¿Te has encontrado con bases de datos que tienen pequeños errores de transcripción? ¿Espacios de más, uso desordenado de mayúsculas y minúsculas, o registros que representan al mismo dato pero que fueron escritos con pequeñas diferencias? Con la herramienta OpenRefine puedes automatizar mucho del doloroso proceso de limpiar una base de datos. En este tutorial te enseñaremos una de sus funciones más útiles: la clusterización —o generación de agrupaciones automáticas— y los diferentes algoritmos que determinan las coincidencias entre registros.
El concepto de clusters (o agrupaciones, en español) se utiliza mucho en ciencias sociales y exactas para referirse a un tipo de análisis que toma un conjunto de datos y las reorganiza en grupos con características similares.
En OpenRefine, cuando uno hace clusters significa que el programa está encontrando grupos de valores diferentes que pueden ser representaciones alternativas del mismo valor. Por ejemplo, si hablamos de ciudades, “New York”, “new york” y “Nueva York” son tres valores diferentes pero que se refieren al mismo concepto, sólo con cambios de idioma y de uso de mayúsculas y minúsculas.
Vale la pena mencionar que las agrupaciones en OpenRefine sólo se generan automáticamente en la sintaxis (o sea, el orden y la composición de caracteres que tiene como valor una celda) y aunque estos métodos son útiles para encontrar errores e inconsistencias, no son lo suficientemente avanzados para determinar agrupaciones a nivel semántico (o sea, el significado de un valor).
Estos métodos se pueden aplicar determinando cuántos grados de cercanía -en otras palabras, qué tan estrechas o flojas quieres encontrar las coincidencias-. Al graduar la cercanía encuentras coincidencias más o menos exactas. Por eso es importante que si bien, los algoritmos ayudan a automatizar la tarea de limpieza, un ojo y cerebro humano va administrando qué tan agresivas deben ser estas uniones para encontrar coincidencias, para evitar que asocie datos que no deberían ir juntos.
Conozcamos los algoritmos: En qué consisten estas metodologías
Existen dos grandes metodologías para hacer clusters: la colisión clave y el vecino más cercano. Open Refine utiliza diferentes variantes de estos dos métodos. Aquí te explicamos cuál es el proceso detrás de cada uno.
Sección 1: Métodos de colisión clave
Estos se basan en la idea de crear una representación alternativa de un valor inicial, el cual se convierte en una clave. Una clave contiene las partes más distintivas y significativas de un valor. OpenRefine va buscando en los demás registros qué otros valores se parecen a esta clave para agruparlos. El procesamiento requerido para este método no es muy complejo, por lo que presenta resultados muy rápidos. Este método tiene varias funciones diferentes que se pueden administrar en OpenRefine.
- Fingerprint
Un método fácil y simple. Quita todos los espacios en blanco, cambia todos los caracteres a minúsculas, remueve toda la puntuación y normaliza cualquier caracter especial a una versión estándar. Luego, parte el texto y aplica espacios en blanco. Así encuentra las coincidencias.
- N-Gram Fingerprint
Es similar al anterior, pero en vez de separar los caracteres por espacios en blanco, usa una cantidad a la enésima (n) potencia de espacios que el usuario puede determinar.
- Fingerprint Fonético
Este método no revisa los caracteres textuales sino su pronunciación y fonética: la manera en que esa palabra se pronunciaría, en vez de revisar similitudes en la escritura. Es muy útil para limpiar datos con nombres particulares, ya sea de lugares y personas. En ocasiones, los errores de registro se deben a que se registran a partir de la pronunciación. Sirve para encontrar similitudes entre sonidos parecidos pero que se escriben muy distinto como el sonido de “sh” y “x”, que en ocasiones son similares.
Sección 2: Vecino más cercano (Nearest neighbor)
Estos métodos proveen un parámetro o radio de aproximación alrededor de un valor o palabra, y va encontrando los grados de similitud entre éste y otros registros. Debido a los cálculos necesarios, estos métodos son más tardados en procesar.
- Distancia Levenshtein
Este método se basa en el trabajo y proceso que implicaría cambiar a un registro A para que sea igual a un registro B. La distancia Levenshtein mide cuántas operaciones de edición -o cuántos pasos- le tomaría a alguien hacer que un dato se parezca al otro. Encuentra coincidencias entre los datos que están separados por la menor cantidad de pasos o cambios.
Por ejemplo, “Paris” y “paris” tienen una distancia de edición de 1, ya que solo se debe cambiar la P mayúscula a una minúscula. Sin embargo, “Nueva York” y “nuevayork” tienen una distancia de 3 pasos: dos sustituciones y un borrón.
- PPM (Prediction by Partial Matching)
Este método se utiliza para encontrar coincidencias en secuencias de ADN. Estima la similitud entre textos y determina su contenido idéntico. Por ejemplo, con el ADN encuentra similitud entre dos muestras para indicar un grado de familiaridad. Es común en este campo que no se busque una coincidencia exacta (que implicaría trabajar con muestras de ADN de la misma persona) sino encontrar un alto grado de coincidencia y familiaridad.
Si dos cadenas A y B son idénticas, al concatenar A+B debería de producirse muy poca diferencia. Pero si A y B son diferentes, al concatenar A+B se deberían producir diferencias muy dramáticas en la longitud de la cadena.
Paso a paso. Aplicando los clusters en OpenRefine
 OpenRefine es un programa que corre a través de tu browser o navegador de internet. Para instalarlo, es necesario que lo descargues en este link y sigas las instrucciones para tu equipo. Usualmente, solo requiere que descargues la carpeta, la descomprimas y abras la aplicación.
OpenRefine es un programa que corre a través de tu browser o navegador de internet. Para instalarlo, es necesario que lo descargues en este link y sigas las instrucciones para tu equipo. Usualmente, solo requiere que descargues la carpeta, la descomprimas y abras la aplicación.
OpenRefine debería abrir una ventana negra con algunos códigos y abrirse automáticamente en tu navegador de internet. Si no funciona, prueba ir a la dirección http://127.0.0.1:3333/
Vamos a hacer un ejemplo con un conjunto de datos sobre financistas a las elecciones del 2017-2018 en Estados Unidos que puedes descargar aquí.
