 Un año más, el Día de los Datos Abiertos celebra iniciativas de transparencia en todo el mundo, con más de 200 eventos programados. En Latinoamérica, SocialTIC y Escuela De Datos se une a la celebración en 4 países a través de expediciones de datos, charlas, talleres, meet-ups y rallys dateros.
Un año más, el Día de los Datos Abiertos celebra iniciativas de transparencia en todo el mundo, con más de 200 eventos programados. En Latinoamérica, SocialTIC y Escuela De Datos se une a la celebración en 4 países a través de expediciones de datos, charlas, talleres, meet-ups y rallys dateros.
A la vez, en otros países de la región organizaciones amigas trabajarán alrededor de un mismo objetivo: concientizar sobre la necesidad de abrir los datos públicos para que sean accesibles y puedan ser reutilizados para generar valor.
Este sábado 2 de marzo es el Día de los Datos Abiertos y te compartimos algunos de los eventos programados para celebrarlo. Tú también puedes unirte al evento más cercano y a la celebración mundial usando el hashtag #ODD19.
? Ciudad de México – Sábado 2 de marzo
Toda una kermés datera: un día de talleres, expedición de datos, proyectos, rally de obra pública, retos de datos de la ciudad. Gibrán Mena de SocialTIC estará dando un taller sobre extracción de datos de solicitudes de información de la plataforma Infomex

Conoce más sobre el Evento, su Agenda y Regístrate para participar.
? San José, Costa Rica – Sábado 2 de marzo
La Comisión de Gobierno Abierto junto a organizaciones de sociedad civil, academia y ciudadanía activa organizan un espacio de charlas, talleres y conocimiento.


En este evento, Eugenia Loría, fellow de Contrataciones Abiertas de Escuela de Datos, estará hablando sobre casos de uso en las contrataciones públicas de Costa Rica, así como presentando una guía temática de apertura de datos que desarrolló.
Conoce más sobre el evento, su Agenda y Regístrate para participar.
? La Paz, Bolivia – Sábado 9 de marzo
BoliviaTechHub y Escuela de Datos organizan un encuentro en el que se aprenderá sobre los básicos de Datos Abiertos y Contataciones Abiertas. Luego, se conocerá sobre cómo a través de los presupuestos analizar la equidad de género y se realizará una expedición de datos para abrir información del Sistema de Contrataciones del Estado. Pamela González, fellow de Contrataciones Abiertas de Escuela de Datos estará liderando una sesión.

Conoce más sobre el Evento y Regístrate para participar en estos enlaces.
? Ciudad de Guatemala – Sábado 9 de marzo
Escuela de Datos va a crear un espacio que te permita aprender cómo usar los datos de las contrataciones públicas, además de guiar un ejercicio sobre el proceso y la transparencia. Sofía Montenegro, fellow de Escuela de Datos compartirá los hallazgos de su proyecto sobre transparencia que busca entender cómo funciona este sistema. Además una meet-up con los proyectos de tecnología cívica que buscan incidir en las próximas elecciones generales

El Open Data Day o Día de los Datos Abiertos es una celebración anual de los datos abiertos alrededor del mundo. Distintos grupos crearán eventos locales en este día y utilizarán los datos abiertos en sus comunidades para crear aplicaciones, visualizaciones, liberar datos o publicar análisis sobre el estado de los datos abiertos. Es una oportunidad para mostrar los beneficios de los datos abiertos y potenciar su uso.
Las actividades de este año se concentran en cuatro ejes:
- Ciencia Abierta
- Rastreo de flujos de dinero público
- Mapeo abierto
- Desarrollo equitativo
Puedes conocer los otros eventos que estarán sucediendo en este enlace y así conocer a la comunidad de datos abiertos de tu país en https://opendataday.org/#map

![]()
Esta generación tendrá la oportunidad de trabajar en conjunto con dos instituciones del Gobierno de Costa Rica, así como en colaboración con la Iniciativa Latinoamericana de Datos Abiertos (ILDA) y Escuela de Datos.

Guillermo Durán – Cambio Climático

A Guillermo le interesa hacer entendibles los análisis de datos a través de la visualización. Tiene experiencia en el uso de diferentes tecnologías, como programación en R (tidyverse, shiny y data.table), PostfreSQL, ArcGIS y QGIS.
Su trabajo en biogeografía lo ha llevado a diseñar áreas protegidas en Panamá, georeferenciar los datos de los museos de Historial Natural o trabajar en las distribuciones de ciertas especies en futuros climáticos usando Machine Learning. Guillermo estudió ingeniería forestal en Instituto Tecnológico de Costa Rica y luego obtuvo una maestría en Geografía en la Universidad Estatal de San Francisco, California. Forma parte del Centro de Investigaciones Geofísicas de la Universidad de Costa Rica con el análisis y visualización de modelos climáticos.
Guillermo estará trabajando en utilizar indicadores sobre el estado del medio ambiente, los Objetivos de Desarrollo Sustentable y relacionarlos con el cambio climático junto a la Dirección de Cambio Climático del Ministerio de Ambiente y Energía.
Eugenia Loria – Contrataciones Abiertas
Eugen ia tiene experiencia en el uso de software estadísticos como SPSS, Minitab, JMP, Eviews y lenguajes de programación como R. Busca explicar las contrataciones a través de la relación entre variables y modelos explicativos, así como la evaluación del impacto de los diferentes programas.
ia tiene experiencia en el uso de software estadísticos como SPSS, Minitab, JMP, Eviews y lenguajes de programación como R. Busca explicar las contrataciones a través de la relación entre variables y modelos explicativos, así como la evaluación del impacto de los diferentes programas.
Ha trabajado en la Banca Central de Costa Rica y en órganos multilaterales. Tiene experiencia en la docencia. Su área de fortaleza es la estadística descriptiva y el análisis de datos.
Le interesa usar su creatividad para promover el uso de datos y estadística para la toma de decisiones en el ámbito público. Cree en el poder de la alfabetización en datos. Ve la transparencia como una oportunidad para eficientar el trabajo del sector público.
Eugenia se dedicará a trabajar en Contrataciones Abiertas, una oportunidad para la rendición de cuentas y la transparencia, junto a la Dirección General de Administración de Bienes y Contratación Administrativa del Ministerio de Hacienda.
El programa de la fellowship Datos Abiertos para el Estado Abierto está diseñado para que nuestros fellows puedan organizar talleres, eventos de comunidad en Costa Rica y contenidos educativos, además de generar proyectos de mayor alcance con las instituciones aliadas.Este programa es apoyado por el fondo de transparencia del Banco Interamericano de Desarrollo (BID) y la colaboración de la Fundación Avina.
La Fellowship Estado Abierto continúa con el trabajo desarrollado por ILDA y la Universidad de Costa Rica capacitando a más de 140 personas en el servicio civil, y busca aumentar la conciencia sobre la alfabetización de datos en el sector público y fortalecer comunidades que, juntas, pueden poner en práctica sus habilidades para hacer el cambio que quieren ver en el mundo.
![]()
Como todos los años, esperamos que este año podamos crear espacios para líderes locales y para que más organizaciones se involucren en nuevos y emocionantes retos a la hora de usar los datos.
Luego de revisar cientos de postulaciones alrededor del mundo nuestro equipo se entrevistó con personas con trabajo increíble y potencial. Luego de este proceso no tenemos dudas de que esta generación de fellows logrará proyectos innovadores en sus respectivos espacios.
Te presentamos a la generación 2018 de fellows de Escuela de Datos:
Sofía Montenegro – Guatemala
@smontenegrom

Sofía es una enamorada de la naturaleza y las enseñanzas que esconde. Se ha dedicado a la investigación y las ciencias sociales. Es una politóloga egresada de la Universidad Francisco Marroquín y en 2017 obtuvo un Máster en Opinión Pública y Comportamiento Político en la Universidad de Essex. En este último espacio reforzó su interés por la aplicación de metodologías de datos para la investigación de temas sociales. Le interesa la academia en la manera en que es puesta en acción política y abrir camino para nuevas generaciones de mujeres que participen sin restricciones en el mundo de los datos y la política. A la hora de pensar en datos, le interesa el análisis de redes sociales, la corrupción como fenómeno, los procesos electorales y las diferentes metodologías de investigación.

Pamela Gonzáles – Bolivia
@10PAMELA20
Pamela Gonzáles es una apasionada por la visualización de datos y reducir le brecha digital para las mujeres. Cofundó Bolivia Tech Hub, un espacio colaborativo de proyectos de tecnología que buscan contribuir a que en Bolivia prospere un ecosistema innovador. Es también la embajadora regional de Technovation, un programa basado en San Francisco que busca formar a niñas alrededor del mundo con habilidades para usar la tecnología, emprender y liderar. Se graduó de Licenciada en Ciencias de la Computación en la Universidad Mayor de San Andrés.

Odanga Madung – Kenia
Es el cofundador de Odipo Dev, una firma de ciencia de datos y analíticas que opera en Nairobi brindando servicios a compañías de tecnología y organizaciones sociales. Su mayor interés se encuentra en la intersección entre los datos y la cultura: a través de su trabajo ha podido visualizar y analizar actividades de sus clientes y eventos en Kenia y en el mundo. Su trabajo ha sido parte de artículos en Adweek, Yahoo, BBC, Quartz y Daily Nation, por mencionar algunos. Trabajará en el programa de Open Contracting en Kenia.
Nzumi Malendeja – Tanzania

Trabaja como investigador asociado en una firma independiente de evaluación de BRAC International en Tanzania, donde lidera proyectos de agricultura, salud y educación. Desarrolla plataformas de recolección de datos a través de móviles (como ODK collect y SurveyCTO) las cuales reemplazaron los métodos tradicionales basados en papel. Antes, trabajó como monitor de campo y asistente de investigación en el proyecto de educación SoChaGlobal y Maarifa ni Ufunguo, sobre transparencia en construcción. Estudió en la Escuela de Verano de Métodos de Investigación de la Universidad de Ciencias Aplicadas de Alemania y trabaja en su tesis de la Maestría de Investigación y Políticas Públicas en la Universidad de Dar Es Salaam.
Elias Mwakilama – Malawi

Es profesor en la Universidad de Malawi y coordina los programas de investigación, seminario y estadísticas en el departamento de Matemáticas. Elias estudió matemática aplicada y computacional en operaciones, y tiene un máster en ciencias ma
temáticas. Sus intereses en investigación radican en trabajar con modelos de optimización usando técnicas estadísticas integradas con habilidades en computación
para resolver problemas industriales en la práctica y la teoría. Durante su fellowship espera trabajar con la plataforma de contrataciones públicas para organizaciones sociales en Malawi, junto a Hivos.

