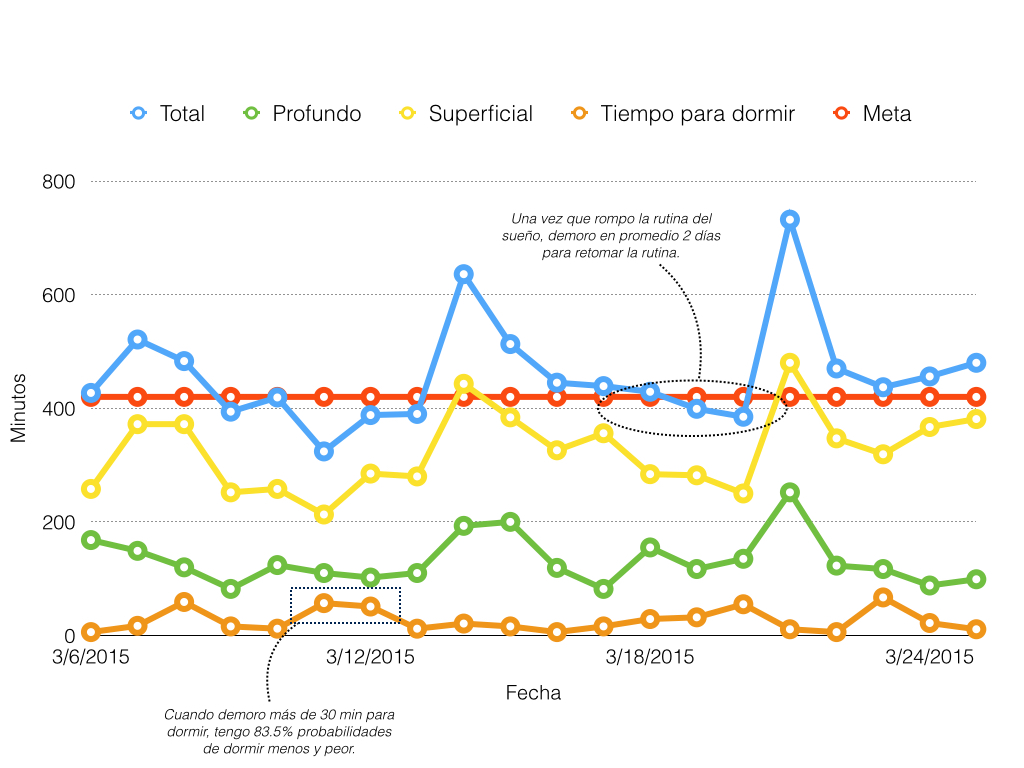
Exploración de datos para transformar una organización
cristian - el junio 22, 2015 en Uncategorized
Siempre recuerdo una de las tantas frases célebres que Henry Ford nos regaló. Si bien no soy capaz de citarlo textual, Ford decía algo como “no debes saberlo todo. Pero si debes conocer a quién sabe hacerlo”.
A su vez, Teddy Roosevelt decía que la persona más valiosa es aquella que intenta hacer las cosas, independiente de los obstáculos que encontraba.
Ambos son grandes hombres. Visionarios y capaces de empujar contra todo a fin de lograr sus metas. Con los datos pasa algo similar. Tras años acumulando información y con miles de teras generándose cada día, es imperante enfrentar el desafío no sólo para tener una ventaja competitiva, sino para transformar la manera en la cual las empresas hacen negocios.

Henry Ford
Ahí entra Ford. No te asustes. No tienes que saber cómo se hace. Pero si debes ver el valor de los datos y entender cómo pueden ayudarte a progresar.
- Roosevelt = hacer
- Ford = visión
¿Qué hubiese hecho Ford si estuviese vivo? Pues buscar las preguntas más relevantes para mejorar la empresa. El primer paso para comenzar una expedición de datos es saber el “qué” “cómo” “cuándo” o “dónde”.
Somos realmente afortunados al vivir en una época donde los precios hacen que capturar y almacenar datos sea realmente barato. Además tenemos el conocimiento al alcance de todos.
Ahora, la visión es clave. El no necesariamente saber cómo se hace sino para qué.
La intersección está entre habilidades para hackear, conocimiento matemático (y estadístico) y el expertise propio del área donde trabajas. Es ahí, entremedio, donde yace la ciencia de los datos.
¿Y cómo se puede comenzar a generar un cambio usando datos?
- Pues definiendo la pregunta
- Definiendo el grupo ideal de datos
- Determinando a qué data tengo acceso
- Obteniendo la data
- Limpiándola
- Realizando una exploración de datos
- Haciendo una modelación estadística
- Interpretando resultados
- Poniendo en duda los resultados
- Resumiendo resultados
- Creando código que se pueda reproducir
- Distribuyendo la información con más personas
Si te has fijado, jamás he hablado de la herramienta para analizar los datos. En lo personal uso R, pero ¿importa? Pienso que sin un set de preguntas relevantes la herramienta no es relevante.
Ahora la pregunta es ¿qué tipo de pregunta?
- Descriptiva: sólo describe lo que se ve. No se toman decisiones.
- Exploratoria: Ideal para descubrir nuevas conexiones, para encontrar, definir y confirmar la exploración que estamos llevando a cabo (o futuras expediciones)
- Inferencial: Tomas una pequeña muestra de datos y luego extrapolas la información a un grupo mucho mayor.
- Predictiva: La meta es usar la data de ciertos objetos para predecir los valores de otros objetos
- Causal: Que genera cierto comportamiento ¿qué pasa si cambio los valores de una variable?
- Mecanística: Busca comprender los cambios exactos y variables que llevan a generar cambios en otra variable.
Pues bien, pienso que el escenario queda mucho más claro. Sin embargo, queda por responder una pequeña pregunta
¿Qué son los datos?
Variables cuantitativas o cualitativas las cuales están agrupadas en un set de ítems.
- cualitativo: país de origen, género.
- cuantitativo: peso, altura, tipo de sangre.
- variable: medidas o características de un ítem
¿Y la expedición?
Pues tal como hiciera, Harry Bingham -el británico que (supuestamente) descubrió Machu Picchu- debemos comenzar con nuestro machete a abrirnos paso en una jungla poblada de “ruido” o datos que nos llevan lejos del El Dorado.
El diseño de experimentos tiene como base la formulación de la(s) pregunta(s).

Cuando hemos explorado la data y confirmado que es relevante podemos tomar una muestra menor, analizarla con estadísticas descriptivas, hacer inferencias y extrapolarlo a la población total.
Sin embargo debemos estar atentos al “cofounding” o alguna variable oculta que pueda generar cambios que pensamos, son motivo de otra variable
Como ves en la foto, el consumo de chocolate tiene relación directa con el número de premios Nobel ¿o no?

Para comprender bien qué está sucediendo al interior de los datos deberás poder replicar tu experimento, medir las variables, generalizar sobre el problema que convoca y tener transparencia con la información manipulada.
Pienso que nadie tiene muy clara la película, pero sí está la intención “you halfway there”. Cada organización oculta desafíos propios, cada una también tiene su propia data governance.