Ese tutorial y documentación detallados en Jupyter Notebook fueron escritos por Sebastián Oliva, fellow 2017 de Escuela de Datos por Guatemala. En el webinar lanzado el 28 de junio puedes seguir paso a paso este ejercicio de limpieza y análisis de datos.
Introducción¶
Este es el primero de varios tutoriales introductorios al procesamiento y limpieza de datos. En este estaremos usando como ambiente de trabajo a Jupyter, que permite crear documentos con código y prosa, además de almacenar resultados de las operaciones ejecutadas (cálculos, graficas, etc). Jupyter permite interactuar con varios lenguajes de programación, en este, usaremos Python, un lenguaje de programación bastante simple y poderoso, con acceso a una gran variedad de librerias para procesamiento de datos. Entre estas, está Pandas, una biblioteca que nos da acceso a estructuras de datos muy poderosas para manipular datos.
¡Comenzemos entonces!
Instalación¶
Para poder ejecutar este Notebook, necesitas tener instalado Python 3, el cual corre en todos los sistemas operativos actuales, sin embargo, para instalar las dependencias: Pandas y Jupyter.
Modo Sencillo¶
Recomiendo utilizar la distribución Anaconda https://www.continuum.io/downloads en su versión para Python 3, esta incluye instalado Jupyter, Pandas, Numpy y Scipy, y mucho otro software útil. Sigue las instrucciones en la documentación de Anaconda para configurar un ambiente de desarollo con Jupyter.
https://docs.continuum.io/anaconda/navigator/getting-started.html
Una vez instalado, prueba a seguir los paso de https://www.tutorialpython.com/modulos-python/ o tu tutorial de Python Favorito.
«It’s a Unix System, I know This!» – Modo Avanzado¶
Te recomiendo utilizar Python 3.6 o superior, instalar la version mas reciente posible de virtualenv y pip. Usa Git para obtener el codigo, crea un nuevo entorno de desarollo y ahi instala las dependencias necesarias.
~/$ cd notebooks
~/notebooks/$ git clone https://github.com/tian2992/notebooks_dateros.git
~/notebooks/$ cd notebooks_dateros/
~/notebooks/notebooks_dateros/$
~/notebooks/notebooks_dateros/$ virtualenv venv/
~/notebooks/notebooks_dateros/$ source venv/bin/activate
~/notebooks/notebooks_dateros/$ pip install -r requirements.txt
~/notebooks/notebooks_dateros/$ cd 01-Intro
~/notebooks/notebooks_dateros/$ 7z e municipal_guatemala_2008-2011.7z
~/notebooks/notebooks_dateros/$ jupyter-notebookPrimeros pasos¶
## En Jupyter Notebooks existen varios tipos de celdas, las celdas de código, como esta:
print(1+1)
print(5+4)
6+4
Y las celdas de texto, que se escriben en Markdown y son hechas para humanos. Pueden incluir negritas, itálicas Entre otros tipos de estilos. Tambien pueden incluirse imagenes o incluso interactivos.
%pylab inline
import seaborn as sns
import pandas as pd
pd.set_option('precision', 5)
Con estos comandos, cargamos a nuestro entorno de trabajo las librerias necesarias.
Usemos la funcion de pandas read_csv para cargar los datos. Esto crea un DataFrame, una unidad de datos en Pandas, que nos da mucha funcionalidad y tiene bastantes propiedades convenientes para el análisis. Probablemente esta operación tome un tiempo asi que sigamos avanzando, cuando esté lista, verás que el numero de la celda habrá sido actualizado.
muni_data = pd.read_csv("GUATEMALA MUNICIPAL 2008-2011.csv",
sep=";")
muni_data.head()
DataFrames y más¶
Aqui podemos ver el dataframe que creamos.
En Pandas, los DataFrames son unidades básicas, junto con las Series.
Veamos una serie muy sencilla antes de pasar a evaluar muni_data, el DataFrame que acabamos de crear. Crearemos una serie de numeros aleatorios, y usaremos funciones estadisticas para analizarlo.
serie_prueba_s = pd.Series(np.random.randn(5), name='prueba')
print(serie_prueba_s)
print(serie_prueba_s.describe())
serie_prueba_s.plot()

Con esto podemos ver ya unas propiedades muy interesantes. Las series están basadas en el concepto estadistico, pero incluyen un título (del eje), un índice (el cual identifica a los elementos) y el dato en sí, que puede ser numerico (float), string unicode (texto) u otro tipo de dato.
Las series estan basadas tambien en conceptos de vectores, asi que se pueden realizar operaciones vectoriales en las cuales implicitamente se alinean los indíces, esto es muy util por ejemplo para restar dos columnas, sin importar el tamaño de ambas, automaticamente Pandas unirá inteligentemente ambas series. Puedes tambien obtener elementos de las series por su valor de índice, o por un rango, usando la notación usual en Python. Como nota final, las Series comparten mucho del comportamiento de los NumPy Arrays, haciendolos instantaneamente compatibles con muchas librerias y recursos. https://pandas.pydata.org/pandas-docs/stable/dsintro.html#series
serie_prueba_d = pd.Series(np.random.randn(5), name='prueba 2')
print(serie_prueba_d)
print(serie_prueba_d[0:3]) # Solo los elementos del 0 al 3
# Esto funciona porque ambas series tienen indices en común.
# Si sumamos dos con tamaños distintos, los espacios vacios son marcados como NaN
serie_prueba_y = serie_prueba_d + (serie_prueba_s * 2)
print(serie_prueba_y)
print("La suma de la serie y es: {suma}".format(suma=serie_prueba_y.sum()))
Pasemos ahora a DataFrames, como nuestro muni_data DataFrame. Los DataFrames son estructuras bi-dimensionales de datos. Son muy usadas porque proveen una abstracción similar a una hoja de calculo o a una tabla de SQL. Los DataFrame tienen índices (etiquetas de fila) y columnas, ambos ejes deben encajar, y el resto será llenado de datos no validos.
Por ejemplo podemos unir ambas series y crear un DataFrame nuevo, usando un diccionario de Python, por ejemplo. Tambien podemos graficar los resultados.
prueba_dict = {
"col1": serie_prueba_s,
"col2": serie_prueba_d,
"col3": [1, 2, 3, 4, 0]
}
prueba_data_frame = pd.DataFrame(prueba_dict)
print(prueba_data_frame)
# La operacion .sum() ahora retorna un DataFrame, pero Pandas sabe no combinar peras con manzanas.
print("La suma de cada columna es: \n{suma}".format(suma=prueba_data_frame.sum()))
prueba_data_frame.plot()

Veamos ahora ya, nuestro DataFrame creado con los datos, muni_data.
#muni_data
# Una grafica bastante inutil, ¿porque?
muni_data.plot()

# Veamos los datos, limitamos a solo los primeros 5 filas.
muni_data.head(5)
## La columna 'APROBADO' se ve un poco sospechosa.
## Python toma a los numeros como números, no con una Q ni un punto (si no lo tiene) ni comas innecesarias.
## Veamos mas a detalle.
muni_data['APROBADO'].head()
# Vamos a ignorar esto por un momento, pero los números de verdad son de tipo float
Veamos cuantas columnas son, podemos explorar un poco mas asi.
muni_data.columns
muni_data['MUNICIPIO'].unique()[:5] # Listame 5 municipios
print("Funcion 1: \n {func1} \n Funcion 2: \n {func2} \n Funcion 3: \n{func3}".format(
func1=muni_data["FUNC1"].unique(),
func2=muni_data["FUNC2"].unique(),
func3=muni_data["FUNC3"].unique()
)
)
Vamos a explorar un poco con indices y etiquetas:
index_geo_data = muni_data.set_index("DEPTO","MUNICIPIO").sort_index()
index_geo_data.loc[
["GUATEMALA","ESCUINTLA","SACATEPEQUEZ"],
['FUNC1','FUNC2','FUNC3','APROBADO','EJECUTADO']
].head()
Ahora que podemos realizar selección basica, pensamos, que podemos hacer con estos datos, y nos enfrentamos a un problema…
muni_data['APROBADO'][3] * 2
¡Rayos! porque no puedo manipular estos datos así como los otros, y es porque son de tipo texto y no números.
# muni_data['APROBADO'].sum() ## No correr, falla...
Necesitamos crear una funcion para limpiar estos tipos de dato que son texto, para poderlos convertir a numeros de tipo punto flotante (decimales).
## Esto es una funcion en Python, con def definimos el nombre de esta funcion, 'clean_q'
## esta recibe un objeto de entrada.
def clean_q(input_object):
from re import sub ## importamos la función sub, que substituye utilizando patrones
## https://es.wikipedia.org/wiki/Expresión_regular
## NaN es un objeto especial que representa un valor numérico invalido, Not A Number.
if input_object == NaN:
return 0
inp = unicode(input_object) # De objeto a un texto
cleansed_q = sub(r'Q\.','', inp) # Remueve Q., el slash evita que . sea interpretado como un caracter especial
cleansed_00 = sub(r'\.00', '', cleansed_q) # Igual aqui
cleansed_comma = sub(',', '', cleansed_00)
cleansed_dash = sub('-', '', cleansed_comma)
cleansed_nonchar = sub(r'[^0-9]+', '', cleansed_dash)
if cleansed_nonchar == '':
return 0
return cleansed_nonchar
presupuesto_aprobado = muni_data['APROBADO'].map(clean_q).astype(float)
presupuesto_aprobado.describe()
muni_data['EJECUTADO'].head()
muni_data['FUNC1'].str.upper().value_counts()
presupuesto_aprobado.plot()

