base de datos abiertos para uso público.
En el documento wiki se describe qué es la comunidad de voluntarios Open Street Maps y el equipo humanitario de OSM (HOT, por sus siglas en inglés), los canales IRC de soporte técnico para comunicarte con los equipos que lo coordinan y otros detalles como el hashtag #MappingEcuador para encontrar información relacionada en Twitter.
El administrador de tareas de OSM prioriza, divide y reparte las tareas pendientes y monitorea las concluidas. Un proyecto está casi completo pero hay más a los que resta mucho para terminar. Ahí puedes sumarte a este mapeo global.
El esfuerzo lo lidera Humberto Yances (HOT) junto con Daniel Orellana (Open Street Maps Ecuador), quien esta mañana lanzó este Hangout donde encontrarás un tutorial básico detallado para mapear desde donde estés. El segundo hangout, con tutorial para mapeo intermedio y edición offline está acá.
Ayuda en campo
En cuanto a la ayuda en sitio, además de Open Street Maps, en el video se detalla cómo usar la plataforma https://mapa.desastre.ec/ que permite enviar y visualizar reportes de problemáticas originadas por el desastre, así como su ubicación geográfica.
Mapa Desastre permite a sus usuarios recibir alertas de acuerdo a la ubicación de su GPS. La información es pública y disponible también para los organismos de socorro.
Otra de las herramientas en sitio es Google Person Finder, repositorio donde puedes encontrar información de personas que buscas en Ecuador u ofrecer información de personas que encuentres.
Con Mapillary y Open Street Map Android Tracker puedes subir fotografías de las zonas de desastre.
Para la comunidad internacional
Si tienes amigos angloparlantes, comparte con ellos este post en School of Data, donde puedes encontrar esta información en inglés.
![]()

Colabora a través de la plataforma Vendata, primer proyecto de datos abiertos en Venezuela
Ipys Venezuela invita a la comunidad datera de Venezuela, periodistas, estudiantes y voluntarios a participar durante el mes de abril y mayo en varios encuentros de liberación de datos públicos a través de Vendata.
Vendata es una plataforma creada para poner al alcance de los venezolanos datos públicos en un formato abierto y reutilizable. En esta primera etapa se estará trabajando con PDFs de la Gaceta Oficial de Venezuela. La Gaceta es el medio de comunicación escrito en el que el Estado venezolano publica sus normas y resoluciones jurídicas. Es el único imperativo con el que deben cumplir diariamente quienes gobiernan. En la Gaceta Oficial está todo. Sin embargo, la única manera de acceder a ella es en papel o a través de archivos digitales en formato PDF. Esto conlleva a que mucha información importante se pierda en el abismo de lo impreso y quede en el olvido.
Nuestra meta
Los interesados en participar en el proyecto ayudarán haciendo scraping de los PDF’s. A cada colaborador se le creará una cuenta en la plataforma y se le dará capacitación para aprender a utilizar la herramienta. Realizaremos encuentros personales o virtuales. Los únicos requisitos son tener una computadora, conexión a Internet y ganas de formar parte de esta comunidad.
A pesar de las dificultades políticas y económicas que enfrenta Venezuela, creemos que juntos podemos cambiar el rumbo de la situación y ayudar, al menos, en la transparencia y en el acceso a la información pública. La situación de opacidad y poca transparencia en los actores que se encuentran en el poder, dificulta las posibilidades de escrutar los diversos sectores de la sociedad, como un ejercicio natural de contraloría, participación social y ejercicio de la democracia.
El cambio es necesario y la aplicación Vendata es una alternativa para romper con la opacidad existente a través de un mecanismo que posibilite la construcción propia de herramientas que permitan defender el derecho del ciudadano a estar informado.
Actualmente, en Venezuela no existe una Ley de Acceso a la Información Pública, pero diferentes representantes de la sociedad civil están haciendo presión para que ello sea posible. El lanzamiento de proyectos como Vendata ayudaría a visualizar la importancia de los datos abiertos y su repercusión en las decisiones gubernamentales, sobre las que la ciudadanía tiene derecho a estar informado.
Los invitamos a unirse a la convocatoria y a ser parte de este proyecto. Para obtener mayor información y postularse enviar un correo a [email protected]
![]()

