MediaCloud es una plataforma open source que registra el discurso mediático sistematizando el contenido noticioso de más de 25 mil fuentes digitales de más de 200 países, en múltiples idiomas. Esto, con la intención de potenciar el análisis que se hace sobre la atención que un tema particular tiene en la agenda mediática.
Por sus funciones, es una herramienta muy útil para periodistas, activistas, académicos, investigadores, creadores de contenido y organizaciones sociales. MediaCloud tiene tres herramientas principales: Explorer, TopicMapper y SourceManager. En este tutorial te enseñamos cómo empezar a usar Explorer.
Explorer es una herramienta que te permite buscar en la base de datos de MediaCloud, visualizar los resultados de esa búsqueda y descargar un archivo .CSV con las urls de las historias que coinciden con tu búsqueda. Con este buscador, obtendrás rápidamente un panorama general sobre cómo un tema de tu interés es cubierto por los medios digitales analizando la atención, el lenguaje y la representación del tema.
Explorer es un buscador en el cual puedes agregar las consultas o querys que desees y que además puedes ajustar al elegir fuentes de noticias específicas o una colección de fuentes y un rango de fechas. Explorer te permitirá identificar las fuentes e historias que lideran la conversación mediática sobre este tema, el lenguaje utilizado para hablar de él y las personas y lugares que mencionan.
Cómo buscar.
Luego de registrarte en MediaCloud entra a https://explorer.mediacloud.org y usa la caja de búsqueda para conocer sobre el tema de tu interés.
Al hacer una búsqueda, se desplegarán las siguientes opciones que te permitirán refinarla:
Enter a query
Haz una consulta. Escribe los temas, personajes o palabras clave que te interesa ver en los medios. Puedes usar operadores boléanos y otros parámetros de búsqueda avanzada que te describen aquí.
Select media
Selecciona los medios o las colecciones de fuentes de noticia que quieres buscar. MediaCloud cuenta con colecciones creadas previamente que puedes utilizar. Solo haz click en + Add media y busca entre las colecciones por zona geográfica, por alcance de la cobertura o busca medios específicos que quieres añadir a tu recolección de historias.
For dates
Escoge un período de tiempo entre dos fechas que filtre las historias que aparecerán en tu búsqueda.
Los resultados de tu búsqueda
En el panorama temático que Explorer presenta, ofrece diferentes visualizaciones y análisis sobre las historias que coinciden con tu búsqueda. Estos se concentran en trés áreas principales: Atención, Lenguaje, y Personas y Lugares. Cada una de estas funciones te permite descargar los resultados al hacer click en el botón Download Options y en algunas secciones te permitirá también descargar los resultados como imagen o gráfico.
ATENCIÓN:
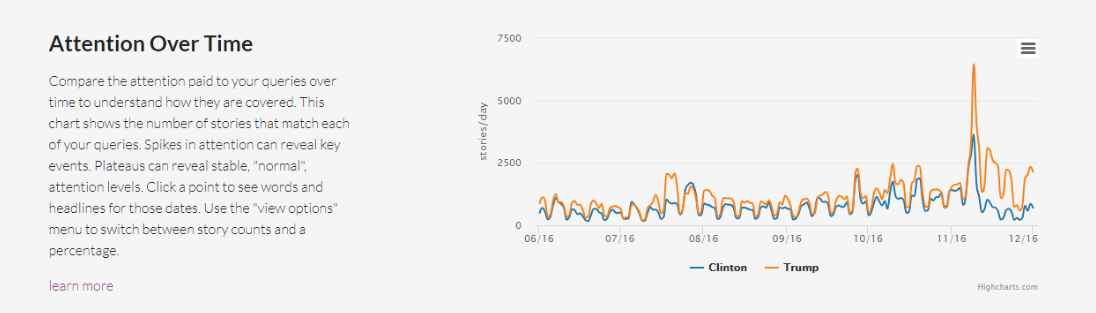
Attention Over Time
A través de una gráfica de líneas, Explorer te muestra la atención que los medios le prestaron a los temas de tu consulta para que entiendas cómo fueron cubiertos a lo largo del tiempo. Las alzas en el gráfico pueden evidenciar un evento clave o una historia popular. Puedes elegir entre ver un conteo de historias o un porcentaje que normaliza los resultados.