Bueno, ahora ya tenemos estas series de datos convertidas. ¿como las volvemos a agregar al dataset? ¡Facil! lo volvemos a insertar al DataFrame original, sobreescribiendo esa columna.
for col in ('APROBADO', 'RETRASADO', 'EJECUTADO', 'PAGADO'):
muni_data[col] = muni_data[col].map(clean_q).astype(float)
muni_data['APROBADO'].sum()
muni_data.head()
muni_data['ECON1'].unique()
Ahora si, ¡ya podemos agrupar y hacer indices bien!
index_geo_data = muni_data.set_index("DEPTO","MUNICIPIO").sort_index()
index_geo_data.head(40)
mi_muni_d = muni_data.set_index(["ANNO"],["DEPTO","MUNICIPIO"],["FUNC1","ECON1","ORIGEN1"]).sort_index()
mi_muni_d.head()
## Para obtener mas ayuda, ejecuta:
# help(mi_muni_d)
mi_muni_d.columns
mi_muni_d["DEPTO"].describe()
year_grouped = mi_muni_d.groupby("ANNO").sum()
year_grouped
year_dep_grouped = mi_muni_d.groupby(["ANNO","DEPTO"]).sum()
year_dep_grouped.head()
sns.set(style="whitegrid")
# Draw a nested barplot to show survival for class and sex
g = sns.factorplot( data=year_dep_grouped,
size=6, kind="bar", palette="muted")
# g.despine(left=True)
g.set_ylabels("cantidad")

year_dep_grouped.head()
Contestando preguntas¶
Ahora ya podemos contestar algunas clases de preguntas agrupando estas entradas individuales de de datos.
¿Que tal el departamento que tiene mas gasto en Seguridad? ¿Los tipos de gasto mas elevados como suelen ser pagados?
year_grouped.plot()

year_dep_group = mi_muni_d.groupby(["DEPTO","ANNO"]).sum()
year_dep_group.unstack().head()
func_p = mi_muni_d.groupby(["FUNC1"]).sum()
func_dep = mi_muni_d.groupby(["FUNC1","DEPTO"]).sum()
func_p
func_dep_flat = func_dep.unstack()
func_dep_flat.head()
mi_muni_d.groupby(["DEPTO"]).sum()
func_p.plot(kind="barh", figsize=(8,6), linewidth=2.5)

![]()

CC by SA Monyo Kararan
Hay todavía un abismo entre el discurso de datos abiertos y el impacto que esta apertura, publicación, vinculación y otras prácticas tienen en la vida de las poblaciones globales. El puente entre los extremos de ese abismo es la relevancia de los datos, es decir, la capacidad que estos tienen para ser aprovechados efectivamente por las diversas poblaciones globales. Este abismo parece especialmente insondable para poblaciones que son política y socialmente excluidas.
La vinculación de los dos extremos de ese hueco es cada vez de una necesidad mayor, toda vez que organismos, oficiales y autónomos globales, han adoptado en mayor o menor medida dicho discurso de apertura de datos.
Es necesario en este punto, a la vez que admitir los avances, prestar atención a las muchas deficiencias en políticas de apertura en regiones específicas, reconocer que la apertura no es un fin en sí mismo, y que resulta trivial si no viene aparejada de garantías de acceso y uso de los conjuntos de datos. Más aún, resulta indispensable establecer mecanismos concretos y específicos para corregir esta deficiencia.
Para ello deben desarrollarse estándares contextuales, técnicos y de evaluación, con miras a la inclusión de amplias poblaciones que se beneficien del impacto de las políticas de apertura de datos.
El eje técnico
CC by NC SA Paul Downey
En un sentido técnico, la relevancia de datos es una métrica de calidad de datos que vincula los sets de datos disponibles con el interés de actores sociales. En este mismo sentido, parte del abismo entre apertura e impacto es irónicamente un vacío de (meta)datos: aquellos que se refieren a las potencialidades de “consumo” de dichos conjuntos de datos.
En una publicación sobre prácticas recomendables para la publicación de datos en la web, el World Wide Web Consortium (W3C) detalla una serie de criterios para que los conjuntos de datos sean vinculables y aprovechables en máximo grado. Entre estas prácticas, se encuentra el uso de un Vocabulario para el Uso de Conjuntos de datos (DUV, por sus siglas en inglés), para proveer un modo de retroalimentación entre “consumidores” y “publicadores” de datos sobre el uso de los mismos. Por ejemplo, agregando metadatos descriptivos a los conjuntos de datos, tanto sobre la base en sí misma, como de sus posibles usos. De esta manera, se generan metadatos que permiten contrastar el uso sugerido y el reuso dado.
Estas nuevas prácticas se adscriben a los principios FAIR y concuerdan con el espíritu de distribución y acceso universal que originalmente concibió internet.
Phil Archer, una de las diecinueve personas que redactó las recomendaciones, describe el propósito del documento de la siguiente manera:
““Quiero una revolución. No una revolución política, ni ciertamente una revolución violenta, pero una revolución a fin de cuentas. Una revolución de la manera en la que las personas piensan sobre compartir datos en la red”.
El eje contextual

CC by SA Marcos Ge
Para implementar relevancia hace falta una revolución que sí es de índole política: el reconocimiento de necesidades prioritarias en la publicación de conjuntos de datos, con respecto a necesidades de todos los grupos poblacionales, pero con especial atención a datos sobre garantías individuales que son sistemáticamente violentadas por gobiernos y otros actores sociales en distintas latitudes globales.
Por ejemplo, en el contexto mexicano, la Corte Interamericana de Derechos Humanos (CIDH) detalla en uno de sus informes más recientes no sólo algunas de las violaciones sistemáticas de Derechos Humanos: desaparición, desaparición forzada, tortura, ejecuciones extrajudiciales, injusticia; sino también las poblaciones más vulneradas por estas violaciones: mujeres, pueblos indígenas, niñas, niños, adolescentes, defensoras de derechos humanos, personas migrantes, personas lesbianas, gay, bisexuales, trans y otras formas de disentimiento sexual.
En países en que se viven estas condiciones, es indispensable que este contexto de Derechos Humanos sea considerado como un factor determinante para la elaboración de políticas de apertura de datos relevantes. Aparejada a estas políticas, sólo la instrumentación de reglamentaciones y mecanismos concretos de análisis de la demanda de datos puede proveer a estas poblaciones de elementos para su defensa, que convengan efectivamente en la mejora de sus vidas.
Un paso más para asegurar la relevancia de los datos abiertos es la creación de mecanismos específicos que garanticen que poblaciones política y económicamente excluidas tengan acceso a un volumen y calidad de datos suficientes que les permita trabajar para erradicar las prácticas mismas que han promovido su exclusión.
Es decir, debe existir una concordancia entre las políticas de apertura de datos y la agenda pública propuesta por un gobierno abierto para el empoderamiento de la población, agenda que ya de por sí debe incluir a las poblaciones mencionadas.
Para la elaboración de estándares de todo tipo sobre políticas de relevancia de datos deben ser llamadas a participar no solamente especialistas en defensa de derechos, legislaciones nacionales e internacionales y otras disciplinas, sino principalmente representantes de estas poblaciones vulneradas y despojadas de la vida o de factores que permitan una vida digna.
Hoy en día, la generación y publicación de datos con esta perspectiva se está llevando a cabo por organizaciones activistas. En México, por ejemplo, periodistas e investigadores independientes hicieron pública una base de datos sobre personas desaparecidas, y en Bolivia son activistas quienes construyen una base de datos sobre feminicidios; en España periodistas organizaron datos sobre la brecha de clase en el acceso a medicamentos; en Estados Unidos, un profesor universitario creó una base de variables relevantes para la comunidad LGBTTI; y desde el Reino Unido, el medio The Guardian creó una plataforma que muestra el número de personas de raza negra que mueren por causa de disparos de policías.
El eje de evaluación
Derivado del emparejamiento de los nuevos estándares técnicos propuestos por la W3C con las prioridades humanitarias globales, las poblaciones tendrían herramientas para exigir no sólo la calidad de los datos en los términos tradicionales de formatos de apertura, sino también en cuanto a su relevancia.
Por ejemplo, la encuesta global Open Data Survey, de la que proviene el Open Data Index de la organización Open Knowledge International, contiene algunas preguntas sobre la accesibilidad legal y técnica de los conjuntos de datos como una medida de su calidad. El Open Data Barometer, por otra parte, tiene un apartado de impacto social de la apertura de datos. Este año destaca, entre otras cosas, que el impacto en transparencia y rendición de cuentas disminuyó un 22%, mientras que el impacto en emprendimientos se incrementó 15%, lo cual ilustra que ciertos grupos sociales se están beneficiando de la apertura más que otros.
El aprovechamiento de la información es clave para que los conjuntos de datos puedan ser relevantes, no hay relevancia sin aprovechamiento y no hay aprovechamiento sin acceso a la información. En el caso ilustrado por el Open Data Barometer, los conjuntos de datos son relevantes solamente para emprendedores, lo cual implica que no necesariamente son relevantes para cualquier otro grupo poblacional.
No obstante, se necesitan más detalles para la evaluación de la relevancia de los datos a nivel nacional y local. En 2015, el investigador Juan Ortiz Freuler publicó el Estado de la Oferta y la Demanda de Datos Abiertos Gubernamentales tras la implementación de normativas de la defenestrada Alianza por el Gobierno Abierto en México, (de la cual las organizaciones de ese país decidieron salir, precisamente, debido a la evidencia de espionaje en contra de defensores de la salud y otros activistas con software de uso exclusivo gubernamental).
El informe de Freuler mostró, entre otros análisis, que la mayoría de las solicitudes de información (emparentadas con la demanda de datos abiertos) fueron realizadas por personas con grado académico de licenciatura, lo cual implica una profunda brecha de acceso a ellos respecto de poblaciones no profesionalizadas.
En su Uso y Cumplimiento de la Legislación de Acceso a la Información Pública en Brasil, Chile y México , los investigadores Silvana Fumega y Marcos Mendiburu ofrecen también algunos ejemplos de las ventajas de obtener datos sobre la demanda de información pública.
Por ejemplo, en la investigación de Fumega y Mendiburu se detalla que México incorpora dentro de la Ley General de Transparencia y Acceso a la Información Pública (LGTAIP) la obligación del organismo garante de recopilar datos sobre las solicitudes de información pública.
Con esta obligación, tanto el Estado como actores independientes pueden llegar a la conclusión de que en 2013 los institutos de seguridad social nacionales en México y Brasil y el ministerio de salud en Chile fueron las instancias públicas que más solicitudes de información recibieron. A partir de esa información es posible tomar medidas para jerarquizar la información de dicha instancia de salud pública.
Simultáneamente, los datos estadísticos sobre las personas que hacen las solicitudes, como su edad, género o escolaridad, abonan a la necesidad de delinear con datos también las políticas públicas de datos abiertos.
Así, la estandarización técnica de ciertas prácticas permitiría obtener y cruzar datos sobre el uso y propósito de los mismos; la priorización contextual permitirá garantizar que poblaciones excluidas y en riesgo puedan beneficiarse tanto como el resto de los grupos sociales; y la evaluación permitirá monitorear el resultado de las prácticas mencionadas.
En la publicación de las recomendaciones a las que antes aludí, sobre publicación de datos en internet, la W3C proponía generar a través de ellas una revolución exclusivamente tecnológica. No obstante, su articulación con estas otras formulaciones podría provocar una muy necesaria revolución que sí pertenece al orden de lo político: el empoderamiento de las comunidades a través del uso de conjuntos de datos.
![]()
Para poder hacer esa afirmación hice una prueba con las relaciones de los personajes de Narcos, la serie de Netflix, que narra la investigación que llevó a la captura del narcotraficante Pablo Escobar.
Este mapa fue realizado en un poco menos de una hora, recolectando toda la información e insertándola en Onodo. Ahora les explicaré porqué es tan fácil de usar:
- No necesitas ser un experto en Excel, ni siquiera abrirlo. Onodo permite insertar uno a uno los nodos (cada una de las personas, instituciones, etc… que necesitamos poner en el mapa) y también permite personalizar una a una las relaciones de cada nodo dentro de la misma aplicación.