Ben Hur Pintor – Filipinas
Es un activista por los datos abiertos y la tecnología open-source que cree que la democratización no solo implica abrir el acceso a datos, sino también su uso y análisis. Es un desarrollador de software con habilidades en datos geoespaciales que ha trabajado en proyectos relacionados a energías renovables y mapeos de riesgo participativos. Actualmente está estudiando un Máster en Ingeniería Geomática en la Universidad de Filipinas. Como parte de Free and Open Source Software (FOSS), es miembro activo de las comunidades de FOSS4G Filipinas y MaptimeDiliman — medios para compartir tecnologías de acceso libre.
 Hani Rosidaini – Indonesia
Hani Rosidaini – Indonesia
Le apasiona cómo la tecnología puede ser adoptada y aplicada a las necesidades de las personas. En su trabajo, combina sus habilidades tecnicas en sistemas de información y ciencia de datos, con su conocimiento sobre los negocios y lo social para ayudar a compañías y organizaciones en Indonesia, Australia y Japón. Hani tiene experiencia como especialista en datos para políticas públicas en la oficina presidencial de Indonesia, en donde analizó la plataforma de integración de datos nacional data.go.id y contribuyó a la generación de políticas públicas basadas en datos, promoviendo su uso en ministerios y agencias, así como en comunidades cívicas y locales.
Un año más de trabajo en equipo
El programa de Fellowships es un proceso complejo en el cual contamos con la ayuda de aliados, socios y financistas diversos que hacen posible este esfuerzo en tantos países. La generación 2018 de fellows de Escuela de Datos es posible gracias al apoyo de Hivos, el Banco Interamericano para el Desarrollo (BID), la Fundación Avina y la Iniciativa Latinoamericana de Datos Abiertos (ILDA) en Latinoamérica. El programa de School of Data cuenta también con el apoyo del programa de Open Contracting de Hivos Internacional.
![]()
Al terminar 2017 había 68,5 millones de personas desplazadas en el mundo. Es decir, una de cada 110 personas en el mundo se halla en situación de desplazamiento.
En este artículo, Aranzazú Cruz nos presenta siete proyectos de visualización de datos, elaborados en los últimos tres años, que combinan diferentes narrativas digitales para visibilizar tanto las poblaciones desplazadas y refugiadas en el mundo como sus historias.

Migration trail
Migration trail es un proyecto de Alison Killing y Sarah Saey que utiliza mapas, datos y audio para unir los puntos de una historia que transcurre en las huidas hacia a Europa.
A través de una visualización de datos mapeados, migration trail sigue el viaje en tiempo real de dos personajes, un hombre nigeriano y una mujer siria, que viajan a Europa, durante diez días.
Las voces de los personajes están escritas como un mensaje de mensajería instantánea y aparecen tanto en el sitio web como a través de Facebook Messenger. La historia llega a los usuarios y las usuarias a través de su teléfono, estén donde estén. Además, hay un podcast diario que explora los problemas a los que se enfrentan las personas migrantes en sus huidas.
Este proyecto de visualización y vivencias personales tiene como objetivo retratar las historias individuales de las personas que han llegado a las costas del Mediterráneo en los últimos años, la historia política de las rutas que realizan, y la historia social que llevan a cabo.
Las autoras buscan con esta iniciativa mostrar el poder de los mapas y los datos para contar este tipo de historias.
The New Arrivals
Durante 18 meses, el periódico inglés The Guardian, el periódico francés Le Monde, el periódico español El País y el periódico alemán Spiegel Online han seguido las historias de las comunidades de personas refugiadas recién llegadas a Europa.
Cada uno de los periódicos ha seguido durante 500 días a los protagonistas que ha escogido para elaborar los seis capítulos en los que se narra cómo viven, a qué aspiran, qué les motiva, qué les preocupa, cómo se relacionan con sus conciudadanos, con las autoridades o con las ONG, etc.
Este relato multimedia, The New Arrivals, sobre cómo un grupo de personas migrantes y refugiadas se adapta a una nueva vida en Europa es un proyecto financiado por el European Journalism Center a través de una subvención de la Fundación Bill & Melinda Gates.
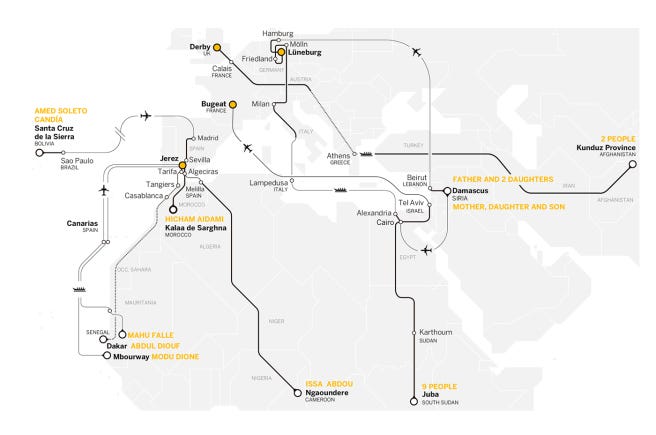
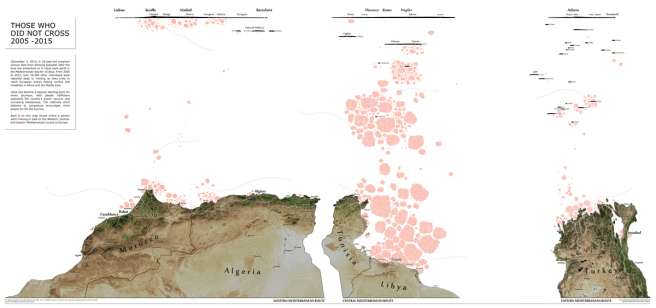
Aquellas personas que no cruzaron
El geógrafo Levi Westerveld ha elaborado un mapa que muestra las personas que fallecieron en el mar Mediterráneo intentando llegar a las costas europeas.
Los datos que se han utilizado para elaborar este proyecto son de The Migrants ‘Files, United y Fortress Europe. El autor ha usado información de más de 3.000 viajes que finalizaron con la muerte de uno o más individuos mientras intentaban llegar a Europa. El mapa incluye la causa de la muerte, la fecha y el lugar del evento, el número de muertos o desaparecidos, y una breve descripción de lo sucedido.
Mapeo de los movimientos mundiales de refugiados
¿Cómo se han desarrollado los movimientos globales de refugiados desde el final de la Guerra Fría? ¿De dónde salen y hacia dónde van las personas refugiadas?
Este proyecto, realizado por Departamento de Ciencias Políticas de la Universidad de Zurich, ofrece una visualización interactiva espacial y temporal de datos recopilados por la Agencia de las Naciones Unidas para los Refugiado (ACNUR)
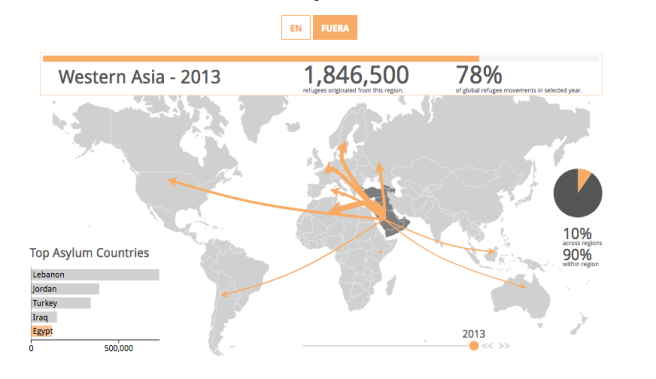
Al desplazarse hacia abajo en la página web, el usuario puede explorar los datos sobre los desplazamientos mundiales de refugiados y seguir la narración de historias sobre los movimientos de personas refugiadas hacia y desde la región del Cuerno de África.
The Refugee Project
Este proyecto de visualización interactivo permite a los usuarios explotar todos los flujos de personas refugiadas desde 1975.
A medida que el mapa interactivo avanza a lo largo de los años, revela la frecuencia de las crisis migratorias, el país de origen y la escala del éxodo de cada país. Al seleccionar cada país se muestran los datos exactos de las solicitudes de asilo por año.
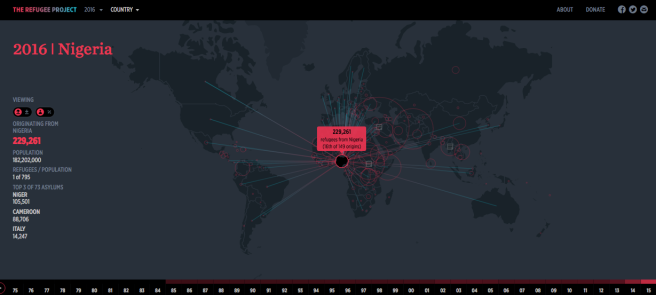
Este proyecto combina los datos de ACNUR con 100 relatos narrativos contextuales que detallan los acontecimientos que desencadenaron las principales crisis de refugiados de las últimas cuatro décadas.
Movimientos, necesidades y ayuda en situaciones de crisis migratorias
ONE Campaign ha creado una herramienta que reúne los datos sobre los movimientos de las personas refugiadas y desplazadas, las necesidades y los niveles de financiación necesarias para apoyar a las poblaciones vulnerables.
Este proyecto permite al lector hacerse una imagen completa de las necesidades que existen y el apoyo necesario para acabar con las crisis humanitarias.
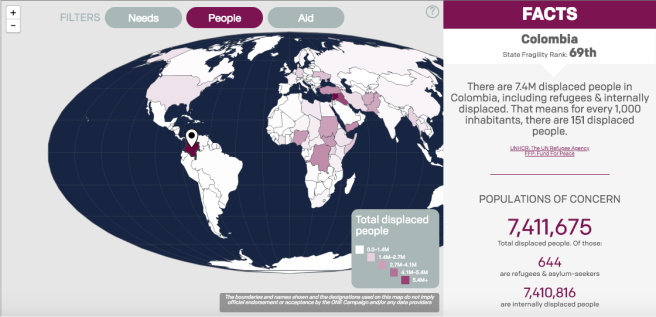
El flujo de refugiados en el mundo
De forma muy visual este mapa muestra las grandes migraciones de personas de los últimos 15 años, las que han trascendido en los medios de comunicación y las que no han sido mediáticas como los éxodos en Sri Lanka en 2006 o en Colombia en 2007.
Cada punto amarillo representa a 17 personas refugiadas que abandonan un país, y cada punto rojo representa a los refugiados que llegan a otro lugar.