Total Attention
En esta sección, se compara el número total de historias que coinciden con tu búsqueda. Es muy útil cuando tu búsqueda incluye más de un query o consulta. O puedes añadir una nueva consulta escribiendo un asterisco * en los mismos rangos de fechas y con las mismas fuentes, para hacer obtener todos los resultados de historias independientemente de tu tema.

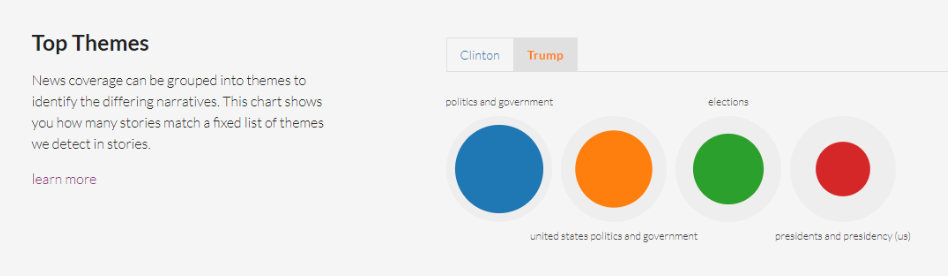
Top Themes
La cobertura noticiosa se clasifica en temas para identificar narrativas diferentes. A partir de una lista fija de temas noticiosos detectados, distribuye las historias que coinciden con tu búsqueda entre ellas. Te muestra un gráfico en el que cada coincidencia es un círculo de color, rodeado por un círculo gris que representa a todas las historias de tu búsqueda, para que sepas qué tantas de las historias están dentro de este tema. Esta clasificación se realiza a partir de un modelo construido tomando en cuenta una indexación anotada del New York Times que resultó en esta lista de 600 temas.
Sample Stories
Esta es una muestra aleatoria de historias sobre tu tema. Al menos una oración de esta historia coincide con tu búsqueda. Puedes ver algunas o descargar un CSV con las historias y sus URLs.

LENGUAJE:
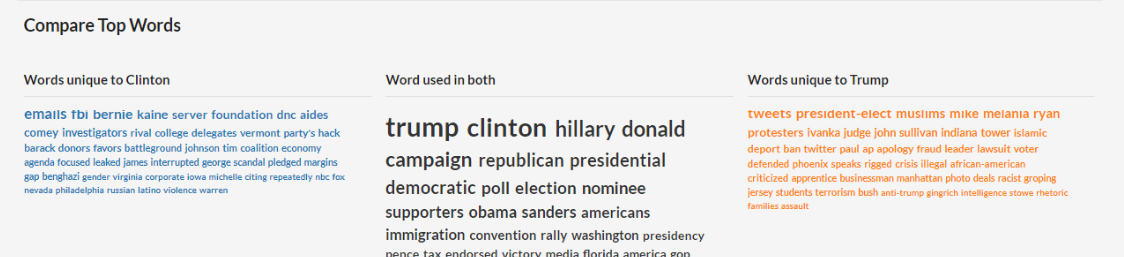
Top Words
Te muestra las palabras más utilizadas con cada búsqueda. Este panorama de palabras puede ayudarte a identificar de qué manera se aborda este tema en los medios digitales. La nube de palabras se muestra de manera ordenada: aquellas que más aparecen tendrán un mayor tamaño y estarán primero en la lista. Se basa en una muestra representativa de las historias, pero no en todos los resultados de la búsqueda. El conteo de palabras completo se puede descargar como CSV y también una versión de bigramas (frases de dos palabras) o trigramas (frases de tres palabras) que más se usan en las historias. Cuenta las palabras en base a su raíz.