- Es intuitivo, no es necesario leer el manual para usar sus funciones básicas. Ni siquiera existe un manual, si quieres algo parecido puedes ver su demostración en este enlace.
Ahora te explicaré cómo hice este mapa de relaciones en menos de una hora:
- Recolecté los datos de los personajes en IMBd y Wikipedia.
- Inserté los datos de cada personaje como un nodo. Por ejemplo: Pablo Escobar era el líder del Cartel de Medellín. Entonces usé el botón “Añadir nodo” y puse el nombre y la imagen que busqué en Google. Añadí otro nodo para el Cartel de Medellín. Ambos se reflejaron al instante en la visualización.

- Los nodos no están completos sin una relación. Entonces cambié a la pestaña de “relaciones” y hice click en el botón “añadir relación” para indicar que el nodo “Pablo Escobar” es el líder del “Cartel de Medellín”. Esto también se reflejó al instante.

- Así se muestra la visualización al hacer click sobre el nodo de “Pablo Escobar”.

- Luego agregue la información del resto de personajes principales y secundarios de la serie, de la misma manera que hice con Pablo Escobar. Todas se fueron mostrando dentro de la visualización.
- Compartir la visualización dentro de cualquier otro sitio es igual de sencillo. Pulsas en el botón “Comparte” donde harás pública la visualización y después te creará un iframe y un enlace fijo.

Si aún no te convence esta sencilla explicación puedes entrar a este enlace para ver otros mapas de relaciones que han realizado otros usuarios. Y si la explicación te convenció, como usarlo me convenció a mí, puedes entrar a este enlace para crear tu cuenta y empezar a experimentar.
![]()
A través de un usuario creado en VIS, puedes generar visualizaciones en lenguaje HTML5 dinámico. Las visualizaciones generadas se pueden exportar tanto para su uso en impreso como para la web o transmisiones de televisión. Esta herramienta puede ser usada por periodistas, investigadores y activistas en su trabajo de difundir información con impacto social.
En cuanto al diseño, esta página web te ofrece siete plantillas con diferente paleta de color, tipografía e iconos para que puedas escoger el que se adapte mejor a tu proyecto.

Pero el detalle no se detiene en la iconografía. En VIS también puedes brindar información detallada sobre el tipo de conexión entre un punto y otro. Por ejemplo, al conectar a una persona con una compañía, esta puede ser propietario, representante o empleado. Las relaciones entre empresas, bancos y fundaciones también tienen niveles de detalle que pueden servir para explicar el porcentaje de acciones en una compañía, la propiedad de una sociedad o cualquier otro detalle sobre las uniones entre dos nodos. Entre personas se puede señalar que son familiares o compañeros en alguna empresa, fundación o partido político.
Los vínculos se expresan a través de una línea o flecha y es posible escribir detalles o adjuntar documentos que prueben la relación entre ambos nodos. Toda esta información se almacena en una base de datos a la que cada usuario puede acceder para modificar o duplicar el contenido que ha creado.
VIS reconoce dos tipos de contenido principales: una entidad (persona o empresa) y una relación o vínculo. Para crear una entidad es necesario hacer click en el botón con el signo más (+) y este comenzará a desplegar los tipos de entidades que describimos antes. Para crear un vínculo sólo debes seleccionar a una entidad ya creada, presionar el botón de vínculo y hacer click en otra entidad con la que exista algún tipo de relación.
Existe también la opción de que la red se mueva en función de los nodos y vínculos que la componen. Activa la opción “Physics engine” y ve cómo tu red se transforma a la medida en que interactúas con los elementos. Para guardar, ve a el menú “Project” y selecciona “Save layout”. Las opciones para compartir en la web se encuentran bajo “Export layout” y puedes también descargar como imagen en formato JPEG o PNG con fondo y transparente en “Export image”.
Aplicar visualizaciones en red a cualquier trabajo es posible, sólo piensa en la estructura de la organización para la que trabajas, o cómo se relacionan las autoridades de algún ente gubernamental. Cuando las fiscalías presentan casos de corrupción, suelen apoyarse en visualizaciones de este tipo para explicar mejor los flujos dentro de una estructura delictiva.
En mi trabajo como periodista, he utilizado VIS en varias ocasiones. Ya sea para explicar cómo se conforma una megacorporación que es la principal acusada en un caso de ecocidio por la muerte de toda la fauna de un río en Guatemala, o para demostrar cómo un candidato presidencial escondía a través de sociedades anónimas vinculadas a él, el 46% del dinero que reportó para su campaña.
¿Has utilizado VIS para tus proyectos con datos? ¿Cómo te ha funcionado la herramienta? Mándanos un tuit etiquetando a @EscuelaDeDatos y @danyvillatoro para contarnos tu experiencia.
![]()
Mucho se ha hablado de dicha situación, pero más veladamente de qué herramientas se utilizaron para analizar lo que el académico español Alex Rayón (2016) considera todo un proyecto de Big Data por la enorme cantidad de documentos que fueron analizados para realizar diversos insumos periodísticos, comprendidos por 2.6 terabytes, 11.5 millones de documentos.
Por esa razón, como Escuela de Datos, detallaremos un poco acerca de la herramienta Linkurious (en su versión de prueba), que te permitirá trazar y visualizar los vínculos de documentación obtenida por temas y sujetos de investigación.
Iluminando los caminos de la opacidad
«¿Cómo se hace para que un proyecto de este calibre sea navegable?», te preguntarás. Para el Consorcio Internacional de Periodistas de Investigación (ICIJ, en inglés), fueron clave tres aspectos relevantes: la colaboración de equipos multidisciplinarios a escala global, la interfaz amigable e intuitiva de Linkurious y, en última instancia, la protección a la seguridad brindada por la herramienta para que ningún periodista sufriera situaciones de riesgo por la publicación de los #PanamaPapers.
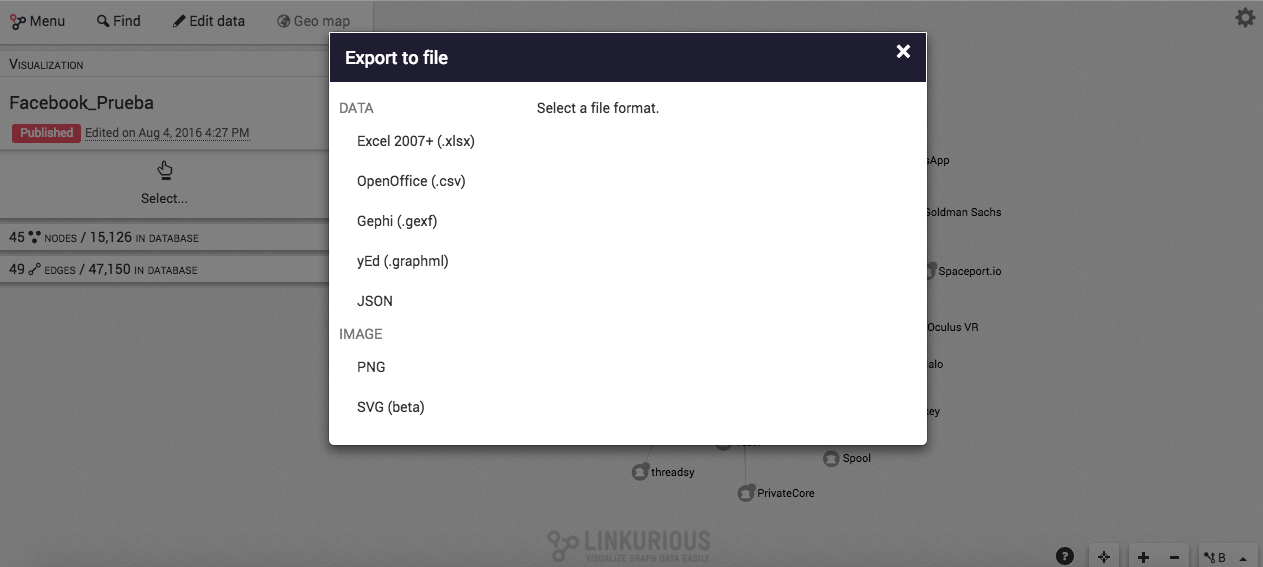
Con este panorama, es posible que tengas una base similar a los #PanamaPapers y quieras echarla a andar. Y, para explicarte a grandes rasgos cómo utilizar esta herramienta, utilicé la base de Facebook que ellos tienen registrada en su directorio, el cual puede ser de tu interés para comenzar a implementar mapas de influencia, como el que te mostraré.
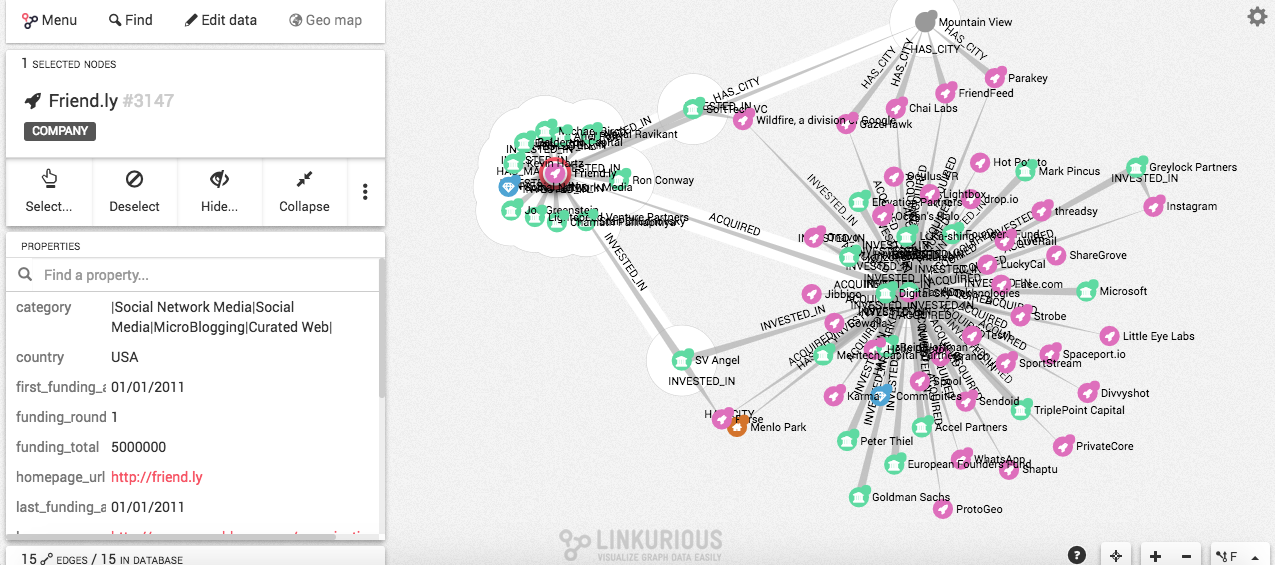
1.- Una vez seleccionemos Facebook (de cualquiera de las dos formas), nos aparecerá nuestro canvas. Para comenzar a editar relaciones, seleccionamos el nodo proporcionado al lado izquierdo de la pantalla.