![]()
MediaCloud es una plataforma open source que registra el discurso mediático sistematizando el contenido noticioso de más de 25 mil fuentes digitales de más de 200 países, en múltiples idiomas. Esto, con la intención de potenciar el análisis que se hace sobre la atención que un tema particular tiene en la agenda mediática.
Por sus funciones, es una herramienta muy útil para periodistas, activistas, académicos, investigadores, creadores de contenido y organizaciones sociales. MediaCloud tiene tres herramientas principales: Explorer, TopicMapper y SourceManager. En este tutorial te enseñamos cómo empezar a usar Explorer.
Explorer es una herramienta que te permite buscar en la base de datos de MediaCloud, visualizar los resultados de esa búsqueda y descargar un archivo .CSV con las urls de las historias que coinciden con tu búsqueda. Con este buscador, obtendrás rápidamente un panorama general sobre cómo un tema de tu interés es cubierto por los medios digitales analizando la atención, el lenguaje y la representación del tema.
Explorer es un buscador en el cual puedes agregar las consultas o querys que desees y que además puedes ajustar al elegir fuentes de noticias específicas o una colección de fuentes y un rango de fechas. Explorer te permitirá identificar las fuentes e historias que lideran la conversación mediática sobre este tema, el lenguaje utilizado para hablar de él y las personas y lugares que mencionan.
Cómo buscar.
Luego de registrarte en MediaCloud entra a https://explorer.mediacloud.org y usa la caja de búsqueda para conocer sobre el tema de tu interés.
Al hacer una búsqueda, se desplegarán las siguientes opciones que te permitirán refinarla:
Enter a query
Haz una consulta. Escribe los temas, personajes o palabras clave que te interesa ver en los medios. Puedes usar operadores boléanos y otros parámetros de búsqueda avanzada que te describen aquí.
Select media
Selecciona los medios o las colecciones de fuentes de noticia que quieres buscar. MediaCloud cuenta con colecciones creadas previamente que puedes utilizar. Solo haz click en + Add media y busca entre las colecciones por zona geográfica, por alcance de la cobertura o busca medios específicos que quieres añadir a tu recolección de historias.
For dates
Escoge un período de tiempo entre dos fechas que filtre las historias que aparecerán en tu búsqueda.
Los resultados de tu búsqueda
En el panorama temático que Explorer presenta, ofrece diferentes visualizaciones y análisis sobre las historias que coinciden con tu búsqueda. Estos se concentran en trés áreas principales: Atención, Lenguaje, y Personas y Lugares. Cada una de estas funciones te permite descargar los resultados al hacer click en el botón Download Options y en algunas secciones te permitirá también descargar los resultados como imagen o gráfico.
ATENCIÓN:
Attention Over Time
A través de una gráfica de líneas, Explorer te muestra la atención que los medios le prestaron a los temas de tu consulta para que entiendas cómo fueron cubiertos a lo largo del tiempo. Las alzas en el gráfico pueden evidenciar un evento clave o una historia popular. Puedes elegir entre ver un conteo de historias o un porcentaje que normaliza los resultados.
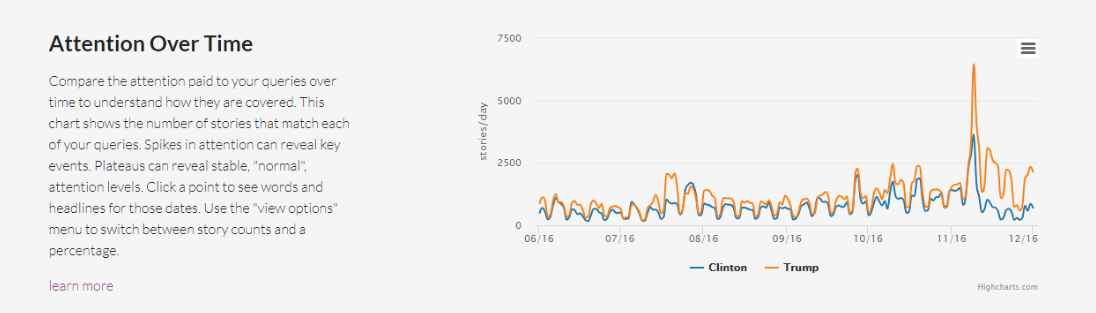
Total Attention
En esta sección, se compara el número total de historias que coinciden con tu búsqueda. Es muy útil cuando tu búsqueda incluye más de un query o consulta. O puedes añadir una nueva consulta escribiendo un asterisco * en los mismos rangos de fechas y con las mismas fuentes, para hacer obtener todos los resultados de historias independientemente de tu tema.

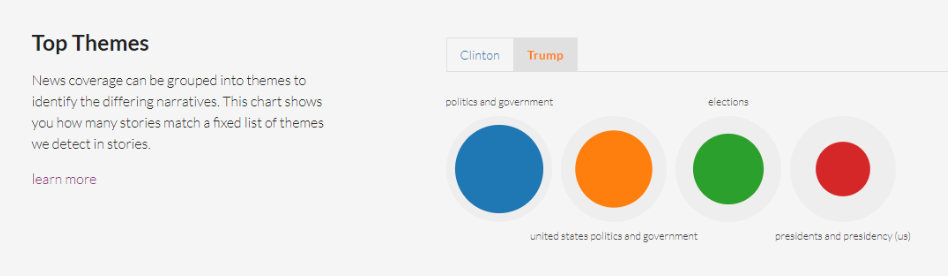
Top Themes
La cobertura noticiosa se clasifica en temas para identificar narrativas diferentes. A partir de una lista fija de temas noticiosos detectados, distribuye las historias que coinciden con tu búsqueda entre ellas. Te muestra un gráfico en el que cada coincidencia es un círculo de color, rodeado por un círculo gris que representa a todas las historias de tu búsqueda, para que sepas qué tantas de las historias están dentro de este tema. Esta clasificación se realiza a partir de un modelo construido tomando en cuenta una indexación anotada del New York Times que resultó en esta lista de 600 temas.
Sample Stories
Esta es una muestra aleatoria de historias sobre tu tema. Al menos una oración de esta historia coincide con tu búsqueda. Puedes ver algunas o descargar un CSV con las historias y sus URLs.