Para subir el archivo, solo sigue los siguientes pasos:
Create project > Elegir archivo (selecciona el archivo ZIP que descargaste) > Next
OpenRefine te mostrará una previsualización de tu conjunto de datos. En este caso, deberás desmarcar la opción >Parse Next para indicar que tu base de datos no tiene títulos de columna en la primera fila.
En >Project Name, escribe “Financiamiento político_Estados Unidos 2017-2018” y da click a >Create project para guardar este proyecto.
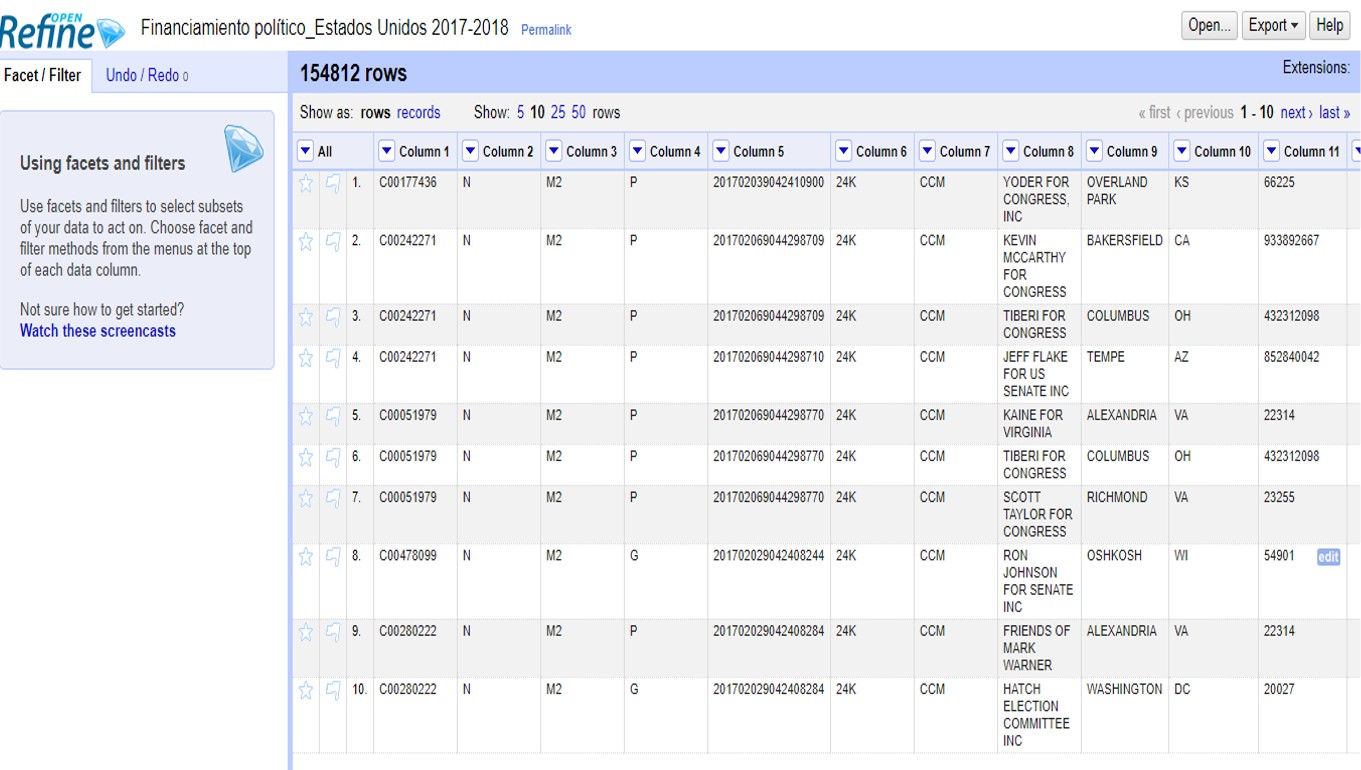
En la columna 8 encontrarás el listado de financistas. Haciendo click en el triángulo a la par del título de esta columna, selecciona >Facet >Text facet para generar un filtro de texto.
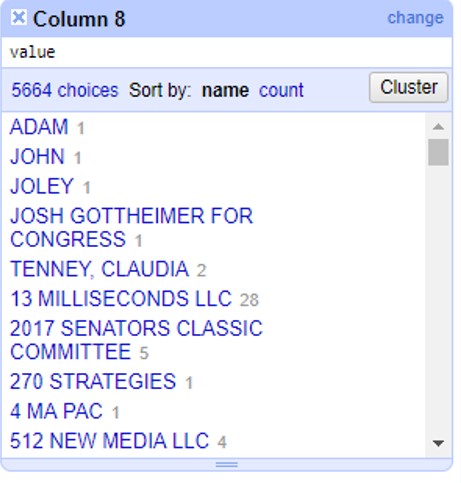
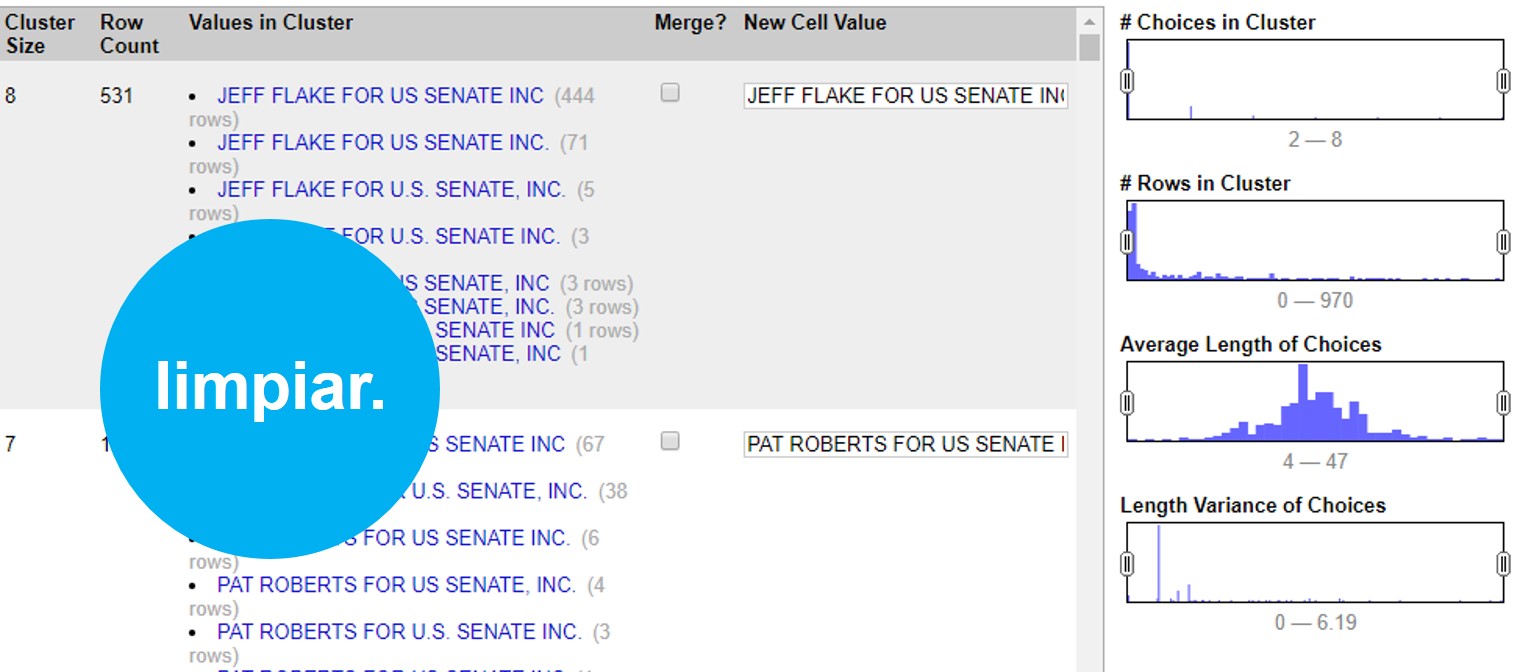
A un lado, te aparecerán todos los registros de financistas en orden alfabético, con un número a la par que indica cuántas veces aparece este nombre en la base de datos. Haz click en el botón >Cluster para empezar a generar agrupaciones automáticas.