2.- Para averiguar las relaciones de Facebook, haremos doble clic para expandirlo. ¡Ojo! Cuando veas el halo blanco alrededor de cada nodo, significa que todos están conectados a Facebook y cada arista representa el grado de relación que tienen entre sí. Y, cuando hagamos clic en una relación, sus relaciones se desplegarán y podremos ver sus propiedades en el lado izquierdo, como acabo de hacerlo con Friend.ly.
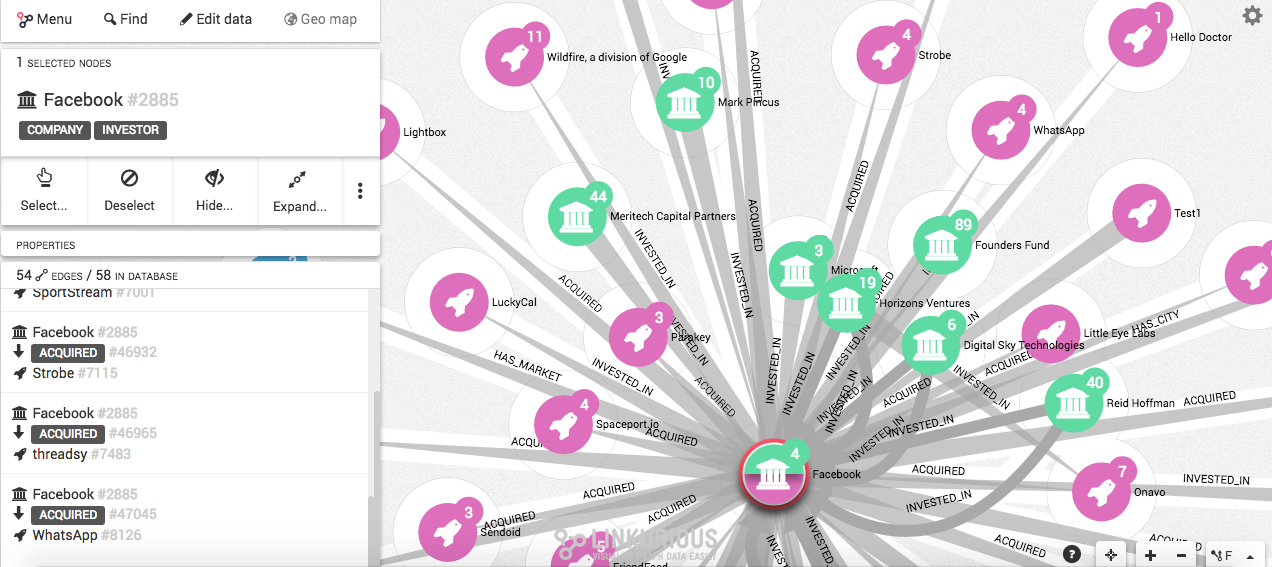
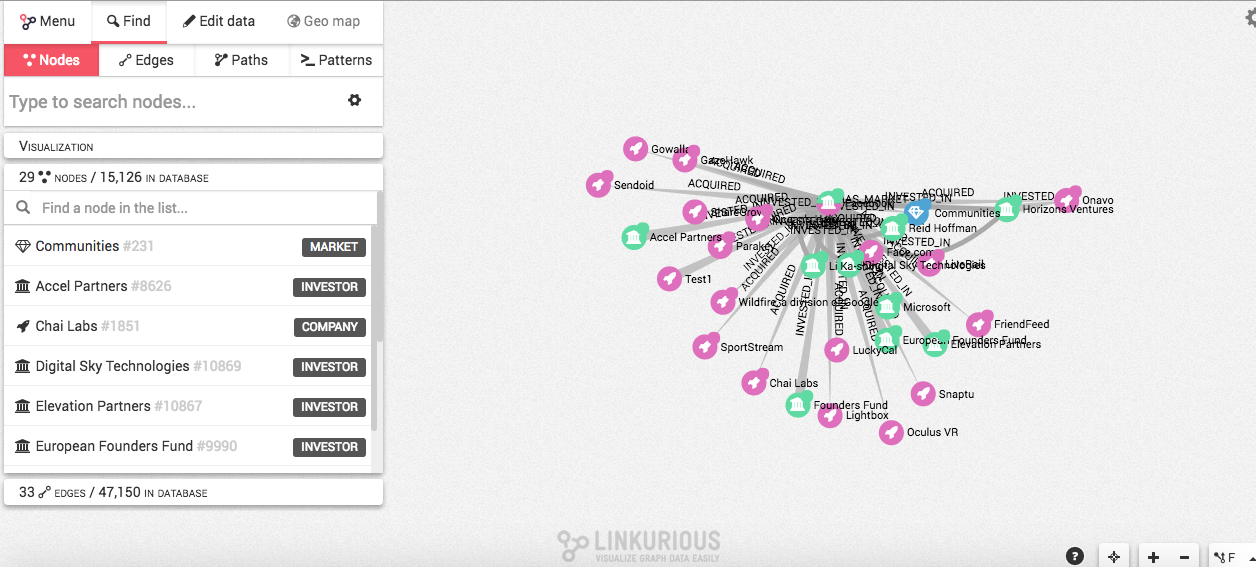
3.- Otra cosa interesante radica en filtrar los resultados por categorías haciendo clic en aquellas que nos interesen junto al nombre del nodo o relación. También, podemos buscar un nodo o relación en particular utilizando la barra de búsqueda, como acabo de hacerlo con qué empresas ha adquirido Facebook con la categoría Acquired.
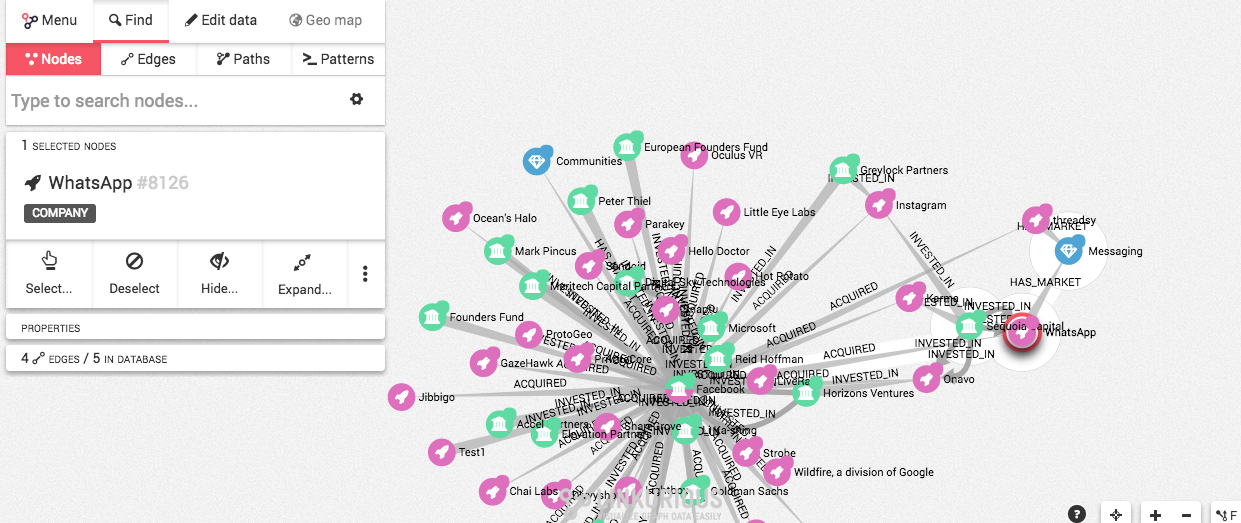
4.- Al igual que ampliamos las relaciones de Facebook, utilicé las variables Expand (Expandir) y Collapse (Reducir) en el nodo WhatsApp para que puedas ver de qué forma se pueden desglosar los diferentes elementos que pueden ser relevantes o no para nuestra visualización en un mapa de influencia.