LENGUAJE:
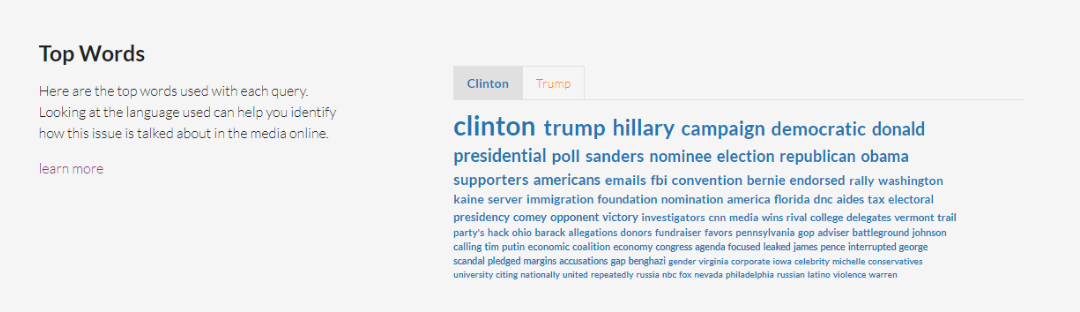
Top Words
Te muestra las palabras más utilizadas con cada búsqueda. Este panorama de palabras puede ayudarte a identificar de qué manera se aborda este tema en los medios digitales. La nube de palabras se muestra de manera ordenada: aquellas que más aparecen tendrán un mayor tamaño y estarán primero en la lista. Se basa en una muestra representativa de las historias, pero no en todos los resultados de la búsqueda. El conteo de palabras completo se puede descargar como CSV y también una versión de bigramas (frases de dos palabras) o trigramas (frases de tres palabras) que más se usan en las historias. Cuenta las palabras en base a su raíz.
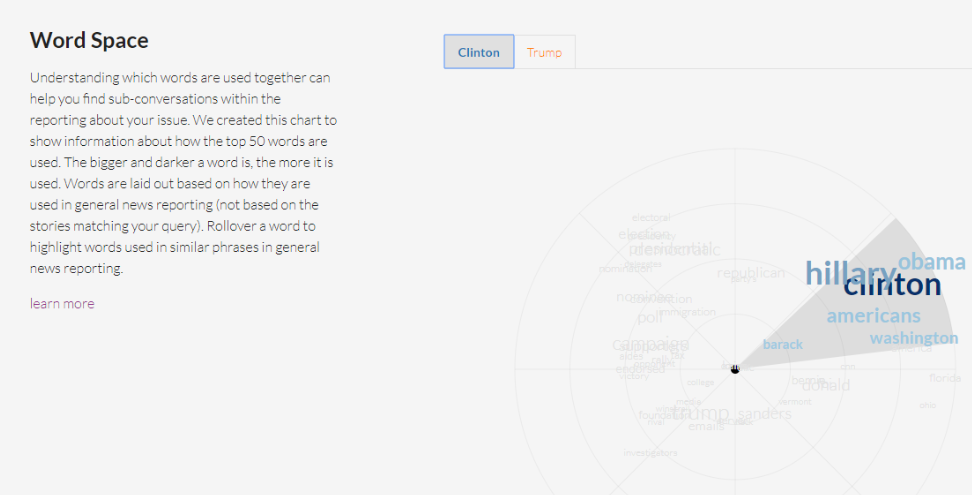
Word Space
Para entender qué palabras se usan junto a otras, esta función te muestra una gráfica con las 50 palabras más usadas en el tema. Mientras más grande y oscura sea, más aparece en las historias de los medios. Las palabras se distribuyen en un radio según qué tan similar aparecen juntas en el reporteo general de noticias. Al mover el cursor por el radio verás cómo se resaltan palabras que son frecuentemente usadas juntas. La distribución se basa en el modelo de machine learning word2vec y un proyecto de Google News.
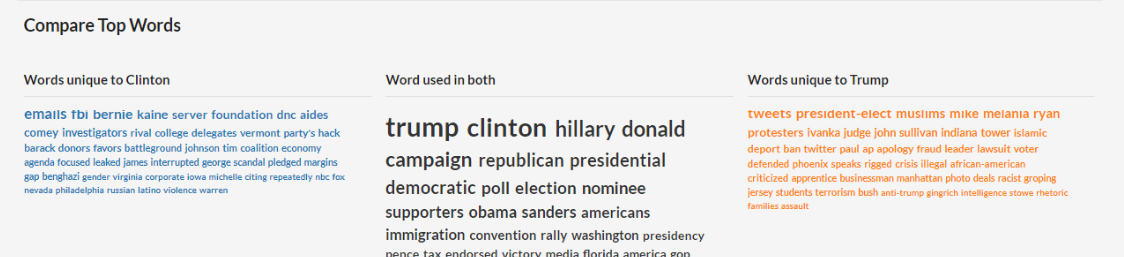
Compare Top Words
Esta sección compara las palabras más utilizadas en cada una de tus consultas y las ordena de mayor a menor, para enfatizar en la diferencia de lenguaje utilizado en las historias recopiladas por MediaCloud para cada consulta.
PERSONAS Y LUGARES:
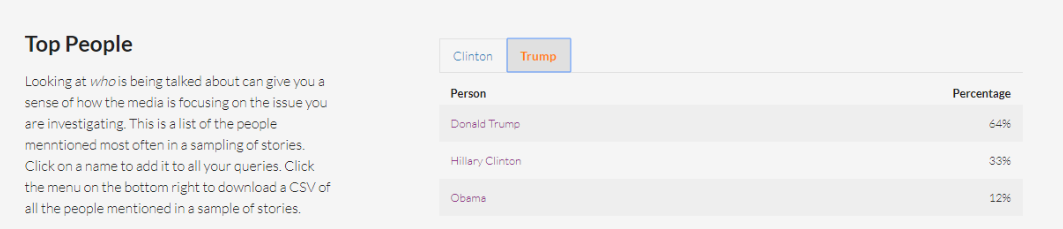
Top People
Ver a quienes mencionan en las historias puede darte una idea de cómo los medios cubren el tema de tu interés. En esta lista MediaCloud te presenta los personajes que más aparecen en una muestra de historias. Al hacer click en un nombre, lo puedes añadir a tu consulta o búsqueda. Esto se logra utilizado el Reconocedor de Entidades Nombradas de Stanford. Cada historia es etiquetada con las personas, organizaciones, países y estados que menciona.
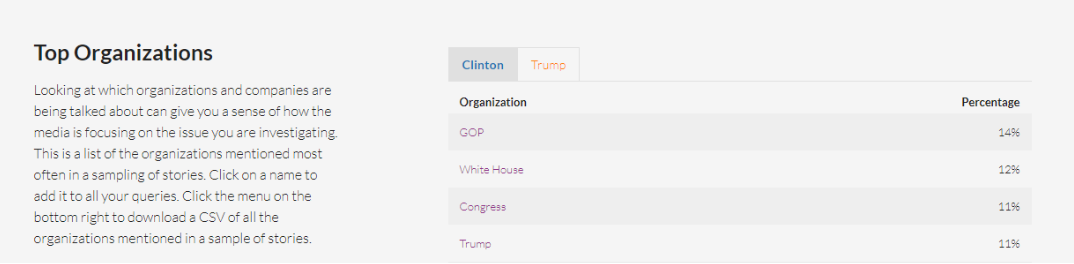
Top Organizations
Esta sección funciona igual que la anterior, pero con nombres de organizaciones, empresas e instituciones.
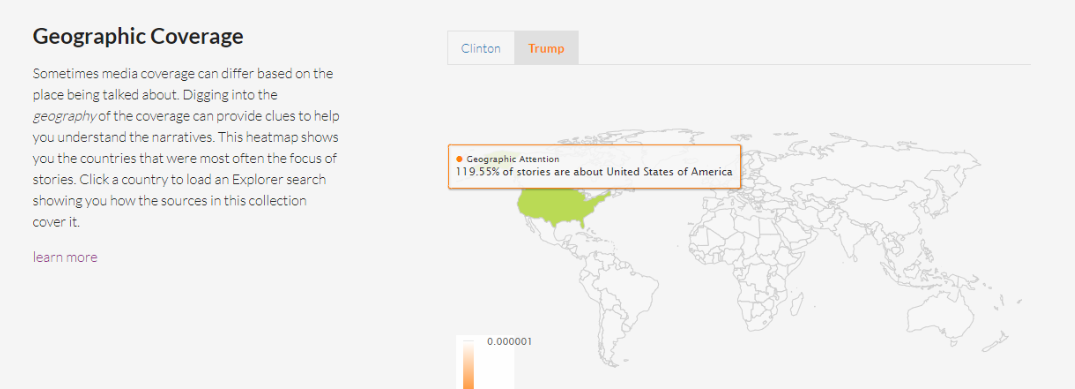
Geographic Coverage
La cobertura de un tema puede variar en función del lugar del que se habla. Al revisar la geografía a través de un mapa puedes comparar los países que fueron el centro de las historias. Los lugares con un color más intenso fueron repetidamente el foco de las historias.
Con este panorama amplio, Explorer facilita sacar algunas conclusiones y preparar gráficos que dan insights sobre cómo se aborda un tema en los medios digitales.
Cómo se creó está herramienta
MediaCloud es un proyecto creado por los equipos del Centro para Medios Cívicos del MIT y el Centro Berkman Klein para el Internet y la Sociedad de la Universidad de Harvard. Para lograr la capacidad de análisis y de rastreo de datos esta herramienta colecciona los hipervínculos y otro tipo de enlaces: Bitly, Facebook y Twitter, por ejemplo. La gran mayoría del contenido proviene de los canales RSS de cada organización mediática. Los datos de cada fuente varían, dependiendo del momento en que MediaCloud comenzó a hacer el scrapping o raspado de datos. Debido a restricciones de derechos de autor, la herramienta no puede proveer los textos de las historias, pero presenta la lista de URLs para que el usuario pueda obtenerlo por su cuenta.
![]()

Con este programa buscamos aumentar la conciencia sobre el uso de datos en el sector público y construir comunidades que trabajando juntas usen sus habilidades para la alfabetización de datos. La fellowship EstadoAbierto te permite organizar talleres, eventos de comunidad y contenidos educativos, además de generar proyectos de mayor alcance con organizaciones aliadas.
En su primera edición, esta Fellowship tiene dos enfoques temáticos. Las Contrataciones Abiertas, una oportunidad para la rendición de cuentas y la transparencia, y el Cambio Climático y los indicadores sobre el estado del medio ambiente. El rol de las personas elegidas consiste en avanzar la liberación de datos y dinamizar su uso en estos dos temas, así como asistir en la formación de comunidad para promover estos datos.
Esta fellowship busca fortalecer el trabajo indicado en los compromisos 3 y 6 del III Plan de Acción de Gobierno Abierto de Costa Rica ante la Alianza para el Gobierno Abierto y la Política Nacional de Apertura de Datos Públicos. Las personas elegidas trabajarán junto con el Ministerio de Ambiente y Energía y el Ministerio de Hacienda.
Una nueva modalidad de fellowship
Para enfocar el entrenamiento y experiencia de aprendizaje, la Fellowship EstadoAbierto priorizará la selección de postulantes que:
- Cuenten con experiencia profesional o proyectos personales en relación a la transparencia en el uso de recursos públicos o el uso de datos sobre el medio ambiente.
- Tengan habilidades técnicas para el manejo de base de datos de diverso tipo y herramientas de visualización de datos.
- Sean capaces de gestionar proyectos vinculados a tecnología
- Muestren entusiasmo por el entrenamiento y la formación de capacidades. Ser fellow conlleva realizar talleres, mentorías y asesoría necesarias para formar en uso y manejo de datos.
- Conozcan a su comunidad local de organizaciones que trabajan en temas relacionados con transparencia, fiscalización, uso de datos, cambio climático, medio ambiente y desarrollo sostenible. Que demuestren tener vínculos con quienes abordan esta temática de manera directa
- Disponibilidad para participar en llamadas, reuniones y conferencias, como Abrelatam/ConDatos en Septiembre 2018.
Estamos buscando a individuos involucrados que ya cuentan con conocimiento profundo de un sector o tema, y que activamente han influenciado el uso de los datos en estas temáticas. Este enfoque permitirá a las y los Fellows iniciar rápidamente actividades y alcanzar lo máximo durante su participación en la Fellowship EstadoAbierto: ¡cinco meses pasan muy rápido!
Pueden aplicar todas las personas que vivan en Costa Rica y puedan ser contratadas para trabajar. Las sedes de trabajo se encuentran en San José. El Comité de selección lo integrarán un representante de ILDA, un representante de la Escuela de Datos y un representante del Gobierno de Costa Rica.
El programa durará 5 meses y los becarios recibirán la suma de 568.000 colones (en bruto) mensual. Como parte del programa, participarán presencialmente en la Conferencia Internacional de Datos Abiertos a llevarse a cabo en el mes de setiembre Buenos Aires en donde conocerán a otros miembros de la comunidad y compartirán conocimientos. Este programa apoyado por el fondo de transparencia Banco Interamericano de Desarrollo (BID) y la colaboración de la Fundación Avina.
Postula aquí completando el formulario hasta el 10 de Junio. Si tienes alguna duda, por favor contactar con Javiera en la dirección [email protected]
![]()