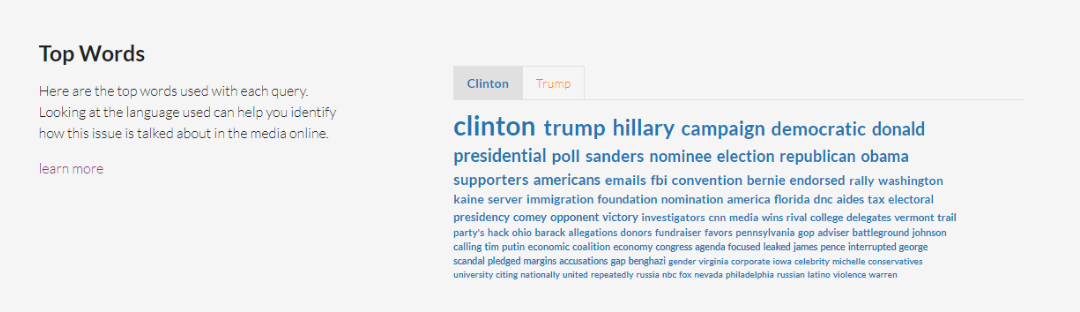
Word Space
Para entender qué palabras se usan junto a otras, esta función te muestra una gráfica con las 50 palabras más usadas en el tema. Mientras más grande y oscura sea, más aparece en las historias de los medios. Las palabras se distribuyen en un radio según qué tan similar aparecen juntas en el reporteo general de noticias. Al mover el cursor por el radio verás cómo se resaltan palabras que son frecuentemente usadas juntas. La distribución se basa en el modelo de machine learning word2vec y un proyecto de Google News.
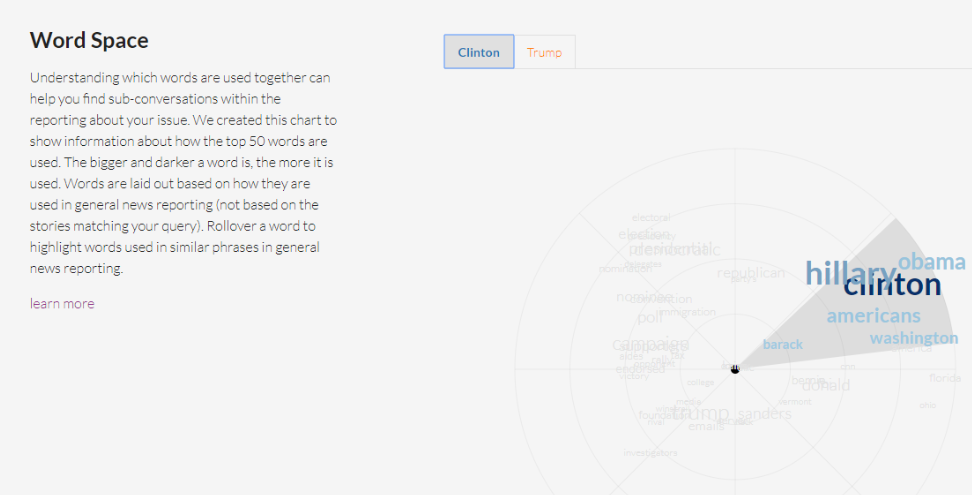
Compare Top Words
Esta sección compara las palabras más utilizadas en cada una de tus consultas y las ordena de mayor a menor, para enfatizar en la diferencia de lenguaje utilizado en las historias recopiladas por MediaCloud para cada consulta.