Periodistas, economistas y desarrolladores, ex fellows del programa Fellowship de School of Data, detallan qué es y cómo se han servido del fellowship para crecer la comunidad de datos en Latinoamérica
Han influido en la rendición de cuentas nacionales de Perú y Costa Rica con publicaciones como Decide por tu Cantón o Cuentas Juradas; han capacitado periodistas para que detallen la confiabilidad de gasolineras, como en Gasolineras honestas, y han contribuido a la vinculación de datos sobre mineras en Perú, a través del Instituto de Gobernanza de Recursos Naturales.
Pero, por encima del alcance de proyectos específicos en los que trabajaron durante el Fellowship de School of Data, los fellows latinoamericanos que hasta ahora han participado evalúan el impacto de su trabajo en términos de su contribución para la creación de una escena local y regional en el uso efectivo de datos, que se une a una red global que tiene el mismo propósito.
Camila Salazar y Julio López, seleccionados de la Fellowship 2015, así como PhiRequiem y Antonio Cucho, en 2014, detallan cómo compartieron sus conocimientos sobre apertura de Datos a una red global de actores sociales, los retos que enfrenta la escena local y las enseñanzas que obtuvieron de sus fellowships, vis a vis la convocatoria para este Fellowship 2016.
Para los participantes, el fellowship fue la oportunidad única o bien para generar escenas locales y regionales de apertura, limpieza y visualización de datos, o de elevar la solvencia técnica de comunidades periodísticas, o contribuir a movimientos de transparencia de recursos naturales, con el soporte de una comunidad global y regional que, además, les otorgó visibilidad a una enriquecedora red de actores sociales.
Periodismo de datos y Datos sobre la industria extractiva son dos de los temas en que ellos se especializaron, y forman parte de los enfoques temáticos de la convocatoria para el Fellowship 2016.
La primera entrega es esta entervista con Camila Salazar, fellow de Costa Rica en 2015
Lee la entrevista con Camila Salazar aquí
La segunda entrega es una relación del proceso de capacitación, principalmente en Centroamérica, de PhiRequiem, fellow de México en 2014.
Lee la entrevista con PhiRequiem aquí
La tercera y penúltima entrega es una entrevista con Antonio Cucho Gamboa, fellow por Perú en 2014, fundador de Ojo Público, Open Data Perú, y un fellowship nacional.
Lee la entrevista con Antonio Cucho aquí
Nuestra última entrega es nuestra entrevista con Julio López, fellow por Ecuador en 2015, quien inauguró lo que hoy una línea temática del fellowship: la extracción, gestión y visualizació de datos sobre recursos minerales.
Lee la entrevista con Julio López aquí
![]()

Fellowship 2016
Postúlate ¡AHORA!
Fecha límite: 10 de marzo 2016
Duración: abril a diciembre 2016
Link: http://bit.ly/fellowship_2016
Escuela de Datos invita a periodistas, sociedad civil y cualquier persona interesada en impulsar la alfabetización de los datos a postularse al programa de Fellows 2016, que abarca de abril a diciembre 2016. Hay hasta 10 selecciones abiertas y la fecha límite para postular es el 10 de marzo, 2016.
¡Postúlate ahora!
Las fellowships son posiciones de 9 meses con entrenadores, especialistas y entusiastas de Escuela de Datos. Durante este periodo de tiempo, los y las fellows trabajan como parte de la red de Escuela de Datos desarrollando nuevas habilidades y conocimientos ya sea relacionados con una temática social, la construcción de comunidades de datos y la formación para alcanzar un mayor uso de datos.
Como parte de este fellowship, nuestro objetivo conjunto es incrementar la alfabetización de datos y construir comunidades de práctica que cuenten con las habilidades en el uso de datos para poder cambiar su entorno.
Una fellowship temática
Para enfocar el entrenamiento y experiencia de aprendizaje de las y los Fellows de Escuela de Datos 2016, este año se contempla un enfoque temático. Como resultado, se priorizará la selección de postulantes que:
- cuenten con la experiencia en y entusiasmo por un área específica en el entrenamiento de datos
-
Muestren vínculos con organizaciones que se desempeñen en un tema específico o muestren que tienen vínculos cercanos con quienes abordan esta temática de manera directa
Estamos buscando a individuos involucrados que ya cuentan con conocimiento profundo de un sector o tema, y que activamente han influenciado el uso de los datos en esa temática dada. Este enfoque permitirá a las y los Fellows iniciar rápidamente actividades y alcanzar lo máximo durante su participación en la Escuela de Datos: ¡nueve meses pasan muy rápido!
Además, ya contamos con organizaciones aliadas dispuestas a apoyar a las y los Fellows interesadas en trabajar los siguientes temas: periodismo basado en datos, industrias extractivas y datos responsables. Estas maravillosas contrapartes orientarán, darán mentoría y brindarán mayor conocimiento en cada uno de estos temas.
< Conoce más sobre el enfoque temático >
Nueve meses para generar un impacto
La Fellowship es de abril a diciembre de 2016 y comprende por lo menos 10 días al mes del tiempo de cada Fellow para trabajar offline y online. La o el Fellow debe fortalecer su comunidad local a través de entrenamientos, apoyando proyectos basados en datos y satisfaciendo sus necesidades para el uso de datos. Virtualmente, la o el Fellow debe participar activamente en la red global de School of Data, compartiendo conocimiento a través de sesiones online, posts en el blog y contribuyendo con la generación y actualización de los recursos de enseñanza de la comunidad. Cada Fellow recibirá un apoyo mensual de $1,000usd por su trabajo.
En mayo de 2016, todos los Fellows seleccionados participarán presencialmente en el tradicional Campamento de Verano (ubicación por definir) en donde se conocerán, compartirán conocimientos y habilidades, aprenderán sobre métodos, tácticas y enfoques de entrenamiento de Escuela de Datos.
¿Qué estás esperando?
Postúlate Ahora
Información clave:
- Fellowships disponibles: hasta 10 fellows, 5 reservados para realizar periodismo basado en datos
-
Fecha límite de postulaciones: 10 de marzo, 2016, medianoche GMT
-
Duración del Fellowship: del 1 de abirl 2016 a diciembre 31, 2016
-
Nivel de actividad: por lo menos 10 días al mes
-
Estipendio: $1,000 usd al mes
Este post es una traducción de https://schoolofdata.org/2016/02/10/apply-now-for-school-of-datas-2016-fellowship/
![]()