En la siguiente ventana puedes aplicar todos los métodos de clusters que te enseñamos. Puedes administrarlo cambiando las opciones >Method, >Keying Function o >Distance Function.
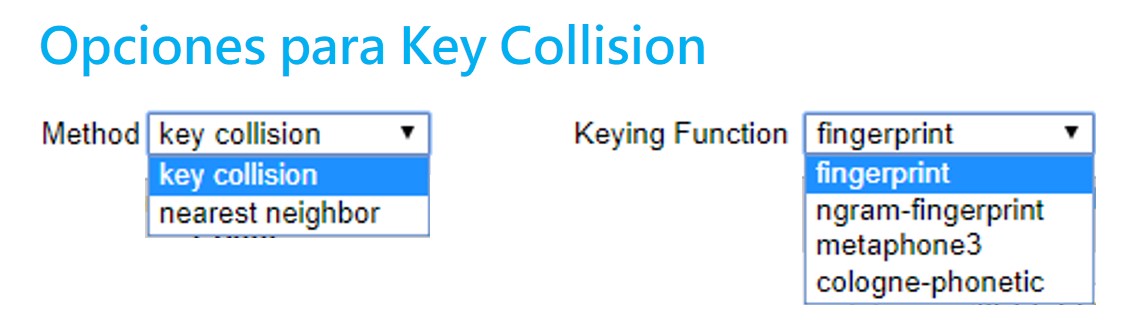

Con estos controles podrás ir determinando qué tan agresivos son tus clusters. Independientemente del método que eligas, el proceso es el mismo. Al seleccionar el método y sus opciones, OpenRefine comenzará a procesar los datos para encontrar coincidencias y armarlas en un cluster o agrupación.
En este ejemplo podemos ver que el programa encontró 531 valores muy similares, escritos de 8 maneras diferentes para decir lo mismo: que un financista se llama “JEFF FLAKE FOR U.S SENATE, INC”. Como puedes ver, a la par de cada manera de escribir, OpenRefine te muestra cuántas veces aparece de esta manera el valor.
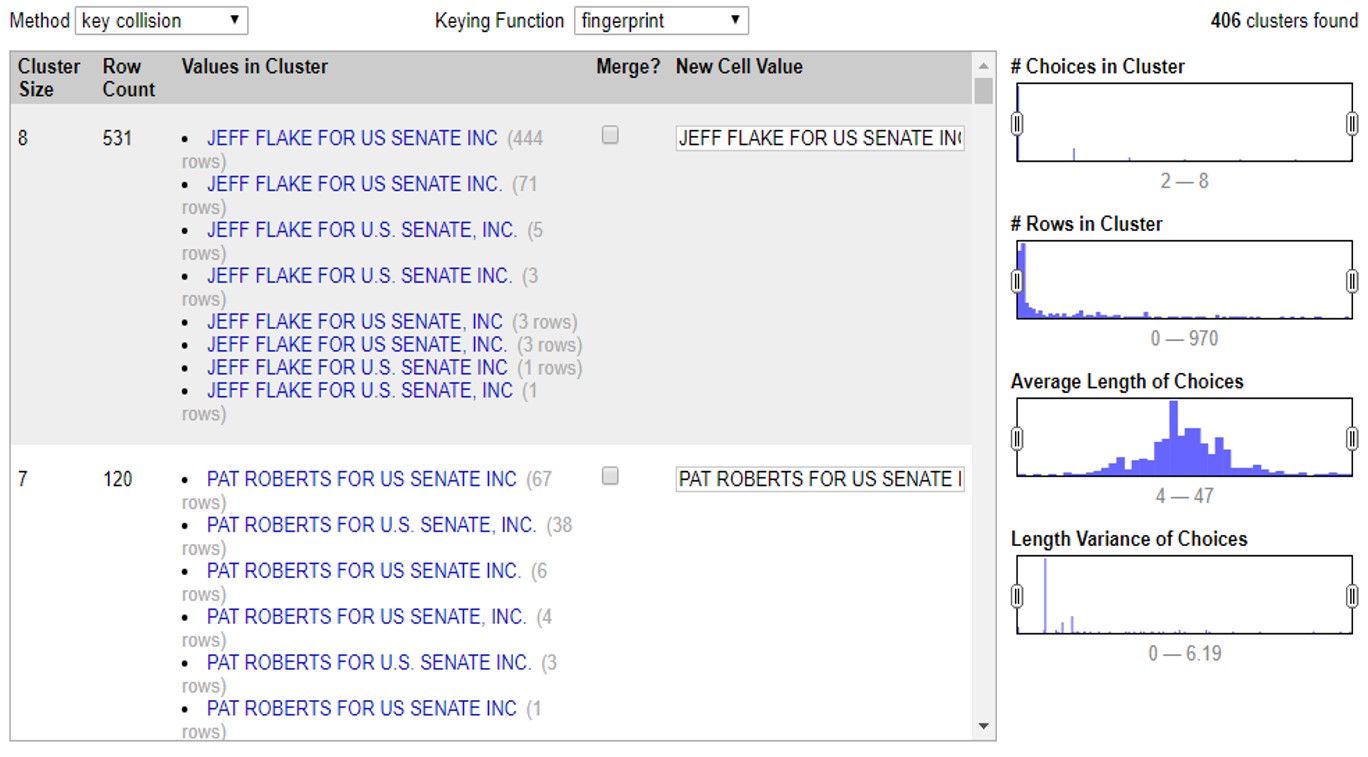
En este caso te muestra dos opciones. La primera, >Merge incluye una casilla que puedes seleccionar en caso de que sí quieras que OpenRefine una estos valores. En la segunda opción >New Cell Value, el programa te da la oportunidad de que edites y decidas de qué manera quieres que se reescriba este cluster. Así, irás administrando la agrupación valor por valor, decidiendo si quieres o no agrupar los valores con >Merge y la opción de escritura bajo la cual estos valores se agruparán con >New Cell Value
Con este ejemplo, si aceptas todas las agrupaciones de cluster que te permite el método >Key Collision >Fingerprint verás como la columna de financistas pasó de tener 5,664 opciones diferentes, a tener 5,136 registros diferentes. 528 valores menos que eran repetidos pero contenían errores gramaticales o de sintaxis que hacían que la computadora no los tomara como iguales.