5.- Si comenzamos a ver que nuestra visualización es demasiado compleja para nuestra audiencia, podemos seleccionar determinadas áreas en nuestro mapa de influencias y comenzar a ocultarlos seleccionándolos manualmente o utilizando la opción Toggle Lasso del botón Seleccionar. Una vez hayas hecho esto, utiliza el botón Hide (Ocultar), ubicado en el panel de la izquierda, para difuminar relaciones que consideres irrelevantes o poco importantes, como podrás contemplar a continuación.
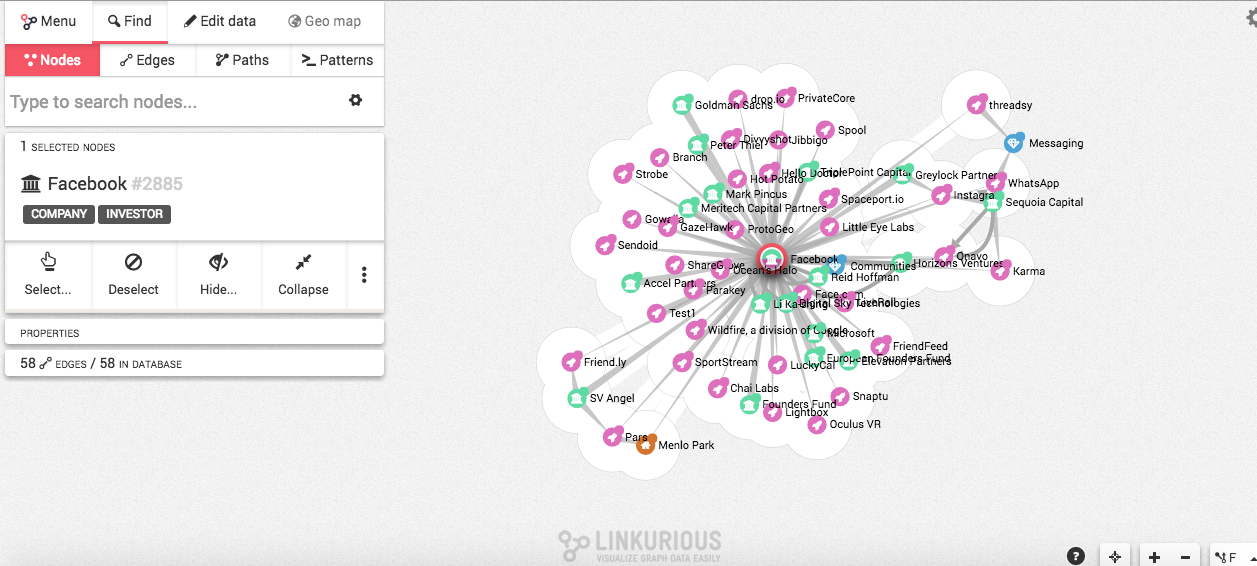
6.- Para mejorar la forma en que se visualiza tu mapa de influencia, puedes utilizar el botón layout, ubicado en la barra inferior derecha, donde puedes encontrar opciones de jerarquización para posicionar tus nodos, de tal forma que puedas mejorar la visualización. Acá, puedes ver cómo cambió la visualización que tenía. Recuerda: es importante que consideres dónde lo publicarás y cómo deseas llegar a tu audiencia con tu investigación.

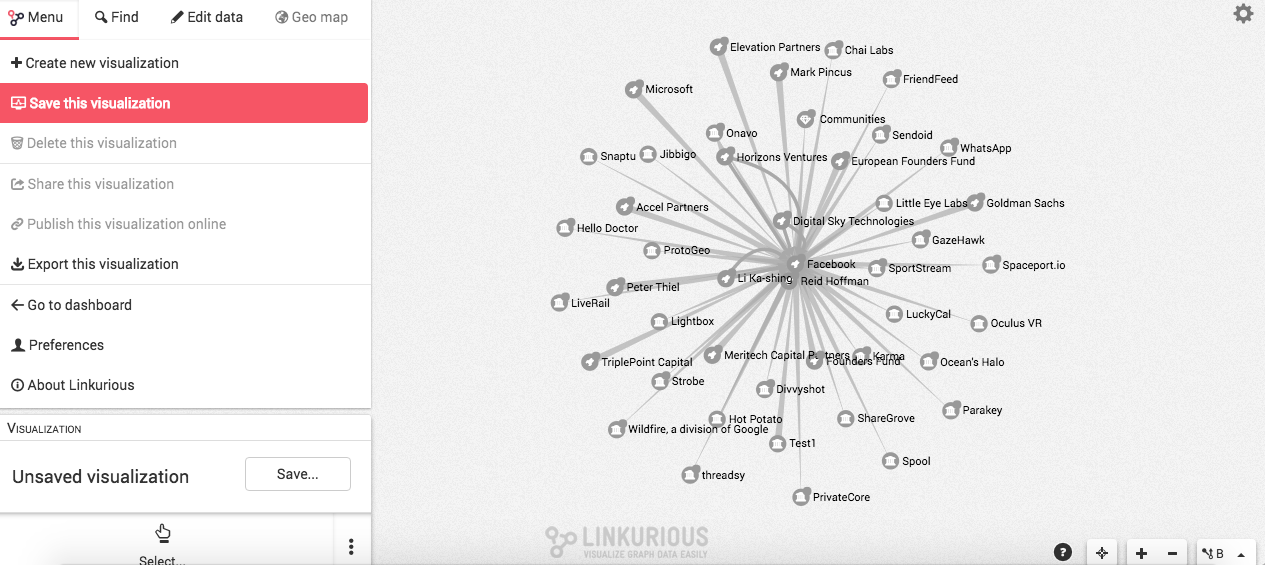
7.- Si eres un quisquilloso de los colores predeterminados de los programas como yo, te cuento que Linkurious te deja personalizar los nodos, de acuerdo a las necesidades de visualización que tengas. Para eso, debes irte al ícono de Engrane ubicado en la parte superior derecha del programa y ubicarte en la opción Diseño, donde podrás seleccionar las paletas e íconos para personalizar y diferenciar tu mapa de influencia a la hora de visualizarlo en tu sitio.
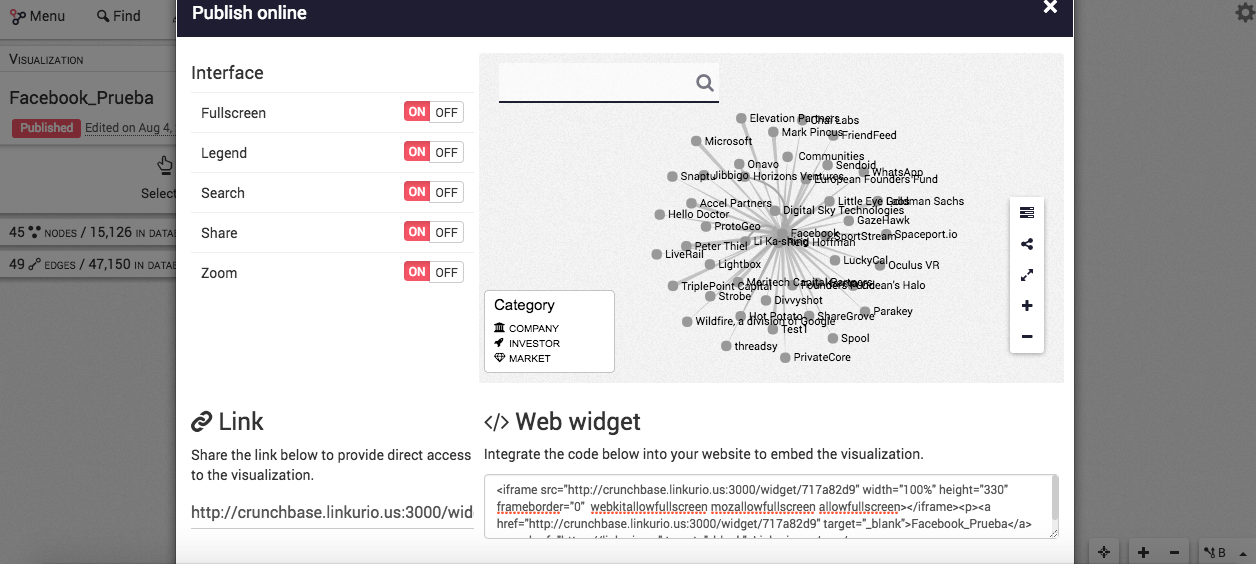
8.- Supongamos que estamos de acuerdo con esta visualización y deseas compartirlo ya. Para eso, tienes diferentes opciones en Menú: puedes enviárselo a miembros de tu equipo por correo electrónico, obtener un web widget para insertarlo en tu sitio o exportarlo a varios formatos para utilizarlo en presentaciones, ponencias o en charlas de Datos y Cervezas.
¿Vale la pena?
Yo te animo a que utilices la versión de prueba con bases de datos que actualmente tengas y, si esta te convence, pídele a tu editor o superior, comprar la versión pro para echar a andar iniciativas macro relacionadas con corrupción, transparencia y manejo de fondos públicos en tu país. Siempre me gusta decir que la tecnología y las herramientas no revelan nada por sí solas, pero pueden ayudarnos a encontrar las historias detrás de los datos, ya que pueden ayudarnos a realizar las preguntas correctas y así entender de forma clara, precisa y concisa los resultados que nos devuelvan.
Con los #PanamaPapers, queda claro una cosa: la consolidación de iniciativas periodísticas que combinan los mejores elementos y técnicas de la investigación y las nuevas tecnologías, un panorama cada vez más cercano y que paulatinamente está llegando paso firme a las salas de redacción e iniciativas de la sociedad civil. Me alegra muchísimo que esto venga para quedarse y, si tienes dudas sobre cómo utilizar esta herramienta, no dudes en escribirnos debajo de este post o búscanos en nuestras redes sociales como Escuela de Datos.
![]()