Mientras las visualizaciones de datos se vuelven más populares y se van creando nuevas herramientas para crearlas, menos personas están pensando de manera crítica acerca de la política y la ética de las dinámicas de representación. Esto, combinado a un público general asustado por los datos y las gráficas, conlleva que las visualizaciones de datos ejerzan una gran cantidad de poder retórico. A pesar de que de manera racional sabemos que las visualizaciones de datos no representan “el universo completo”, nos olvidamos de ello y aceptamos cualquier gráfico como un hecho porque es generalizado, científico y parece presentar un punto de vista experto y neutral.
¿Cuál es el problema de esto? La teoría feminista nos diría que el problema es que todo conocimiento es situado socialmente, y que las perspectivas de los grupos oprimidos, incluyendo a las mujeres, a las minorías y a otros grupos son excluidas sistemáticamente del conocimiento “general”.
La corriente de la cartografía crítica nos diría que los mapas son espacios de poder y que producen mundos que están íntimamente ligados a ese poder. Como Denis Wood y John Krygier explican, la elección sobre qué poner en un mapa “…trae a la superficie el problema del conocimiento, de una manera ineludible así como pasa con el simbolismo, la generalización y la clasificación”. Hasta que reconozcamos ese poder de inclusión y exclusión, y desarrollemos un lenguaje visual para ello, debemos reconocer que la visualización de datos puede ser otra herramienta poderosa y defectuosa para la opresión.
¿Puedo decir esto más claro? Donna Haraway —en su influyente ensayo sobre Conocimientos situados— ofrece una brillante crítica no sólo a la representación visual, sino al privilegio extremo y perverso de los ojos sobre los cuerpos que han dominado el pensamiento occidental. Es evidente al leer esta cita en voz alta, que funciona también como una pieza de performance:
Los ojos han sido utilizados para significar una perversa capacidad, refinada hasta la perfección en la historia de la ciencia —relacionada con el militarismo, el capitalismo, el colonialismo y la supremacía masculina— para distanciar al sujeto conocedor de todos y de todo, en interés del poder sin trabas. Los instrumentos de visualización… han compuesto estos significados de descorporalización. Las tecnologías de visualización parecen no tener límites… La vista en esta fiesta tecnológica se ha convertido en glotonería incontenible. .. Y como truco divino, este ojo viola al mundo para egendrar monstruos tecnológicos.
— Donna Haraway en “Conocimientos situados: La cuestión científica en el feminismo y el privilegio de la perspectiva parcial” (1995)
Ver el mundo por completo es una fantasía que Michel DeCerteau llama “el ojo totalizante” y a la que Donna Haraway llamó “el truco divino”. ¿Acaso no es ésta la premisa retórica y promesa seductora de la visualización de datos? ¿Ver desde la perspectiva de ninguna persona o cuerpo? Nuestro apetito por dichas perspectivas es feroz y glotón, como dice Haraway.
Existen maneras de representar el mundo de una manera más responsable. Existen maneras de “situar” la visualización de datos y localizarla en cuerpos y geografías concretas. Los cartógrafos críticos, los indígenas mapeadores y otras comunidades han experimentado por años con estos métodos y podemos aprender de ellos.
Tip 1 Inventa formas de representar los datos faltantes, la incertidumbre y los métodos que fallan.
Mientras que las visualizaciones —sobre todo las populares y públicas— son una gran manera de presentar mundos completamente contenidos, no son tan buenas para presentar sus limitaciones.¿Cuáles son los lugares que la visualización no incluye o a los que no pudo llegar? ¿Podemos incluirlos en la visualización? ¿Cómo presentamos los datos que nos hacen falta? Andy Kirk tiene una muy buena charla sobre el diseño de la nada, en la cual explica cómo los diseñadores toman decisiones a la hora de representar la incertidumbre, incluir valores ceros, nulos y en blanco. ¿Podemos empujar a qué más diseñadores tomen estos métodos en consideración? ¿Podemos pedir que nuestros conjuntos de datos señalen también aquello que dejaron fuera?
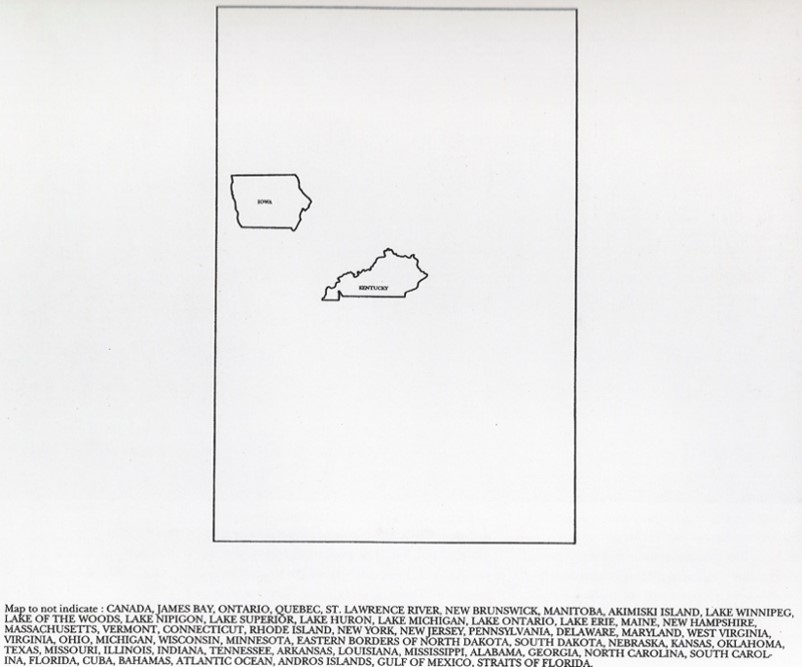
Mapa para no indicar, 1967 por el colectivo de artistas Art&Language. El mapa enseña solo a Iowa y Kentucky y luego procede a listar todo aquello que no está representado en él. Forma parte de la Tate Collection.
Más allá de escribir “datos no disponibles”, ¿Cómo profundizamos en la procedencia de los datos como un nuevo campo de la visualización, similar al trabajo de verificación de datos? ¿Podemos recolectar y representar los datos que no se han recopilado antes? ¿Podemos encontrar a la población que fue excluida de la recolección de datos? ¿Podemos localizar las fallas en el instrumento de recolección de datos que todos asumían que funcionaba a la perfección? ¿Podemos examinar críticamente los métodos de un estudio en lugar de aceptar que el CSV, JSON ola API están como están y ya? Todas estas parecen tareas que van más allá del trabajo del visualizador de datos. Alguien más antes de ellos en el proceso de datos, el DataPipeline, debería hacer ese trabajo de investigación nada sexy de la antropología de datos. Pero si los visualizadores no asumen esta responsabilidad ¿Quién la asume?
Tip 2 Haz referencia a la ‘economía de los materiales’ detrás de los datos
Aparte de la procedencia de los datos, también necesitamos preguntar sobre la economía de los materiales detrás de este proceso de recolección de datos ¿Cuáles eran las condiciones que hicieron una visualización de datos posible? ¿Quién pagó por esta visualización? ¿Quién recolectó los datos? ¿Cuál es el trabajo detrás de escenas y bajo qué condiciones se produjo esta visualización?
Por ejemplo, en el Laboratorio Público de Tecnología y Ciencia Abierta tenemos esta técnica de mapeo en la que cuelgas una cámara a un barrilete o globo para obtener imágenes espaciales. Uno de los efectos secundarios de este método que algunas comunidades han adoptado es que la cámara también captura la imagen de las personas que participan en el mapeo. Estos son los cuerpos de los recolectores de datos, frecuentemente ausentes de las representaciones finales.

Foto tomada de un artículo de Eymund Diegal del Laboratorio Público sobre mapeo de aguas residuales en el Canal Gowanus. Noten a las personas en botes haciendo el mapeo y el cordón del globo que une la cámara y la imagen de regreso a quienes recolectan los datos.
Comúnmente, las visualizaciones de datos citan a las fuentes en una pequeña leyenda, pero se podría hacer más. ¿Qué tal si problematizamos visualmente la procedencia de los datos? ¿Los intereses detrás de la producción de un conjunto de datos particular? ¿Los tomadores de decisiones de estos datos? Un archivo CSV usualmente no tiene referencia a ninguno de estos elementos materiales más humanos que también son esenciales para que entendamos el dónde, por qué y cómo de los datos.
Tal vez una manera de resolver este problema sería tener metadatos mucho más robustos y de manera intencional priorizar el despliegue visual de esos metadatos. La meta de dicha visualización sería mostrar no sólo lo que los datos “dicen” sino cómo los datos se conectan con personas, sistemas y estructuras de poder y producción en el mundo más amplio.
Tip 3 Haz que la disidencia sea posible
A pesar de que hay suficientes visualizaciones de datos “interactivas”, lo que en realidad significa interactividad es la capacidad de seleccionar algunos filtros y mover algunas barras o sliders para ver cómo la imagen se adapta y cambia. Estos pueden ser métodos poderosos para moverse dentro de un mundo contenido y restringido de imágenes y hechos estables. Pero como sabemos por ejemplos como las guerras de edición en Wikipedia, o las controversias de GoogleMaps, el mundo no está encuadrado de una manera tan conveniente en la que los “hechos” no se disputan o son siempre lo que parecen ser.
Una manera de resituar la visualización de datos es desestabilizarla al hacer posible el disenso. ¿Como podemos idear formas en las que una audiencia pueda “responderle”a los datos?… ¿Para cuestionar los hechos que presenta? ¿Para presentar visiones y realidades alternativas? ¿Para combatir y socavar principios básicos de la existencia y recolección de esos datos?
¿Cómo hacer esto? A pesar de que la mayoría de personas que trabajan con datos son hombres blancos, podría ser tan simple como incluir a personas de diferentes contextos, con diferentes perspectivas, en la producción de la visualización. Por ejemplo, el Insituto de Expediciones Geográficas de Detroit era un proyecto realizado en conjunto entre geógrafos académicos (liderados por hombres blancos privilegiados) y la juventud de diferentes sectores de la ciudad (liderados por Gwendolyn Warren, un activista negro de 19 años) a finales de 1960.