Así, en estos sencillos pasos, OpenRefine editó los valores de 54,807 celdas que manualmente tomarían demasiado tiempo para limpiar y estandarizar.
Para finalizar, haz click en >Export para descargar tu base de datos limpia en el formato que prefieras.Ya sea valores separados por coma, o por tabulaciones; formato para Excel o HTML, OpenRefine te permite escoger entre diversos formatos para descargar la versión limpia de tu base de datos.
Cuéntanos en qué casos puedes utilizar los clusters y OpenRefine para limpiar tus datos. Escríbenos a [email protected] o por twitter @escueladedatos y estaremos compartiendo algunos ejemplos de usos de esta herramienta.
![]()
Desde Escuela de Datos, Sebastián Oliva, fellow 2017, enseña cómo usar Python para generar mapas a partir de datos georreferenciados.
Mapas y Python
Es obvia la importancia de los mapas, para la visualizacion de datos. Las coordenadas, latitud y longitud, pueden describir un punto sobre la tierra. Utilizamos estandares como WGS-84 para atar esas coordenadas a un punto real.
Utilizando MatPlotlib, podemos aprovechar Basemap, una libreria que provee funcionalidad básica de mapa, con la cual podemos construir y componer. Agregar poligonos, puntos, areas, barras, colores, etc; se hace mediante estas librerias.
Librerias
La libreria mas utilizada en el ecosistema Jupyter-Matplotlib es Basemap. Tambien existen otras, entre ellas, Plotly, que son muy poderosas y convenientes pero tienen dependencias externas.
- Basemap: el «industry standard». Un poco complicado para el setup, bastante poderoso e integrado con matplotlib.
- Plotly: Una libreria que permite desplegar datos mediante Javascript en la Web
- QGis: Una aplicación completa para el manejo de datos GIS, tiene bindings en Python y es posible utilizar como libreria para aplicaciónes tanto GUI como en notebooks o para analizar en scripts y exportar.
- OSMnx: Basada en Open Street Map, Permite tanto analisis como visualización de mapas a nivel de calle, region, ciudad y más.
Para este webinar, vamos a indagar mas en Basemap, que es el mas accesible.
Basemap
Basemap es una extensión de la funcionalidad disponible
Existen varias formas de instalarlo, así que puede ser un poco confuso. Dependiendo de el método en el cual tengas instalado matplotlib hace variar la forma apropiada de instalarlo.
Ambiente de Trabajo
$ #ESTE_ENV = midevenviroment $ source ~/miniconda3/envs/$ESTE_ENV/bin/activate $ conda install jupyter-notebook $ conda install gdal -c conda-forge $ conda install basemap -c conda-forge $ conda install pandas seaborn ## En caso hayan instalado basemap en algun directorio no standard: utiliza un link para la carpeta data. $ ln -s /home/tian/miniconda3/pkgs/basemap-1.1.0-py36_2/lib/python3.6/site-packages/mpl_toolkits/basemap/data/ /usr/share/basemap
In [16]:
# Importamos lo ya usual. import matplotlib.pyplot as plt import matplotlib.cm import pandas as pd import numpy as np import seaborn # Algunas librerias extra que usaremos from matplotlib.colors import Normalize import matplotlib.colors as colors from numpy import array from numpy import max # Aqui cargamos Basemap from mpl_toolkits.basemap import Basemap from matplotlib.patches import Polygon from matplotlib.collections import PatchCollection sns.set(style="white", color_codes=True) %matplotlib inline
Mapeando los terremotos globales de la ultima semana
Vamos a usar la feed de datos del US Geological, ellas tienen disponibles datos referenciados de actividad geologica a nivel mundial, regional y de EEUU.