PERSONAS Y LUGARES:
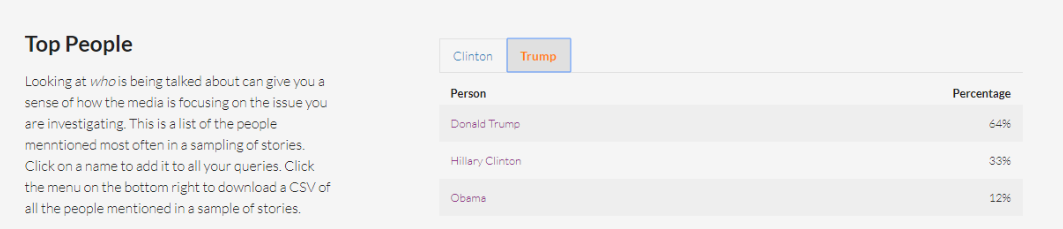
Top People
Ver a quienes mencionan en las historias puede darte una idea de cómo los medios cubren el tema de tu interés. En esta lista MediaCloud te presenta los personajes que más aparecen en una muestra de historias. Al hacer click en un nombre, lo puedes añadir a tu consulta o búsqueda. Esto se logra utilizado el Reconocedor de Entidades Nombradas de Stanford. Cada historia es etiquetada con las personas, organizaciones, países y estados que menciona.
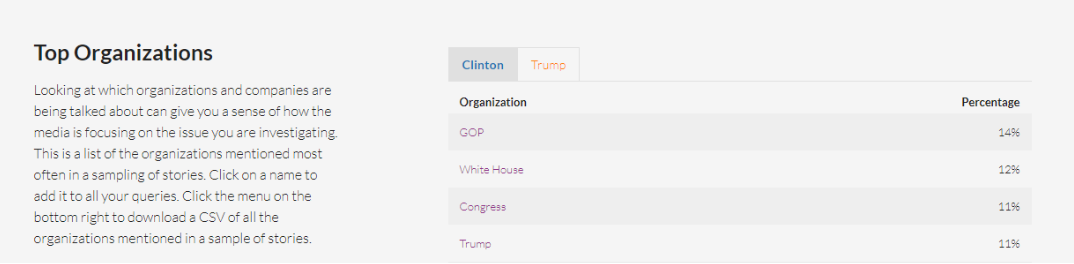
Top Organizations
Esta sección funciona igual que la anterior, pero con nombres de organizaciones, empresas e instituciones.
Geographic Coverage
La cobertura de un tema puede variar en función del lugar del que se habla. Al revisar la geografía a través de un mapa puedes comparar los países que fueron el centro de las historias. Los lugares con un color más intenso fueron repetidamente el foco de las historias.
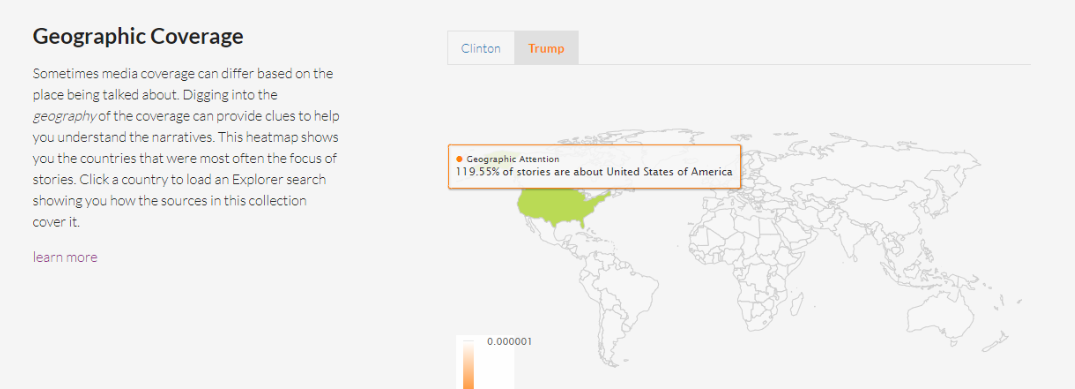
Con este panorama amplio, Explorer facilita sacar algunas conclusiones y preparar gráficos que dan insights sobre cómo se aborda un tema en los medios digitales.