Tomado de Notas de Campo III: Geografía de los niños de Detroit. por el Instrituto de Expediciones Geográficas, 1971. Warren y sus colegas usaban este mapa y los reportes generales para argumentar a favor de un programa de “planificación de negros”, que empoderaba a los ciudadanos de color para tomar decisiones sobre sus comunidades.
Para su tiempo, este mapa era avanzado tecnológicamente y un poco convencional (a nuestros ojos) en su uso de estrategias visuales. Lo que le da a este mapa disidencia es el titulo, formulado por la juventud negra haciendo el mapeo: “Donde los automovilistas atropellan a niños negros”; este no es un título neutral. El mapa pudo haberse llamado “Donde pasan los accidentes en el centro de Detroit” (y de esta manera, habría sido si la ciudad hubiera contratado a un consultor en cartografía para mapear esos mismos datos), pero desde el punto de vista de las familias negras cuyos hijos habían sido atropellados, era significativo que los niños eran negros, los automovilistas en su mayoría blancos y que los eventos se describían como “muertes” en vez de “accidentes”.
Uno puede construir disenso en el proceso de visualizar si incluye voces diversas en la creación, pero ¿Y en el producto final?
El proyecto ToxicSites.us crea un reporte sobre cada lugar contaminado en Estados Unidos e invita a que diferentes colaboradores añadan historias locales, imágenes y videos que documentan el sitio (y posiblemente contradigan los datos oficiales). El sitio también permite que campañas de activismo y programas ecológicos se organicen para limpiar estos lugares. Esta es una manera de “responder” a los datos, así como de pasar la conversación pública sobre lo que los datos dicen a la acción.
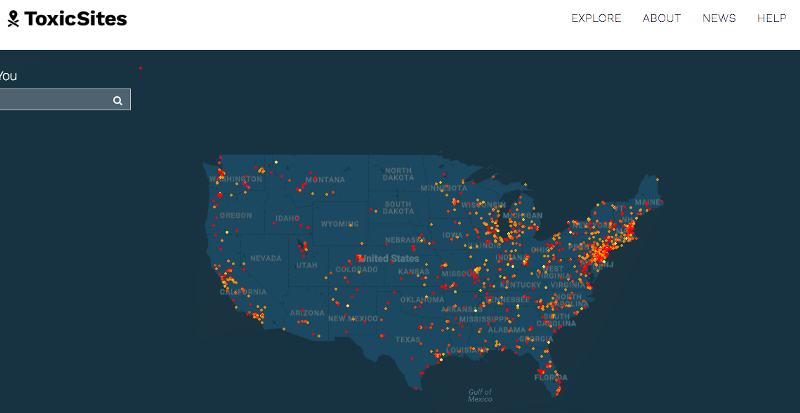
El sitio ToxicSites.us presenta mapas, visualizaciones de datos e historias sobre los proyectos del programa Superfund, responsable por limpiar los lugares más contaminados de Estados Unidos. El proyecto busca responder a emergencias ambientales, fugas de petróleo y desastres naturales.
Una visualización a menudo se produce con un enfoque desde arriba: un diseñador experto o un equipo con conocimientos especializados encuentra algunos datos, hace algo de su magia y presenta al mundo un artefacto con algunas maneras altamente recomendadas para verlo.
¿Podemos imaginar una forma alternativa de incluir más voces en la conversación? ¿Podríamos realizar la visualización de forma colectiva, inclusiva, con disidencia y contestación, a escala?
¿Qué más?
Estas son solo tres sugerencias de diseño que apuntan hacia la ética feminista y la conciencia sobre las políticas detrás de la visualización de datos. Me gustaría escuchar sobre otros aspectos de la visualización de datos que podamos repensar para hacerla más situada, más feminista, y sobretodo, más responsable. Haz tus comentarios o escríbeme en Twitter a @kanarinka para continuar la conversación.