In [17]:
quakes = pd.read_csv("http://earthquake.usgs.gov/earthquakes/feed/v1.0/summary/1.0_week.csv")
# Creamos la lista de latitudes y longitudes.
lats, lons = list(quakes['latitude']), list(quakes['longitude'])
In [60]:
mags = list(quakes['mag']) quakes.head()
Out[60]:
| time | latitude | longitude | depth | mag | magType | nst | gap | dmin | rms | … | updated | place | type | horizontalError | depthError | magError | magNst | status | locationSource | magSource | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2017-10-31T16:29:08.330Z | 36.746834 | -121.467163 | 9.00 | 2.78 | md | 56.0 | 61.0 | 0.02078 | 0.15 | … | 2017-10-31T16:32:56.802Z | 11km SW of Ridgemark, California | earthquake | 0.24 | 0.45 | 0.16 | 66.0 | automatic | nc | nc |
| 1 | 2017-10-31T16:23:50.380Z | 19.839001 | -155.555664 | 23.85 | 2.06 | md | 44.0 | 110.0 | 0.08413 | 0.13 | … | 2017-10-31T16:27:14.110Z | 23km SSE of Waimea, Hawaii | earthquake | 0.61 | 0.81 | 0.19 | 8.0 | automatic | hv | hv |
| 2 | 2017-10-31T16:15:45.210Z | 37.603668 | -118.955666 | 1.43 | 1.08 | md | 8.0 | 198.0 | 0.01381 | 0.02 | … | 2017-10-31T16:25:02.360Z | 5km SSE of Mammoth Lakes, California | earthquake | 1.38 | 1.29 | 0.17 | 6.0 | automatic | nc | nc |
| 3 | 2017-10-31T16:14:54.100Z | 37.598167 | -118.954330 | 1.40 | 1.43 | md | 21.0 | 150.0 | 0.01940 | 0.03 | … | 2017-10-31T16:23:02.354Z | 5km SSE of Mammoth Lakes, California | earthquake | 0.34 | 0.70 | 0.26 | 19.0 | automatic | nc | nc |
| 4 | 2017-10-31T15:54:17.460Z | 19.265667 | -155.392166 | 3.49 | 2.34 | ml | 47.0 | 106.0 | 0.02847 | 0.21 | … | 2017-10-31T16:00:00.580Z | 11km NE of Pahala, Hawaii | earthquake | 0.37 | 1.25 | 0.32 | 8.0 | automatic | hv | hv |
5 rows × 22 columns
Iniciemos con el mapa
In [25]:
eq_map = Basemap(projection='robin', resolution = 'l', area_thresh = 1000.0,
lat_0=0, lon_0=-130)
eq_map.drawcoastlines()
eq_map.drawcountries()
eq_map.fillcontinents(color = 'gray')
eq_map.drawmapboundary()
plt.show()
/usr/lib64/python3.6/site-packages/mpl_toolkits/basemap/__init__.py:1631: MatplotlibDeprecationWarning: The get_axis_bgcolor function was deprecated in version 2.0. Use get_facecolor instead.
fill_color = ax.get_axis_bgcolor()
/usr/lib64/python3.6/site-packages/mpl_toolkits/basemap/__init__.py:1775: MatplotlibDeprecationWarning: The get_axis_bgcolor function was deprecated in version 2.0. Use get_facecolor instead.
axisbgc = ax.get_axis_bgcolor()
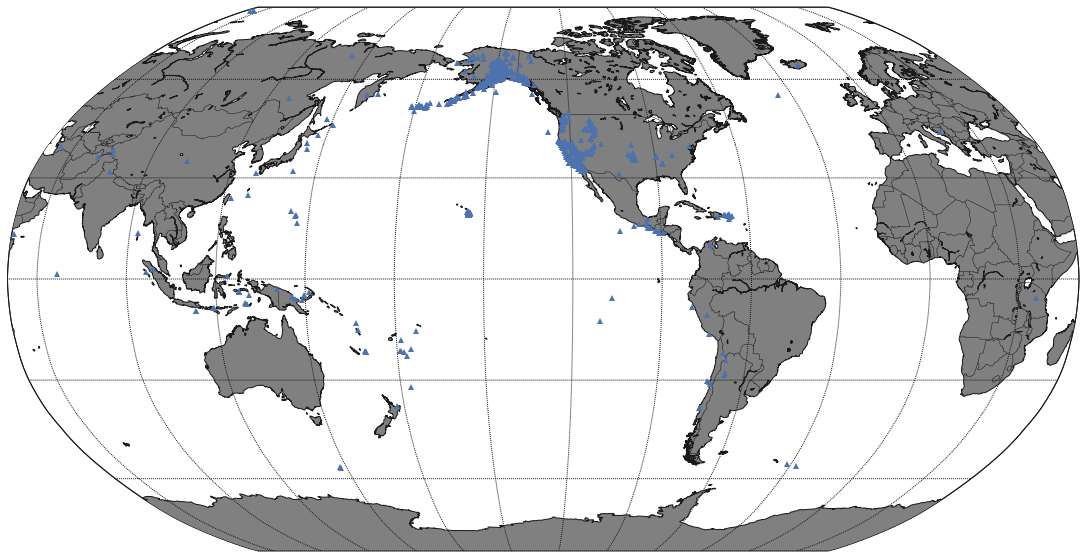
In [64]:
figu, ax = plt.subplots(figsize=(20,10))
eq_map = Basemap(projection='robin', resolution = 'l', area_thresh = 1000.0,
lat_0=0, lon_0=-130)
eq_map.drawcoastlines()
eq_map.drawcountries()
eq_map.fillcontinents(color = 'gray')
eq_map.drawmapboundary()
eq_map.drawmeridians(np.arange(0, 360, 30))
eq_map.drawparallels(np.arange(-90, 90, 30))
## Coordenadas a posiciones
x,y = eq_map(lons, lats)
eq_map.plot(x, y, '^', markersize=6)
plt.show()
/usr/lib64/python3.6/site-packages/mpl_toolkits/basemap/__init__.py:1631: MatplotlibDeprecationWarning: The get_axis_bgcolor function was deprecated in version 2.0. Use get_facecolor instead.
fill_color = ax.get_axis_bgcolor()
/usr/lib64/python3.6/site-packages/mpl_toolkits/basemap/__init__.py:1775: MatplotlibDeprecationWarning: The get_axis_bgcolor function was deprecated in version 2.0. Use get_facecolor instead.
axisbgc = ax.get_axis_bgcolor()
/usr/lib64/python3.6/site-packages/mpl_toolkits/basemap/__init__.py:3298: MatplotlibDeprecationWarning: The ishold function was deprecated in version 2.0.
b = ax.ishold()
/usr/lib64/python3.6/site-packages/mpl_toolkits/basemap/__init__.py:3307: MatplotlibDeprecationWarning: axes.hold is deprecated.
See the API Changes document (http://matplotlib.org/api/api_changes.html)
for more details.
ax.hold(b)
In [33]:
x[0]
Out[33]:
17740352.000926033
Veamos esto mas a detalle.