Bolivia CC by SA NC MM
¿Cuánto invierte el municipio en seguridad ciudadana, cuánto ha crecido la tala de árboles en los últimos años, cuántas lenguas indígenas se hablan por ciudad? El qué, cómo, cuándo y cuánto son preguntas en torno a las que gira la labor de organizaciones de la sociedad civil, activistas y estudiantes.
Dar respuesta a estas indagaciones viene de la mano del aprovechamiento de los datos existentes para generar valor e incidencia pública a partir de los hallazgos.
Por ello, con Escuela de Datos organizamos el “Tour Datero Bolivia” que se realizará este mes de agosto en las ciudades de Santa Cruz, Cochabamba, El Alto y La Paz. En cada ciudad hay espacio para 40 participantes.
El objetivo de esta serie de eventos es descubrir lo que los datos pueden mostrar a través de la capacitaciones y mentorías en depuración, análisis y representación de los datasets en formatos abiertos, cómo crearles valor, de qué forma pueden ser aprovechados; todo ello sobre la base de dudas y planteamientos propios de las organizaciones, y a partir de datos generados por organizaciones públicas y no gubernamentales en Bolivia.
Cuatro ciudades
Si estás en cualquiera de las ciudades que enlisto, puedes participar de talleres, expediciones de datos, mentorías a iniciativas o sesiones más ligeras acompañadas de una bebida.
Este es el calendario para escoger tu actividad, todos los eventos son gratuitos. Solamente recuerda que es requisito registrarse en el formulario correspondiente hasta el sábado 13 de agosto a las 20:00 (GMT -04:00).
Primero en Santa Cruz
Dos eventos abiertos y gratuitos orientados a colectivos, activistas, organizaciones de la sociedad civil y personas interesadas en mejorar sus capacidades para usar los datos de manera efectiva y eficiente.
Para cualquiera de ellos debes registrarte en este enlace: http://bit.ly/SantaCruzTourDatero
Solo requieres llevar tu laptop.
Cómo dar valor a los datos desde organizaciones de la sociedad civil
Dónde: Fundación Trabajo Empresa, Calle Moldes esquina Cobija (Edificio Telecentro Santa Cruz).
Fecha: 16 y 17 de agosto
Hora: 9:00 a 18:00 y de 10:00 a 13:00
Qué verás: 16/08 Taller con ejercicios prácticos para que los asistentes puedan absorber los conocimientos sobre los lineamientos básicos y el proceso para la utilización de datos abiertos.
17/08 Sesiones de mentoreo para iniciativas que deseen crear valor y aprovechar los datos abiertos para sus organizaciones y proyectos.
Organiza Escuela de Datos; apoyan Colectivo Rebeldía y Fundación Trabajo Empresa.
También “Datos y Cervezas” el 16 de agosto desde las 20:00 en La Esquina del Cronopio (calle Colón esq. Lemoine); conoce proyectos de datos abiertos (emergentes y consolidados) a nivel regional compartiendo una cerveza.
Cochabamba, tecnologías y género
En Cochabamba, nos lucimos con una serie de eventos de van desde la capacitación y expedición de datos con temas de género hasta sesiones más ligeras de mentoría de iniciativas o solamente hablar de datos comiendo un picado. Si tu interés está en temas de género o simplemente quieres aprender cómo trabajar con datos, registrate en este enlace: http://bit.ly/TourDateroCochabamba. Para el caso de la capacitación y expedición de datos, el equipo coordinador tomará contacto contigo para confirmar tu participación.
Solo requieres llevar tu laptop.
Datos que narran la violencia de género
Dónde: Centro de Estudios Superiores Universitarios, Calle Calama 235
Fecha: 18 y 19 de agosto
Hora: 9:00 a 18:00
Qué verás: 18/08 Taller con ejercicios prácticos para que los asistentes puedan absorber los conocimientos sobre los lineamientos básicos y el proceso para la utilización de datos abiertos.
19/08 Expedición de datos a partir de datos sobre violencia de género de organizaciones públicas y no gubernamentales para producir narrativas, visualizaciones y otros productos.
Organiza Cuántas Más, Escuela de Datos y SLIM Cochabamba; apoyan CESU-UMSS, Coordinadora de la Mujer, Udabol.
Conversatorio sobre Nuevas Tecnologías e Investigación en Ciencias Sociales
Dónde: Centro de Estudios Superiores Universitarios, Calle Calama 235
Fecha: Jueves 18 de agosto
Hora: 19:00
Organiza Cuántas Más, Escuela de datos , CESU-UMSS
También “Picando Datos” el 19 de agosto desde las 20:00 en Café Bistró El Caracol (calle Mayor Rocha Nº 286 casi esquina España); conoce proyectos de datos abiertos (emergentes y consolidados) a nivel regional acompañado de picados.
Mentoría express
Dónde: Centro de Estudios Superiores Universitarios, Calle Calama 235
Fecha: 20 de agosto
Hora: 09:00 a 12:00
Qué verás: Mentoría para iniciativas que deseen crear valor y aprovechar los datos abiertos para sus organizaciones y proyectos.
Organiza Escuela de Datos y Cuántas Más.
Estudiando en El Alto
Si vives en El Alto y estudias en comunicación, periodismo, sistemas e informática y diseño, o eres parte de colectivos activistas u otras organizaciones de la sociedad civil y principalmente; este evento te interesa. De la A a la Z, aprenderás los elementos esenciales para empezar tu trabajo con datos desde un enfoque de aplicación con datos de la vida real.
Debes registrarte en este enlace para participar: http://bit.ly/TourDateroElAlto
Solo requieres llevar tu laptop.
Cómo y dónde empezar a trabajar con datos
Dónde: Casa de las Culturas Wayna Tambo, Zona de Villa Dolores Calle 8 No 20
Fecha: 22 de agosto
Hora: 9:00 a 18:00
Organiza Escuela de datos; apoya La Pública y Wayna Tambo.
Qué verás: Taller con ejercicios prácticos para que los asistentes puedan absorber los conocimientos sobre los lineamientos básicos y el proceso para la utilización de datos abiertos.
Las experiencias de La Paz
En La Paz nos enfocaremos en los proyectos e iniciativas ciudadanas que ya empezaron a tomar impulso con dos eventos: el primero más relajado para conocer lo que se está haciendo en cuanto a datos abiertos en Latinoamérica; y el segundo, una sesión para resolver dudas específicas de cada proyecto.
Debes registrarte en este enlace para participar: http://bit.ly/TourDateroLaPaz
Solo requieres llevar tu laptop.
“Datos y Singanis” el 22 de agosto desde las 20:00 en La Obertura Café Arte Rock (Calle Boyacá #2286, sobre Medinacelli. Entre 20 de Octubre y Rosendo Gutiérrez); conoce proyectos de datos abiertos (emergentes y consolidados) a nivel regional más un vaso de singani.
Impulsando iniciativas y proyectos ciudadanos de datos abiertos
Dónde: Bolivia Tech Hub, Av. Sanchez Lima (final) esquina Pasaje Fabiani 2687
Fecha: 23 de agosto
Hora: 16.00 a 19.00
Qué verás: Sesiones de mentoría express para iniciativas que deseen crear valor y aprovechar los datos abiertos para sus organizaciones y proyectos.
Organiza Escuela de datos; colabora Bolivia Tech Hub.
![]()

“Esta idea de que con Felipe Calderón [presidente mexicano de 2006 a 2012] estalló la violencia asociada al narcotráfico… yo quería que los datos vinculados me lo explicaran, y fue cuando encontré la explosión de células delictivas y cómo están reconocidas por las mismas autoridades que generaron esa violencia”,
dice Tania Montalvo, reportera que desde 2014 investiga el comportamiento de cuatro décadas de narcotráfico mexicano a través de bases de datos, trabajo conocido como NarcoData.
“Más allá de las ideas que tenemos, ¿qué argumentos realmente sostenibles tenemos para saber si esa idea es verdad o no? Para eso sirven realmente los datos en el periodismo”.
Montalvo, de 31 años, se ha hecho de una visión clara del periodismo de datos al cuantificar el poder y sus abusos en investigaciones sobre violaciones de la ley en detrimento del ambiente en la Ciudad de México, corrupción e incumplimiento de promesas al verificar el pago de nóminas a maestros (algunos de los cuales cobraban desde ultratumba) y, por supuesto, NarcoData, entre otras más.
¿Cómo han guiado los datos sus investigaciones periodísticas?
NarcoData