![]()
¿Te has encontrado con bases de datos que tienen pequeños errores de transcripción? ¿Espacios de más, uso desordenado de mayúsculas y minúsculas, o registros que representan al mismo dato pero que fueron escritos con pequeñas diferencias? Con la herramienta OpenRefine puedes automatizar mucho del doloroso proceso de limpiar una base de datos. En este tutorial te enseñaremos una de sus funciones más útiles: la clusterización —o generación de agrupaciones automáticas— y los diferentes algoritmos que determinan las coincidencias entre registros.
El concepto de clusters (o agrupaciones, en español) se utiliza mucho en ciencias sociales y exactas para referirse a un tipo de análisis que toma un conjunto de datos y las reorganiza en grupos con características similares.
En OpenRefine, cuando uno hace clusters significa que el programa está encontrando grupos de valores diferentes que pueden ser representaciones alternativas del mismo valor. Por ejemplo, si hablamos de ciudades, “New York”, “new york” y “Nueva York” son tres valores diferentes pero que se refieren al mismo concepto, sólo con cambios de idioma y de uso de mayúsculas y minúsculas.
Vale la pena mencionar que las agrupaciones en OpenRefine sólo se generan automáticamente en la sintaxis (o sea, el orden y la composición de caracteres que tiene como valor una celda) y aunque estos métodos son útiles para encontrar errores e inconsistencias, no son lo suficientemente avanzados para determinar agrupaciones a nivel semántico (o sea, el significado de un valor).
Estos métodos se pueden aplicar determinando cuántos grados de cercanía -en otras palabras, qué tan estrechas o flojas quieres encontrar las coincidencias-. Al graduar la cercanía encuentras coincidencias más o menos exactas. Por eso es importante que si bien, los algoritmos ayudan a automatizar la tarea de limpieza, un ojo y cerebro humano va administrando qué tan agresivas deben ser estas uniones para encontrar coincidencias, para evitar que asocie datos que no deberían ir juntos.
Conozcamos los algoritmos: En qué consisten estas metodologías
Existen dos grandes metodologías para hacer clusters: la colisión clave y el vecino más cercano. Open Refine utiliza diferentes variantes de estos dos métodos. Aquí te explicamos cuál es el proceso detrás de cada uno.
Sección 1: Métodos de colisión clave
Estos se basan en la idea de crear una representación alternativa de un valor inicial, el cual se convierte en una clave. Una clave contiene las partes más distintivas y significativas de un valor. OpenRefine va buscando en los demás registros qué otros valores se parecen a esta clave para agruparlos. El procesamiento requerido para este método no es muy complejo, por lo que presenta resultados muy rápidos. Este método tiene varias funciones diferentes que se pueden administrar en OpenRefine.
- Fingerprint
Un método fácil y simple. Quita todos los espacios en blanco, cambia todos los caracteres a minúsculas, remueve toda la puntuación y normaliza cualquier caracter especial a una versión estándar. Luego, parte el texto y aplica espacios en blanco. Así encuentra las coincidencias.
- N-Gram Fingerprint
Es similar al anterior, pero en vez de separar los caracteres por espacios en blanco, usa una cantidad a la enésima (n) potencia de espacios que el usuario puede determinar.
- Fingerprint Fonético
Este método no revisa los caracteres textuales sino su pronunciación y fonética: la manera en que esa palabra se pronunciaría, en vez de revisar similitudes en la escritura. Es muy útil para limpiar datos con nombres particulares, ya sea de lugares y personas. En ocasiones, los errores de registro se deben a que se registran a partir de la pronunciación. Sirve para encontrar similitudes entre sonidos parecidos pero que se escriben muy distinto como el sonido de “sh” y “x”, que en ocasiones son similares.
Sección 2: Vecino más cercano (Nearest neighbor)
Estos métodos proveen un parámetro o radio de aproximación alrededor de un valor o palabra, y va encontrando los grados de similitud entre éste y otros registros. Debido a los cálculos necesarios, estos métodos son más tardados en procesar.
- Distancia Levenshtein
Este método se basa en el trabajo y proceso que implicaría cambiar a un registro A para que sea igual a un registro B. La distancia Levenshtein mide cuántas operaciones de edición -o cuántos pasos- le tomaría a alguien hacer que un dato se parezca al otro. Encuentra coincidencias entre los datos que están separados por la menor cantidad de pasos o cambios.
Por ejemplo, “Paris” y “paris” tienen una distancia de edición de 1, ya que solo se debe cambiar la P mayúscula a una minúscula. Sin embargo, “Nueva York” y “nuevayork” tienen una distancia de 3 pasos: dos sustituciones y un borrón.
- PPM (Prediction by Partial Matching)
Este método se utiliza para encontrar coincidencias en secuencias de ADN. Estima la similitud entre textos y determina su contenido idéntico. Por ejemplo, con el ADN encuentra similitud entre dos muestras para indicar un grado de familiaridad. Es común en este campo que no se busque una coincidencia exacta (que implicaría trabajar con muestras de ADN de la misma persona) sino encontrar un alto grado de coincidencia y familiaridad.
Si dos cadenas A y B son idénticas, al concatenar A+B debería de producirse muy poca diferencia. Pero si A y B son diferentes, al concatenar A+B se deberían producir diferencias muy dramáticas en la longitud de la cadena.
Paso a paso. Aplicando los clusters en OpenRefine
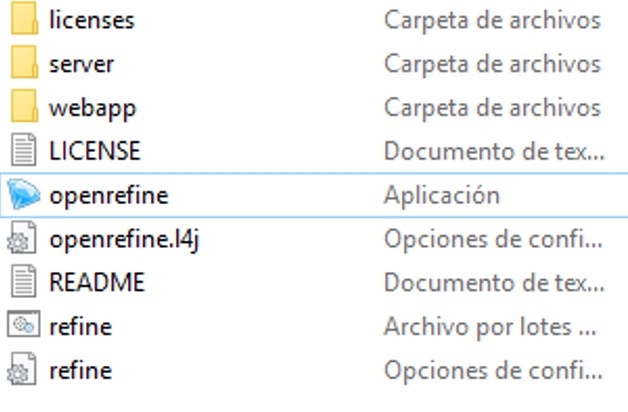 OpenRefine es un programa que corre a través de tu browser o navegador de internet. Para instalarlo, es necesario que lo descargues en este link y sigas las instrucciones para tu equipo. Usualmente, solo requiere que descargues la carpeta, la descomprimas y abras la aplicación.
OpenRefine es un programa que corre a través de tu browser o navegador de internet. Para instalarlo, es necesario que lo descargues en este link y sigas las instrucciones para tu equipo. Usualmente, solo requiere que descargues la carpeta, la descomprimas y abras la aplicación.
OpenRefine debería abrir una ventana negra con algunos códigos y abrirse automáticamente en tu navegador de internet. Si no funciona, prueba ir a la dirección http://127.0.0.1:3333/
Vamos a hacer un ejemplo con un conjunto de datos sobre financistas a las elecciones del 2017-2018 en Estados Unidos que puedes descargar aquí.
Para subir el archivo, solo sigue los siguientes pasos:
Create project > Elegir archivo (selecciona el archivo ZIP que descargaste) > Next
OpenRefine te mostrará una previsualización de tu conjunto de datos. En este caso, deberás desmarcar la opción >Parse Next para indicar que tu base de datos no tiene títulos de columna en la primera fila.
En >Project Name, escribe “Financiamiento político_Estados Unidos 2017-2018” y da click a >Create project para guardar este proyecto.
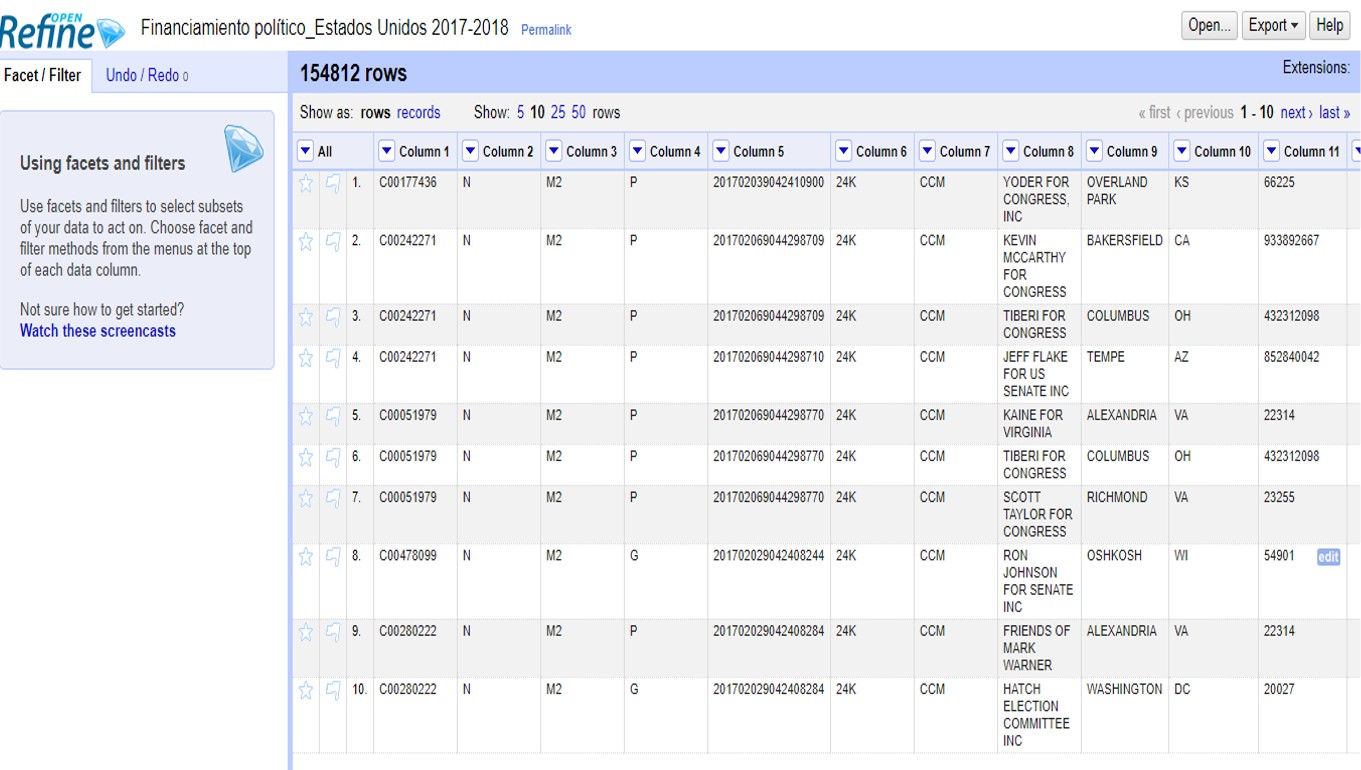
En la columna 8 encontrarás el listado de financistas. Haciendo click en el triángulo a la par del título de esta columna, selecciona >Facet >Text facet para generar un filtro de texto.
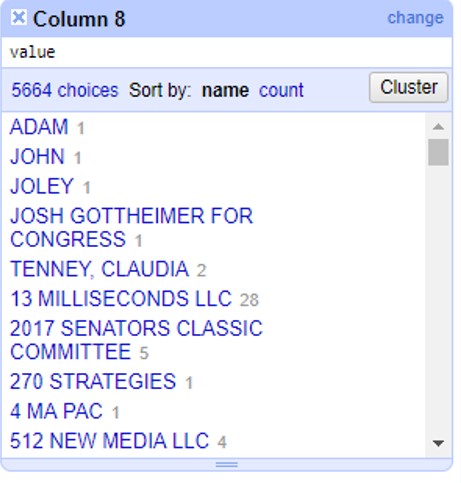
A un lado, te aparecerán todos los registros de financistas en orden alfabético, con un número a la par que indica cuántas veces aparece este nombre en la base de datos. Haz click en el botón >Cluster para empezar a generar agrupaciones automáticas.
En la siguiente ventana puedes aplicar todos los métodos de clusters que te enseñamos. Puedes administrarlo cambiando las opciones >Method, >Keying Function o >Distance Function.
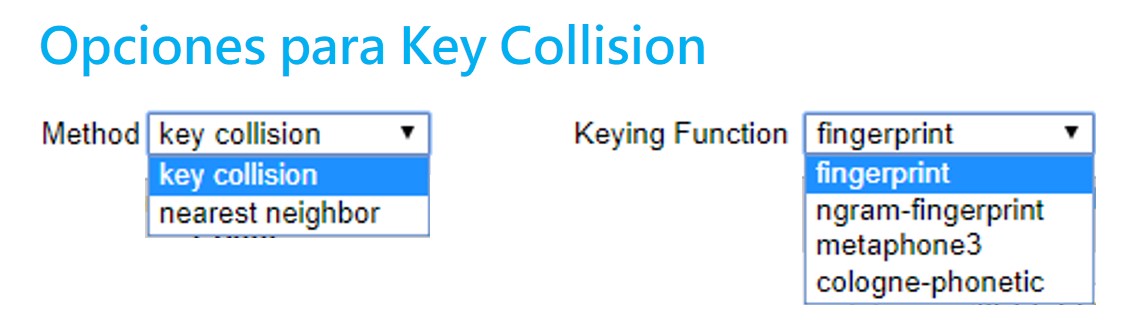