In [28]:
df = pd.read_csv('hiv_cr_data.csv')
df.columns
df.shape # (71, 8)
df.describe()
df.columns
df.loc[df.coordenadas == df.coordenadas]
subset = df.loc[df.coordenadas == df.coordenadas]
coordenadas = subset[['sitio','latitud', 'longitud', 'coordenadas']]
coordenadas.head()
Out[28]:
| sitio | latitud | longitud | coordenadas | |
|---|---|---|---|---|
| 0 | Esquina Sureste de la Iglesia del Corazón de J… | 10.018010 | -84.216480 | (10.01801 , -84.21648) |
| 1 | Parque Central de Alajuela | 10.016787 | -84.213914 | (10.016787 , -84.213914) |
| 2 | Parque de las Palmas, costado sur del hospital… | 10.020168 | -84.214064 | (10.020168 , -84.214064) |
| 3 | Mall Internacional | 10.006020 | -84.212740 | (10.00602 , -84.21274) |
| 4 | Ojo de Agua | 9.985120 | -84.195540 | (9.98512 , -84.19554) |
In [66]:
coordenadas.count()
Out[66]:
sitio 67 latitud 67 longitud 67 coordenadas 67 dtype: int64
In [67]:
coordenadas.coordenadas.head()
Out[67]:
0 (10.01801 , -84.21648) 1 (10.016787 , -84.213914) 2 (10.020168 , -84.214064) 3 (10.00602 , -84.21274) 4 (9.98512 , -84.19554) Name: coordenadas, dtype: object
In [35]:
(10.01801 , -84.21648)
Out[35]:
(10.01801, -84.21648)
In [30]:
fig, ax = plt.subplots(figsize=(10,20))
mapa = Basemap(projection='merc',
lat_0 = 9.74, lon_0 = -83.5,
resolution = 'i',
llcrnrlon=-88.1, llcrnrlat=5.5,
urcrnrlon=-80.1, urcrnrlat=11.8)
mapa.drawmapboundary(fill_color='#479EE0')
mapa.drawcoastlines()
from ast import literal_eval as make_tuple
def unpac(t):
# haciendo trampa en la vida
return pd.Series(make_tuple(t))
def plot_area(pos):
ps = unpac(pos)
x, y = mapa(ps[1], ps[0])
mapa.plot(x, y, 'o', markersize=7, color='#444444', alpha=0.8)
coordenadas.coordenadas.apply(plot_area)
plt.show()
/usr/lib64/python3.6/site-packages/mpl_toolkits/basemap/__init__.py:3298: MatplotlibDeprecationWarning: The ishold function was deprecated in version 2.0.
b = ax.ishold()
/usr/lib64/python3.6/site-packages/mpl_toolkits/basemap/__init__.py:3307: MatplotlibDeprecationWarning: axes.hold is deprecated.
See the API Changes document (http://matplotlib.org/api/api_changes.html)
for more details.
ax.hold(b)
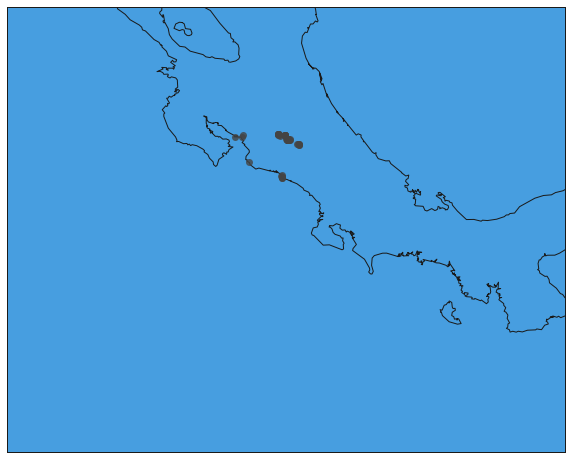
In [12]:
clox = array(coordenadas['longitud']) clay = array(coordenadas['latitud']) clo = list(clox) cla = list(clay)
In [51]:
clay.mean() clay
Out[51]:
array([ 10.01801 , 10.016787, 10.020168, 10.00602 , 9.98512 ,
10.001528, 9.998438, 9.99943 , 9.998952, 9.996179,
9.98495 , 9.99961 , 9.935734, 9.93335 , 9.93284 ,
9.93355 , 9.9356 , 9.9359 , 9.93454 , 9.927243,
9.93387 , 9.93191 , 9.93378 , 9.937275, 9.937206,
9.93281 , 9.868255, 9.864336, 9.864255, 9.86715 ,
9.97685 , 9.99725 , 9.974695, 9.61626 , 9.39646 ,
9.42387 , 9.43062 , 9.930423, 9.930036, 9.934636,
9.929361, 9.937733, 9.930169, 9.927714, 9.934579,
9.927496, 9.93141 , 9.938098, 9.927755, 9.933922,
9.936659, 9.932065, 9.927739, 9.930635, 9.932147,
9.93535 , 9.93286 , 9.927324, 10.018506, 10.018993,
10.002973, 9.408455, 9.39838 , 9.403425, 9.40677 ,
9.866258, 9.865848])
In [58]:
plt.figure(2)
#fig.add_subplot(223)
fig2, ax2 = plt.subplots(figsize=(20,10))
mapa2 = Basemap(projection='merc',
lat_0 = 9.74, lon_0 = -83.5,
resolution = 'i',
llcrnrlon=-88.1, llcrnrlat=7.5,
urcrnrlon=-80.1, urcrnrlat=11.8)
pos_x, pos_y = mapa2(clox, clay)
mapa2.drawmapboundary(fill_color='#A6CAE0', linewidth=0)
mapa2.fillcontinents(color='darkgrey', alpha=0.3)
mapa2.drawcoastlines(linewidth=0.1, color="white")
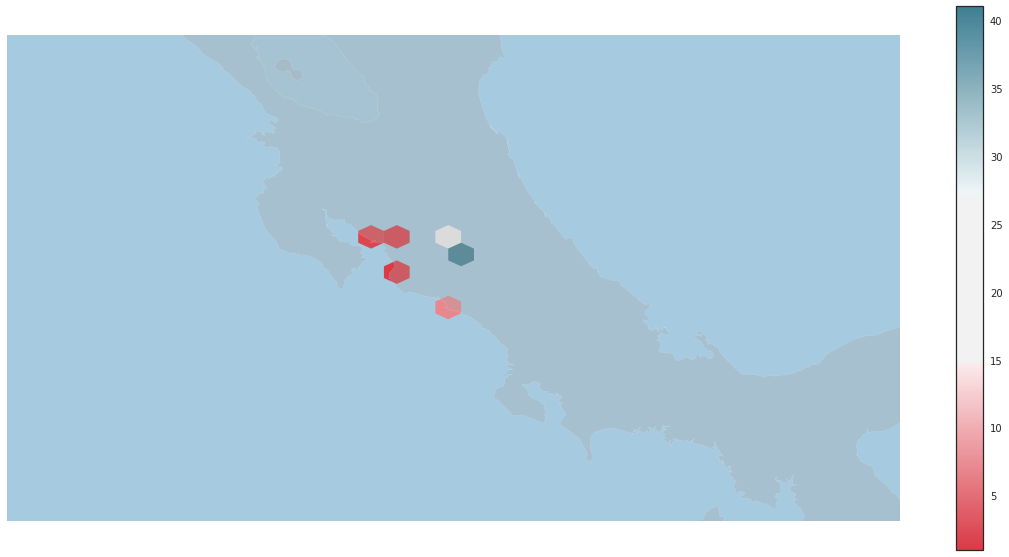
paleta = seaborn.diverging_palette(10, 220, sep=80, as_cmap=True)
#sns.cubehelix_palette(8, start=2, rot=0, dark=0, light=.95, reverse=True)
hb = plt.hexbin(pos_x, pos_y, gridsize=4, mincnt=1,
edgecolor='none', cmap = paleta)
cb = fig2.colorbar(hb, ax=ax2)
plt.show()
/usr/lib64/python3.6/site-packages/mpl_toolkits/basemap/__init__.py:1775: MatplotlibDeprecationWarning: The get_axis_bgcolor function was deprecated in version 2.0. Use get_facecolor instead.