Celda por celda, columna por columna, Montalvo construyó una imagen de datos para lo que llama “una sombra sin rostro”, la del crimen organizado. Entre otras conclusiones, cuantificó la explosión de la violencia: al finalizar el sexenio anterior a Calderón eran tres bandas criminales armadas que se tenían monitoreadas, tras seis años de una estrategia militarizada en su contra, se multiplicaron hasta sumar 52.
¿Cómo guiaron los datos a Montalvo y al equipo de Animal Político y Poderopedia de un documento único que obtuvieron en octubre de 2014, donde meramente se enlistaban los grupos delictivos activos ese año, territorio y cártel al que obedecían, hacia el análisis detallado de prácticamente toda la historia del narcotráfico en México?
“Lo que yo quería era tener toda la información en un mismo lugar, porque la información sobre el narco es tanta que no sabíamos dónde estaba la nota”.
La primera base que construyó fue sencillamente esa: qué organizaciones criminales había, su presencia en el territorio mexicano y su lealtad a cárteles determinados.
“Tuve que ir hacia atrás para mostrar cómo esas organizaciones antes no existían, porque los datos me fueron hablando y me hicieron preguntar ¿por qué ahora son 9 cárteles, cómo llegamos a ellos, por qué de pronto son más violentos, por qué unos son más grandes que otros? y todo eso lo pude hacer gracias a la primera base de datos”.
A partir de esa base “madre”, a golpe de teclazo en Excel, Montalvo construyó una nueva, que califica como una investigación de fuentes híbridas.
“No es un trabajo cuantitativo 100 por ciento. A la información en papel de la Procuraduría General de la República (PGR) agregué información de análisis que encontré en documentos académicos sobre estudio de crimen organizado, más información de entrevistas y comunicados y boletines de la misma PGR a medios.”
Después interrogó a su nueva base.
“¿Qué era lo que me estaba mostrando? Hay que tener la mente muy abierta a hacer cualquier pregunta a los datos, hasta la más complicada, no obviar cosas, y tampoco creer que no vas a encontrar tus respuestas en la base, porque realmente los datos hablan, y hablan muchísimo”.
La respuesta entonces fue obvia. Los datos mostraban la pulverización de los grupos criminales en mayor número aparejada al incremento de la violencia con los años.
“Era la evolución de las bandas del crimen organizado, me estaba mostrando quiénes son los dominantes, que hubo una separación entre ellos. Eso me llamó a responderme con los mismo datos: ‘hay conflictos muy específicos entre los grandes cárteles’.”
“Es necesario entender qué es lo que tienes: si tienes años, cuáles son tus campos… Con base en ello ves hacia dónde te pueden llevar los datos. Siempre respeta a tu base en el sentido de tenerla limpia, conocerla, para que te hable. Si no está limpia, cuando te ‘escupa’ una respuesta, no la vas a ver”.
NarcoData ha alcanzado siete entregas, pero las bases construidas por Tania aún no agotan su potencial. Este trabajo, no obstante, no era el primero en el que Montalvo construyera y analizara una base de datos.
Censo de la Reforma Educativa

CC By CEDIM News
En un proceso de supuesta renovación de estructuras mexicanas como la energética, la fiscal y la educativa, una de las promesas de avance en esta última fue la depuración de la nómina de profesores que reciben pago del erario público.
No más fallecidos que cobran sueldo por enseñar, maestros que renunciaron y cuyos pagos no obstante siguen siendo religiosamente cobrados o maestros que jamás dieron una sola clase frente a grupo. La investigación que Tania Montalvo publicó en 2015, sobre la nómina nacional de maestros, descubrió que la promesa era, al menos hasta entonces, falsa.
Lo probó a través de la construcción y cruce del recién hecho censo magisterial nacional contra la nómina pagada por la Secretaría de Hacienda y Crédito Público (SHCP).
“La idea surgió de una base que nos entregó Gobierno de Oaxaca después de una solicitud de transparencia, con 40 mil celdas: cada maestro, cada escuela. Pudimos ver maestros hasta con 30 plazas, solamente en Oaxaca”.
Esa base se escaneó desde las infames fotocopias en papel que le fueron entregadas, desde donde escrapeó con algunas herramientas como Cometdocs, Tábula e Import.io.
Para ampliarla a nivel nacional, Tania recurrió al Instituto Mexicano para la Competitividad, con quienes obtuvo ayuda para rastrear los datos nacionales relacionados con la nómina magisterial a través de la plataforma de datos abiertos del gobierno federal, por entonces una novedad.
“Creo que de alguna forma ese fue mi primer acercamiento con los Datos Abiertos de gobierno, yo estaba escéptica, pero base con solicitud por cada estado, hubiésemos tardado muchísimo. Pudimos hacerlo a nivel nacional, pudimos comparar cómo la nómina antes y después de la reforma educativa no había cambiado, sino en un mal sentido, les estaban pagando más a los maestros pese a que se suponía que ya les habían depurado, y lo pudimos ver trimestre a trimestre”.
La nómina, pagada por SHCP fue contrastada contra la base de datos de la Secretaría de Educación Pública (SEP), que recién había efectuado un censo donde se enlistaban qué maestros que daban clase frente a grupo, quiénes sólo realizaban labores sindicales y dejaba fuera “aviadores” y otros defraudadores.
“SHCP tiene que preguntar a SEP si todos esos maestros están frente a grupo y la SEP tuvo que haber verificado que estaban frente a grupo o si no murieron, porque había muchos muertos que seguían cobrando sueldos”.
Este año, la SEP reconoce por primera vez que dejó de pagar 5 mil plazas porque no estaban frente al grupo. “Eso debió haber ocurrido antes”, acota Montalvo.
Gasolineras por colonia
En 2014 Montalvo desarrolló una investigación sobre las gasolineras que en la Ciudad de México violaban la ley al ser un excedente a lo permitido. En este trabajo el mayor reto fue la dispersión y falta de granularidad de algunos de los datos: Montalvo tenía por un lado información en porcentajes del excedente de gasolineras y por otra parte listados de todas las razones sociales de gasolineras en la Ciudad, pero no tenía las ubicaciones de las gasolineras que violaban la ley.

“Yo sabía que había más gasolineras y que se estaba violando el reglamento, Pemex tenía muchas bases de datos, pero tenía los nombres de gasolineras al azar, no me decía dónde estaban, pero nosotros obtuvimos otra base de datos por delegación.
“Pudimos entonces cruzar las bases de datos para saber en dónde estaban, y cruzamos con una base más, de la Procuraduría Federal del Consumidor (Profeco), para saber cuáles estaban sancionadas, y cuáles estaban violando la ley al abrir”.
Con la ayuda de las organizaciones Escuela de Datos y Social Tic, y en particular de Phi Requiem, Fellow de Escuela de Datos 2014, se logró la sistematización de dicha información.
“De alguna forma fue una base chiquita, pero el caso es que toda la denuncia ya estaba totalmente construida, yo tenía reporteado con los gasolineros que se estaba violando el reglamento, pero no tenía datos para hacerlo mucho más visible.
“Nos permitió construir este mapita donde ya fue lo único que necesitábamos para cerrar y así le mostramos solidez a nuestro argumento de que se estaba violando la ley”.
Datos para justificar opiniones
De cierto modo, la trayectoria de Tania Montalvo le permitió desarrollar una idea que inició en una clase de periodismo asistido por computadora (PAC) en alguna de sus clases de periodismo en el Tec de Monterrey.
“Lo que me llevé de esa materia es entender la importancia de usar datos, de que la información en cualquier nota periodística fuera precisa, más allá de una declaración”.
Justificar (o no) con datos las declaraciones de personajes públicos o de opiniones públicas ampliamente compartidas entre ciudadanos, ha sido el hilo conductor desde sus primeras investigaciones en CNN Expansión sobre la ubicación de víctimas de violencia hasta NarcoData.
“Todo tipo de periodismo debe tener datos, y los hay en todas partes. Entiendo el punto de que se le llame periodismo de datos pero al final es periodismo.
“Si es periodismo: narrativo, de explicación, de lo que sea, es súper importante saber usar los datos y hacerlo bien. En el periodismo de datos puedes usarlos en masa, una cosa mucho más grande, pero para llegar a eso tiene que empezar utilizando bien porcentajes, tasas, sabiendo cómo se hace una diferencia porcentual… cosas que son elementales para que sigas el camino de los datos y ya puedas utilizar una base mucho más grande”.
Otro punto que es necesario tener en mente, en opinión de Montalvo, es que la interdisciplinariedad no suple la obligación individual de aprender de otras disciplinas.
“El trabajo multidisciplinario es valiosísimo, pero al mismo tiempo es fundamental que entre todos comprendamos la labor del otro, aunque sea en la parte mínima. Yo no programo, pero creo que sí es necesario tener al menos ideas básicas porque un programador es valiosísismo y están dedicados. Difícilmente llegue a los niveles en que está nuestro programador, Gilberto León, pero yo debería saber que si quiero que Gilberto entienda mis ideas, yo debería entender las suyas a un nivel técnico”.
“Yosune, nuestra diseñadora, que sí sabe de programación, tuvo que aprender muchísimo de mi labor periodística, en términos de mi mirada como periodista para poder visualizarla y yo al mismo tiempo tuve que aprender de ella para poder comunicar lo que tenía. En ese sentido es muy importante conocer un poco de lo que hace que el otro”.
![]()