Con estos controles podrás ir determinando qué tan agresivos son tus clusters. Independientemente del método que eligas, el proceso es el mismo. Al seleccionar el método y sus opciones, OpenRefine comenzará a procesar los datos para encontrar coincidencias y armarlas en un cluster o agrupación.
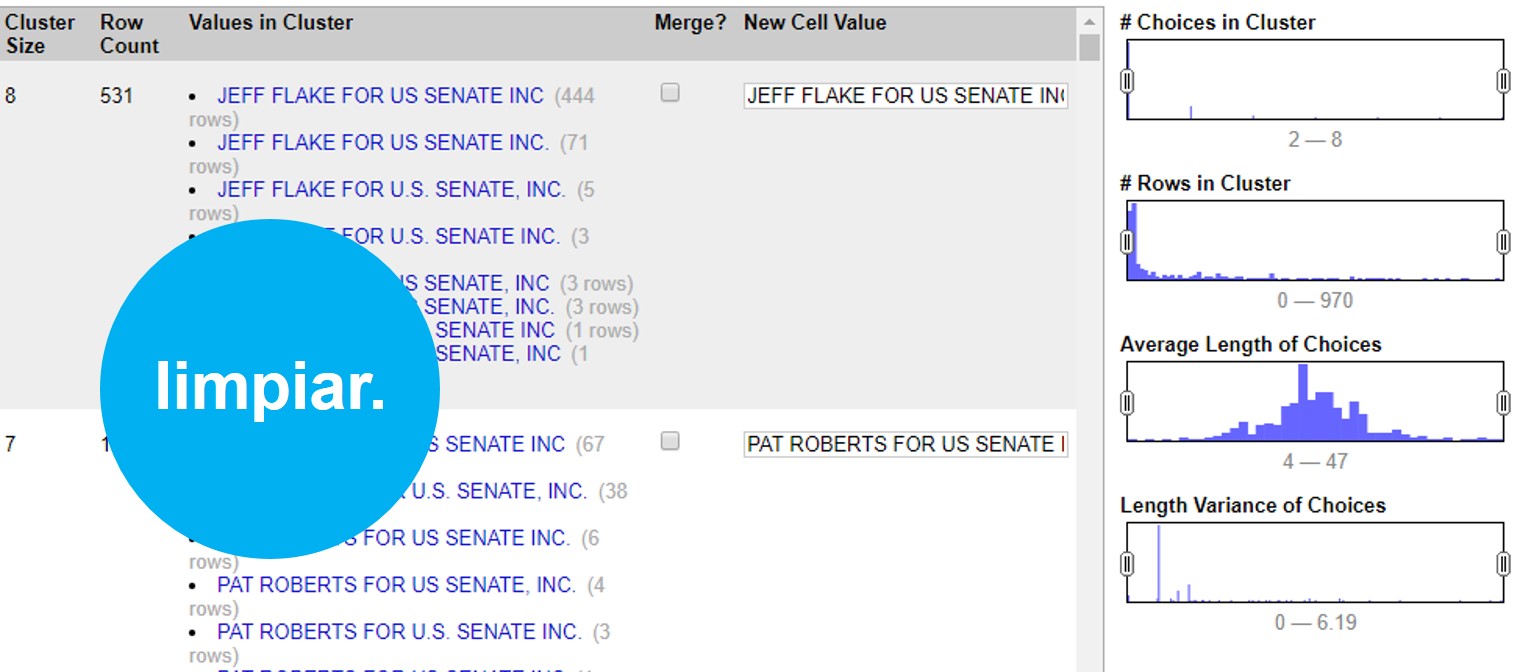
En este ejemplo podemos ver que el programa encontró 531 valores muy similares, escritos de 8 maneras diferentes para decir lo mismo: que un financista se llama “JEFF FLAKE FOR U.S SENATE, INC”. Como puedes ver, a la par de cada manera de escribir, OpenRefine te muestra cuántas veces aparece de esta manera el valor.
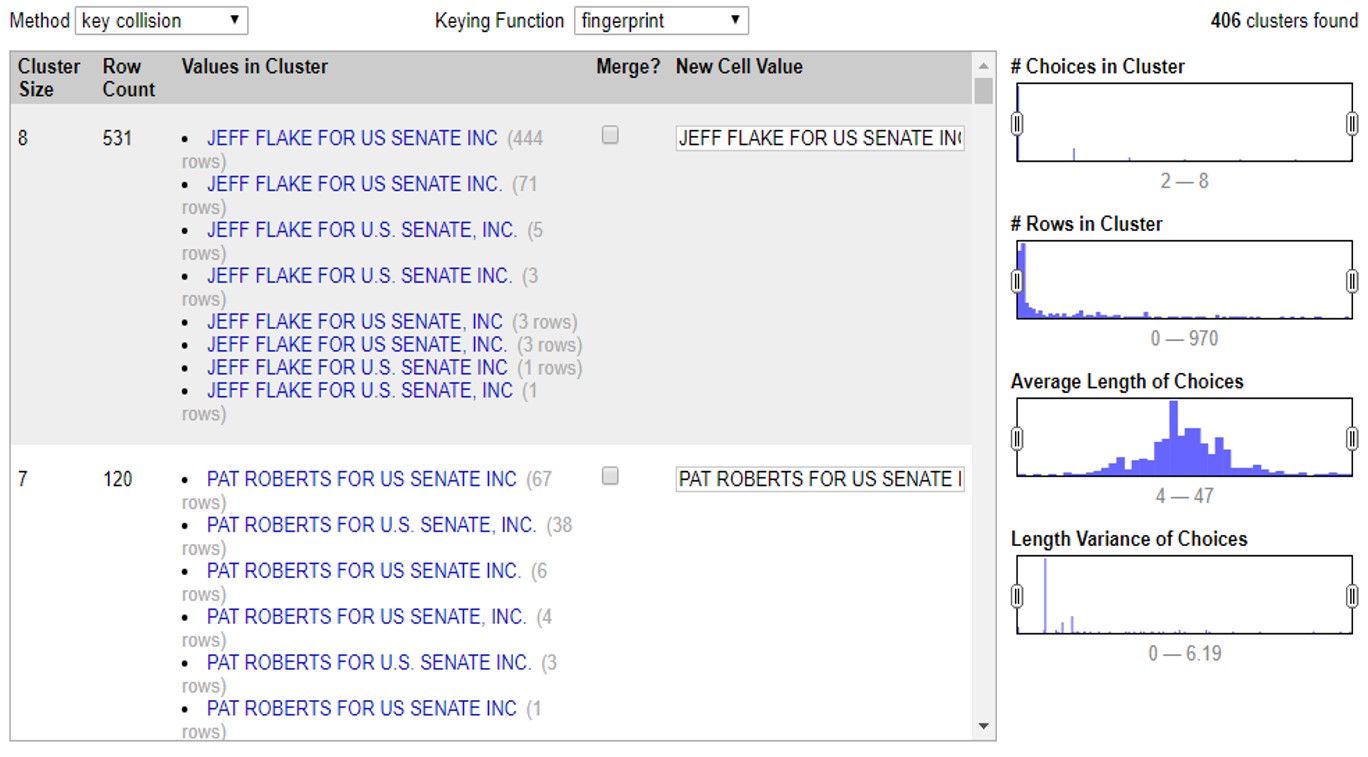
En este caso te muestra dos opciones. La primera, >Merge incluye una casilla que puedes seleccionar en caso de que sí quieras que OpenRefine una estos valores. En la segunda opción >New Cell Value, el programa te da la oportunidad de que edites y decidas de qué manera quieres que se reescriba este cluster. Así, irás administrando la agrupación valor por valor, decidiendo si quieres o no agrupar los valores con >Merge y la opción de escritura bajo la cual estos valores se agruparán con >New Cell Value
Con este ejemplo, si aceptas todas las agrupaciones de cluster que te permite el método >Key Collision >Fingerprint verás como la columna de financistas pasó de tener 5,664 opciones diferentes, a tener 5,136 registros diferentes. 528 valores menos que eran repetidos pero contenían errores gramaticales o de sintaxis que hacían que la computadora no los tomara como iguales.
Así, en estos sencillos pasos, OpenRefine editó los valores de 54,807 celdas que manualmente tomarían demasiado tiempo para limpiar y estandarizar.
Para finalizar, haz click en >Export para descargar tu base de datos limpia en el formato que prefieras.Ya sea valores separados por coma, o por tabulaciones; formato para Excel o HTML, OpenRefine te permite escoger entre diversos formatos para descargar la versión limpia de tu base de datos.
Cuéntanos en qué casos puedes utilizar los clusters y OpenRefine para limpiar tus datos. Escríbenos a [email protected] o por twitter @escueladedatos y estaremos compartiendo algunos ejemplos de usos de esta herramienta.
![]()

Conoce más detalles sobre esta oportunidad…
Sobre la fellowship
Las fellowships son posiciones de 9 meses para personas apasionadas por los datos con talento y creatividad para generar actividades y proyectos innovadores. Durante este periodo de tiempo, los y las fellows trabajan como parte de la red de Escuela de Datos desarrollando nuevas habilidades y conocimientos ya sea relacionados con una temática social, la construcción de comunidades de datos y la formación para alcanzar un mayor uso de datos.
Este período es una oportunidad para que una persona con trabajo previo pueda desarrollar su potencial de una manera más plena, con el apoyo de la red de formadores y especialistas de Escuela de Datos.
La fellowship de Escuela de Datos te permite crecer, generar proyectos de mayor alcance y contar apoyo participar de eventos y conferencias internacionales, asi como organizar tus propias actividades y apoyar a tu comunidad local.
Como parte de este fellowship, nuestro objetivo conjunto es incrementar la alfabetización de datos y construir comunidades de práctica que cuenten con las habilidades en el uso de datos para poder cambiar su entorno. En este año, las fellowships tendrán un enfoque temático: las Contrataciones Abiertas, una oportunidad para fiscalizar cómo los gobiernos hacen uso de los bienes públicos y exigirles que rindan cuentas.
Una fellowship temática
Para enfocar el entrenamiento y experiencia de aprendizaje de las y los Fellows de Escuela de Datos 2018, este año se contempla un enfoque temático. Como resultado, se priorizará la selección de postulantes que:
- Cuenten con experiencia profesional o proyectos personales en relación con alguna arista de este enfoque temático.
- Muestren entusiasmo por el entrenamiento y la formación de capacidades. Ser fellow conlleva realizar talleres, mentorías y asesoría necesarias para formar en uso y manejo de datos.
- Conozcan a su comunidad local de organizaciones que trabajan en temas relacionados con transparencia, fiscalización, uso de datos y desarrollo sostenible. Que demuestren tener vínculos con quienes abordan esta temática de manera directa
Estamos buscando a individuos involucrados que ya cuentan con conocimiento profundo de un sector o tema, y que activamente han influenciado el uso de los datos en esa temática dada. Este enfoque permitirá a las y los Fellows iniciar rápidamente actividades y alcanzar lo máximo durante su participación en la Escuela de Datos: ¡nueve meses pasan muy rápido!
< Conoce más sobre el enfoque temático >
Nueve meses para generar un impacto
La Fellowship es de mayo a diciembre de 2018 y comprende por lo menos 10 días al mes del tiempo de cada Fellow para trabajar offline y online. La o el Fellow debe fortalecer su comunidad local a través de entrenamientos, apoyando proyectos basados en datos y satisfaciendo sus necesidades para el uso de datos. Virtualmente, la o el Fellow debe participar activamente en la red global de School of Data, compartiendo conocimiento a través de sesiones online, posts en el blog y contribuyendo con la generación y actualización de los recursos de enseñanza de la comunidad. Cada Fellow recibirá un apoyo mensual de $1,000USD por su trabajo.
Como parte del programa, todos los Fellows seleccionados participarán presencialmente en el SummerCamp 2018 de la red global de School of Data en donde conocerán a otros miembros de la comunidad, compartirán conocimientos y habilidades, aprenderán sobre métodos, tácticas y enfoques de entrenamiento de Escuela de Datos.
Buscamos a personas que tengan experiencia en trabajar con datos y diversas tecnologías, por eso el perfil profesional o de estudios es variable. En el pasado nuestros fellows han sido desarrolladores, comunicadoras, economistas y periodistas con diferentes habilidades específicas, pero algo en común: pasión por los datos y el trabajo en comunidad.
Las tareas comunes de la fellowship incluyen
- Construir comunidad local de usuarios y públicos, lograr primeros acercamientos con interesados en el uso de datos abiertos a través de talleres, charlas y meetups.
- Conocimiento básico de metodologías de uso de datos para enseñarle a otros y crear contenidos educativos que se publican en nuestro blog.
- Brindar asesoría técnica en el uso de datos y metodologías a otras organizaciones o proyectos
- Poder conducir un proyecto propio relacionado a los temas de la fellowship.
- Organizar, planificar y dar seguimiento a proyectos cívicos y la generación de diversos productos.
¿Qué estás esperando? Tienes hasta el 6 de mayo de 2018 para aplicar a esta oportunidad.
Para aplicar, ingresa al formulario
http://bit.ly/2018_fellowship
Para más información, escríbenos a [email protected] o tuiteanos a @EscuelaDeDatos
![]()

Muchas gracias a quienes siguen enviando contenidos y formando parte de la comunidad de Escuela de Datos.
Recuerda que tú también puedes publicar contenidos tutoriales o sobre experiencias de datos. Sólo escribe a [email protected], o al autor de este texto describiendo tu propuesta 
![]()