axisbgc = ax.get_axis_bgcolor()
<matplotlib.figure.Figure at 0x7f8646f5d7f0>
Cool links
- http://beneathdata.com/how-to/visualizing-my-location-history/
- https://pypi.python.org/pypi/descartes *
![]()
Ante la urgencia de la creciente oleada de crímenes, algunas organizaciones de sociedad civil como “Cuántas Más” en Bolivia, ven como urgente la necesidad de armar una base de datos recopilando los hechos que además se encuentre abierta al público para que puedan ser consultados por investigadores, periodistas, o cualquier persona que tenga interés de hacer algo más con datos registrados y sistematizados; si en tu país no dispones de fuentes oficiales, aquí te damos algunos criterios que debes considerar para armar la base de datos.
- Diferencia entre datos primarios y datos secundarios. Datos primarios son aquellos que se obtienen a través de una recopilación de datos propia, como la observación de procesos, una encuesta o una entrevista. Los datos secundarios por otra parte son datos que otros ya han recopilado y han puesto a disposición pública. Si estás planeando hacer una recopilación de casos, lo más probable es que recurras a este segundo grupo, con base en estudios, estadísticas de otras organizaciones, o publicaciones de prensa.
- Cuando recopiles datos propios considera que estos pueden ser cuantitativos o cualitativos. Los datos cuantitativos se caracterizan por su enfoque estandarizado y tienen como objetivo verificar, confirmando o refutando, diversas relaciones e hipótesis basadas en números. Los datos cualitativos ofrecen un enfoque abierto y sirven para recoger información que no se pueda representar mediante cifras pero puede dar una mejor comprensión de una cuestión.
- Algunas veces, los datos pueden estar publicados en sitios web pero no existe un link de descarga. En ese caso, te sugiero utilizar una herramienta para la extracción de datos fácil de usar que tiene como objetivo obtener datos de forma estructurada de cualquier sitio web; se trata de import.io y puedes consultar este tutorial para aprender a usarlo.
- Es importante conocer las otras organizaciones que trabajan en la recepción de denuncias de violencia de género o que proveen servicios legales; estas organizaciones también pueden proveer datos fuente de órganos descentralizados, por ejemplo, de carácter municipal, servicios de atención a la salud, el sistema de justicia penal y prestadores de servicios sociales, por nombrar algunos.
- Si vas a obtener tus datos desde información publicada en prensa, trata de cotejar adicionalmente con uno o dos medios; de esta forma garantizas la verificación de los datos publicados y el aumento de aquella información que algún medio no pudo obtener.
- Saca provecho de Google Alerts, un servicio de Google que te permite recibir alertas a tu email cuando el buscador indexa nueva información relacionada con las palabras clave de búsqueda. Con esta herramienta puedes automatizar el proceso de búsqueda o actualizar los resultados de una búsqueda de tu interés a lo largo del tiempo, hasta que decidas eliminar la alerta; programa por ejemplo las palabras feminicidio o mujer asesinada.
- Identifica todos los criterios relevantes para tu primer análisis: nombres, edades, y locaciones suelen ser datos que comúnmente identificamos; sin embargo, la riqueza para análisis de tu base de datos puede estar en los datos que no siempre consideramos como el número de hijos sobrevivientes al hecho, la relación de la víctima con el victimario, el estado del caso y si es que ha obtenido sentencia, el tipo de agresión que se produjo, si es que hubo una denuncia de violencia previa. La granularidad es importante.
- Documenta el proceso, es importante explicar los pasos que seguiste para que las personas interesadas en la base de datos tengan los argumentos completos de tu trabajo. Aquí puedes encontrar algunas opciones para realizar este paso.
- Finalmente escoge la mejor manera de mostrarlos, dependiendo del volumen y el contenido de tu base de datos puedes optar de mostrarlos, por ejemplo, en una línea de tiempo o un mapa. Solo recuerda publicarlos con el enlace de descarga.
Adicionalmente, si te interesa indagar más profundo, CEPAL lanza un curso cada año de introducción sobre estadística e indicadores de género que a la fecha va en su sexta versión. Debes estar atento al lanzamiento de la próxima convocatoria.
![]()
Para poder hacer esa afirmación hice una prueba con las relaciones de los personajes de Narcos, la serie de Netflix, que narra la investigación que llevó a la captura del narcotraficante Pablo Escobar.
Este mapa fue realizado en un poco menos de una hora, recolectando toda la información e insertándola en Onodo. Ahora les explicaré porqué es tan fácil de usar:
- No necesitas ser un experto en Excel, ni siquiera abrirlo. Onodo permite insertar uno a uno los nodos (cada una de las personas, instituciones, etc… que necesitamos poner en el mapa) y también permite personalizar una a una las relaciones de cada nodo dentro de la misma aplicación.