Periodistas, economistas y desarrolladores, ex fellows del programa Fellowship de School of Data, detallan qué es y cómo se han servido del fellowship para crecer la comunidad de datos en Latinoamérica
Han influido en la rendición de cuentas nacionales de Perú y Costa Rica con publicaciones como Decide por tu Cantón o Cuentas Juradas; han capacitado periodistas para que detallen la confiabilidad de gasolineras, como en Gasolineras honestas, y han contribuido a la vinculación de datos sobre mineras en Perú, a través del Instituto de Gobernanza de Recursos Naturales.
Pero, por encima del alcance de proyectos específicos en los que trabajaron durante el Fellowship de School of Data, los fellows latinoamericanos que hasta ahora han participado evalúan el impacto de su trabajo en términos de su contribución para la creación de una escena local y regional en el uso efectivo de datos, que se une a una red global que tiene el mismo propósito.
Camila Salazar y Julio López, seleccionados de la Fellowship 2015, así como PhiRequiem y Antonio Cucho, en 2014, detallan cómo compartieron sus conocimientos sobre apertura de Datos a una red global de actores sociales, los retos que enfrenta la escena local y las enseñanzas que obtuvieron de sus fellowships, vis a vis la convocatoria para este Fellowship 2016.
Para los participantes, el fellowship fue la oportunidad única o bien para generar escenas locales y regionales de apertura, limpieza y visualización de datos, o de elevar la solvencia técnica de comunidades periodísticas, o contribuir a movimientos de transparencia de recursos naturales, con el soporte de una comunidad global y regional que, además, les otorgó visibilidad a una enriquecedora red de actores sociales.
Periodismo de datos y Datos sobre la industria extractiva son dos de los temas en que ellos se especializaron, y forman parte de los enfoques temáticos de la convocatoria para el Fellowship 2016.
La primera entrega es esta entervista con Camila Salazar, fellow de Costa Rica en 2015
Lee la entrevista con Camila Salazar aquí
La segunda entrega es una relación del proceso de capacitación, principalmente en Centroamérica, de PhiRequiem, fellow de México en 2014.
Lee la entrevista con PhiRequiem aquí
La tercera y penúltima entrega es una entrevista con Antonio Cucho Gamboa, fellow por Perú en 2014, fundador de Ojo Público, Open Data Perú, y un fellowship nacional.
Lee la entrevista con Antonio Cucho aquí
Nuestra última entrega es nuestra entrevista con Julio López, fellow por Ecuador en 2015, quien inauguró lo que hoy una línea temática del fellowship: la extracción, gestión y visualizació de datos sobre recursos minerales.
Lee la entrevista con Julio López aquí
![]()

Fellowship 2016
Postúlate ¡AHORA!
Fecha límite: 10 de marzo 2016
Duración: abril a diciembre 2016
Link: http://bit.ly/fellowship_2016
Escuela de Datos invita a periodistas, sociedad civil y cualquier persona interesada en impulsar la alfabetización de los datos a postularse al programa de Fellows 2016, que abarca de abril a diciembre 2016. Hay hasta 10 selecciones abiertas y la fecha límite para postular es el 10 de marzo, 2016.
¡Postúlate ahora!
Las fellowships son posiciones de 9 meses con entrenadores, especialistas y entusiastas de Escuela de Datos. Durante este periodo de tiempo, los y las fellows trabajan como parte de la red de Escuela de Datos desarrollando nuevas habilidades y conocimientos ya sea relacionados con una temática social, la construcción de comunidades de datos y la formación para alcanzar un mayor uso de datos.
Como parte de este fellowship, nuestro objetivo conjunto es incrementar la alfabetización de datos y construir comunidades de práctica que cuenten con las habilidades en el uso de datos para poder cambiar su entorno.
Una fellowship temática
Para enfocar el entrenamiento y experiencia de aprendizaje de las y los Fellows de Escuela de Datos 2016, este año se contempla un enfoque temático. Como resultado, se priorizará la selección de postulantes que:
- cuenten con la experiencia en y entusiasmo por un área específica en el entrenamiento de datos
-
Muestren vínculos con organizaciones que se desempeñen en un tema específico o muestren que tienen vínculos cercanos con quienes abordan esta temática de manera directa
Estamos buscando a individuos involucrados que ya cuentan con conocimiento profundo de un sector o tema, y que activamente han influenciado el uso de los datos en esa temática dada. Este enfoque permitirá a las y los Fellows iniciar rápidamente actividades y alcanzar lo máximo durante su participación en la Escuela de Datos: ¡nueve meses pasan muy rápido!
Además, ya contamos con organizaciones aliadas dispuestas a apoyar a las y los Fellows interesadas en trabajar los siguientes temas: periodismo basado en datos, industrias extractivas y datos responsables. Estas maravillosas contrapartes orientarán, darán mentoría y brindarán mayor conocimiento en cada uno de estos temas.
< Conoce más sobre el enfoque temático >
Nueve meses para generar un impacto
La Fellowship es de abril a diciembre de 2016 y comprende por lo menos 10 días al mes del tiempo de cada Fellow para trabajar offline y online. La o el Fellow debe fortalecer su comunidad local a través de entrenamientos, apoyando proyectos basados en datos y satisfaciendo sus necesidades para el uso de datos. Virtualmente, la o el Fellow debe participar activamente en la red global de School of Data, compartiendo conocimiento a través de sesiones online, posts en el blog y contribuyendo con la generación y actualización de los recursos de enseñanza de la comunidad. Cada Fellow recibirá un apoyo mensual de $1,000usd por su trabajo.
En mayo de 2016, todos los Fellows seleccionados participarán presencialmente en el tradicional Campamento de Verano (ubicación por definir) en donde se conocerán, compartirán conocimientos y habilidades, aprenderán sobre métodos, tácticas y enfoques de entrenamiento de Escuela de Datos.
¿Qué estás esperando?
Postúlate Ahora
Información clave:
- Fellowships disponibles: hasta 10 fellows, 5 reservados para realizar periodismo basado en datos
-
Fecha límite de postulaciones: 10 de marzo, 2016, medianoche GMT
-
Duración del Fellowship: del 1 de abirl 2016 a diciembre 31, 2016
-
Nivel de actividad: por lo menos 10 días al mes
-
Estipendio: $1,000 usd al mes
Este post es una traducción de https://schoolofdata.org/2016/02/10/apply-now-for-school-of-datas-2016-fellowship/
![]()

Desde hace tiempo, Escuela de Datos participa en conversaciones de muchas de las comunidades de datos distribuidas por varias regiones del mundo. Ahora de la mano de nuestros amigos de Desarrollando América Latina (DAL), emprendemos una aventura que nos lleva a visitar Guatemala, El Salvador y Nicaragua para seguir promoviendo la cultura de los datos abiertos en el marco del Apps Challenge de la región.
En todas estas actividades estarán participando nuestros data sherpas Rubén Moya, actual fellow de Escuela de Datos, y Sergio Araiza, líder datero en SocialTIC.
La aventura comienza en tierra Chapín
La primer parada es Guatemala, y ahí, en colaboración con Congreso Transparente y Plaza Pública estaremos participando en la primer sesión de ideación y hackatón DAL el día sábado 25 de octubre. Impartiendo la charla “Hacking cívico en Latinoamérica” mostraremos muchos de los proyectos dateros que están sucediendo en varios países de LATAM y que hemos conocido gracias a las contribuciones que nos envían lectores y seguidores por nuestras redes sociales y la página (no dejen de hacerlo).
Los días lunes 27 y martes 28 de octubre en las instalaciones de la Universidad Landivar impartiremos la primera de las expediciones de datos que haremos en el tour. Compartiremos experiencias y conocimiento con Rodrigo Baires, editor del área de datos en Plaza Pública. La sesión está enfocada en que periodistas y programadores aprendan técnicas sobre manejo de datos y narrativas basadas en datos.
Si quieres participar o tienes dudas, puedes estar en contacto con los organizadores:
- Congreso Transparente: @CongresoT
- Plaza Pública: @PlazaPublicaGT
Escuela de Datos presente en El Salvador
Nuestro tour continúa en El Salvador con la compañía de la embajadora de OKFN y coordinadora local de DAL, Iris Palma. La actividad comienza el 29 por la tarde: nuestra segunda expedición de datos con la compañía de Alexis Rojas, líder técnico del portal http://www.datoselsalvador.org. La invitación está abierta para que ONG, periodistas y programadores nos ayuden a resolver la pregunta que da inicio a toda expedición: ¿qué dicen los datos?
Aún hay más en la tierra de las pupusas. El día 30 realizaremos una sesión de acompañamiento a los equipos de desarrolladores que están participando en la iniciativa local de DAL. Si tienes una idea o quieres ayuda con tu proyecto, escríbenos y participa.
Nicaragua: datos y hackatón… ¡¡Ea, ea!!
Nuestro tour concluye en Nicaragua, en donde nuestros amigos de IEEPP están organizando un verdadero festival de los datos abiertos para concluir la semana. Agárrense.
Todo inicia el viernes 31 con un panel sobre periodismo de datos en el que participan:
- Romina Colman, La Nación Argentina
- Juan Manuel Casanueva, director de SocialTIC A.C. y ICFJ Knight Fellow
- Hassel Fallas, La Nación Costa Rica.
Terminando la sesión, nos teletransportamos al primer Data Meetup en Nicaragua, en el que desarrolladores inscritos en DAL y expertos sociales presentarán los retos que serán atacados durante el hackatón de la iniciativa.
Y como ya mencionamos, el día sábado comienza el código con el arranque del hackaton DAL Nicaragua 2014 en el que, además de dar apoyo a los equipos, estaremos llevando una expedición de datos con grupos de ONGs y periodistas que participan en el evento.
¡Se viene una semana llena de datos y hacking! No se pierdan ni un detalle de las actividades en Twitter y Facebook, y no olviden que, si tienen algún proyecto que compartir o quieren participar en alguna actividad, pueden escribirnos a la dirección [email protected]
![]()