- Es intuitivo, no es necesario leer el manual para usar sus funciones básicas. Ni siquiera existe un manual, si quieres algo parecido puedes ver su demostración en este enlace.
Ahora te explicaré cómo hice este mapa de relaciones en menos de una hora:
- Recolecté los datos de los personajes en IMBd y Wikipedia.
- Inserté los datos de cada personaje como un nodo. Por ejemplo: Pablo Escobar era el líder del Cartel de Medellín. Entonces usé el botón “Añadir nodo” y puse el nombre y la imagen que busqué en Google. Añadí otro nodo para el Cartel de Medellín. Ambos se reflejaron al instante en la visualización.

- Los nodos no están completos sin una relación. Entonces cambié a la pestaña de “relaciones” y hice click en el botón “añadir relación” para indicar que el nodo “Pablo Escobar” es el líder del “Cartel de Medellín”. Esto también se reflejó al instante.

- Así se muestra la visualización al hacer click sobre el nodo de “Pablo Escobar”.

- Luego agregue la información del resto de personajes principales y secundarios de la serie, de la misma manera que hice con Pablo Escobar. Todas se fueron mostrando dentro de la visualización.
- Compartir la visualización dentro de cualquier otro sitio es igual de sencillo. Pulsas en el botón “Comparte” donde harás pública la visualización y después te creará un iframe y un enlace fijo.

Si aún no te convence esta sencilla explicación puedes entrar a este enlace para ver otros mapas de relaciones que han realizado otros usuarios. Y si la explicación te convenció, como usarlo me convenció a mí, puedes entrar a este enlace para crear tu cuenta y empezar a experimentar.
![]()
En la descripción del producto indica que “QDA Miner es un paquete de software fácil en su uso para análisis de datos cualitativos: codificar, anotar, recuperar y analizar pequeñas y grandes colecciones de documentos e imágenes. (…) herramienta de análisis de datos cualitativos puede utilizarse para analizar las transcripciones de entrevistas o grupos focales, documentos legales, artículos de revistas, discursos, incluso libros enteros.”; y además de ello provee una suite de herramientas complementarias de integración como SimStat y WordStat.
Se trata de una herramienta de pago con una versión de prueba de un mes y una versión “lite” gratuita y disponible para descarga a través de un formulario. Sea cual fuera el caso, la instalación es rápida y sencilla y tiene la particularidad de permitirte instalar recursos de lenguaje que podrías utilizar, como ortografía, lematización y tesauro, u ortografía médica y legal.
Puedes seleccionar varios documentos sobre los que quieras trabajar, la herramienta te permite subir documentos tipo .txt, .pdf, .html, .rtf, .doc y otros.


Empezamos con los códigos
Antes de empezar a trabajar con la herramienta es recomendable leer los textos que quieres analizar y empezar a identificar los elementos en común que serán la base para tus futuras codificaciones porque ahí es donde empieza el trabajo con la herramienta.
El sistema de códigos de QDA Miner funciona a partir de un principio de anidación donde escoges un código principal e indicas las variables dentro del mismo; conocer el contenido de tus textos te permitirá empezar a identificar los códigos para empezar a marcar tu documento. Puedes tener tantos códigos como veas necesario.

Para facilitar tu trabajo en la asignación de códigos puedes resaltar, oscurecer o darle colores al texto yendo a la pestaña “Documento”, “Texto Codificado” y escoger de las opciones que mejor te convenga.

Claro que no siempre es posible leer todo el texto completo, aunque esto se recomienda. Pero para darte una mano extra la herramienta dispone de una ayuda en la pestaña “Recuperación”. En el caso de ejemplo, quise buscar todas las oraciones que tuvieran la palabra violencia para identificar si todas han sido codificadas correctamente. Entonces, dentro la pestaña “Recuperación” seleccionamos la opción recuperación de texto que justamente nos permitirá recuperar la palabra de los textos en los que estamos trabajando. Es recomendable expandir las previsualizaciones de los textos y mostrar resultados de la pantalla usando la tabla de codificación para tener un contexto más claro de nuestra búsqueda y los códigos que ya han sido asignados al párrafo en cuestión. Si encuentras una oración o párrafo que tiene relación con tu búsqueda y que no ha sido codificada puedes seleccionar la casilla y hacer doble clic en el código de tu elección.

Uno de los elementos más útiles de esta herramienta es que puedes guardar tus recuperaciones para volver a usarlas más adelante en caso de que aumentes nuevos documentos a tu proyecto. Solo debes ir a donde empezaste la búsqueda, selecciona “Guardar consulta” y en adelante, cuando vuelvas a tu proyecto con más documentos solo tendrás que cargar la consulta previamente guardada.
Paso dos: analizar desde las codificaciones
La opción “Recuperando Código” es útil cuando ya casi terminas de asignar los códigos a tus textos; selecciona los códigos que tengan más relación entre sí y la búsqueda te arrojará los resultados de los códigos seleccionados; nuevamente es recomendable expandir las previsualizaciones de los textos. Lo más útil de esta opción radica en usar las condicionales (por ejemplo: es igual a, cerca de, seguido de, precedido de, etc.) con las que puedes hacer relaciones de los códigos preseleccionados y adicionar uno diferente, en este caso usé los códigos “víctima” y “victimario” y la condicional “cerca de Activista”.

Ahora, ¿cómo se analiza?
Finalmente, puedes analizar tu proyecto codificado identificando la frecuencia de ciertos códigos, para ello ve a la pestaña “Analizar” y selecciona la opción “frecuencia de código”, selecciona los códigos que deseas analizar y te mostrará el resultado de cuántas veces aparece el código y en cuántos casos. Para hacer más sencillo el trabajo selecciona todos tus resultados y selecciona el gráfico para mostrar tus columnas.



La herramienta permite que puedas guardar cada uno de los segmentos trabajados, ya sea como tablas en xls en el caso de los análisis de código o gráficos de frecuencia como imágenes.
Tiene más funcionalidades de las que describo, sin embargo estos tres pasos te permiten conocer la potencialidad general de la herramienta y hacer tus propios descubrimientos en adelante.
![]()