Cómo se creó está herramienta
MediaCloud es un proyecto creado por los equipos del Centro para Medios Cívicos del MIT y el Centro Berkman Klein para el Internet y la Sociedad de la Universidad de Harvard. Para lograr la capacidad de análisis y de rastreo de datos esta herramienta colecciona los hipervínculos y otro tipo de enlaces: Bitly, Facebook y Twitter, por ejemplo. La gran mayoría del contenido proviene de los canales RSS de cada organización mediática. Los datos de cada fuente varían, dependiendo del momento en que MediaCloud comenzó a hacer el scrapping o raspado de datos. Debido a restricciones de derechos de autor, la herramienta no puede proveer los textos de las historias, pero presenta la lista de URLs para que el usuario pueda obtenerlo por su cuenta.
![]()
¿Te has encontrado con bases de datos que tienen pequeños errores de transcripción? ¿Espacios de más, uso desordenado de mayúsculas y minúsculas, o registros que representan al mismo dato pero que fueron escritos con pequeñas diferencias? Con la herramienta OpenRefine puedes automatizar mucho del doloroso proceso de limpiar una base de datos. En este tutorial te enseñaremos una de sus funciones más útiles: la clusterización —o generación de agrupaciones automáticas— y los diferentes algoritmos que determinan las coincidencias entre registros.
El concepto de clusters (o agrupaciones, en español) se utiliza mucho en ciencias sociales y exactas para referirse a un tipo de análisis que toma un conjunto de datos y las reorganiza en grupos con características similares.
En OpenRefine, cuando uno hace clusters significa que el programa está encontrando grupos de valores diferentes que pueden ser representaciones alternativas del mismo valor. Por ejemplo, si hablamos de ciudades, “New York”, “new york” y “Nueva York” son tres valores diferentes pero que se refieren al mismo concepto, sólo con cambios de idioma y de uso de mayúsculas y minúsculas.
Vale la pena mencionar que las agrupaciones en OpenRefine sólo se generan automáticamente en la sintaxis (o sea, el orden y la composición de caracteres que tiene como valor una celda) y aunque estos métodos son útiles para encontrar errores e inconsistencias, no son lo suficientemente avanzados para determinar agrupaciones a nivel semántico (o sea, el significado de un valor).
Estos métodos se pueden aplicar determinando cuántos grados de cercanía -en otras palabras, qué tan estrechas o flojas quieres encontrar las coincidencias-. Al graduar la cercanía encuentras coincidencias más o menos exactas. Por eso es importante que si bien, los algoritmos ayudan a automatizar la tarea de limpieza, un ojo y cerebro humano va administrando qué tan agresivas deben ser estas uniones para encontrar coincidencias, para evitar que asocie datos que no deberían ir juntos.
Conozcamos los algoritmos: En qué consisten estas metodologías
Existen dos grandes metodologías para hacer clusters: la colisión clave y el vecino más cercano. Open Refine utiliza diferentes variantes de estos dos métodos. Aquí te explicamos cuál es el proceso detrás de cada uno.
Sección 1: Métodos de colisión clave
Estos se basan en la idea de crear una representación alternativa de un valor inicial, el cual se convierte en una clave. Una clave contiene las partes más distintivas y significativas de un valor. OpenRefine va buscando en los demás registros qué otros valores se parecen a esta clave para agruparlos. El procesamiento requerido para este método no es muy complejo, por lo que presenta resultados muy rápidos. Este método tiene varias funciones diferentes que se pueden administrar en OpenRefine.
- Fingerprint
Un método fácil y simple. Quita todos los espacios en blanco, cambia todos los caracteres a minúsculas, remueve toda la puntuación y normaliza cualquier caracter especial a una versión estándar. Luego, parte el texto y aplica espacios en blanco. Así encuentra las coincidencias.
- N-Gram Fingerprint
Es similar al anterior, pero en vez de separar los caracteres por espacios en blanco, usa una cantidad a la enésima (n) potencia de espacios que el usuario puede determinar.
- Fingerprint Fonético
Este método no revisa los caracteres textuales sino su pronunciación y fonética: la manera en que esa palabra se pronunciaría, en vez de revisar similitudes en la escritura. Es muy útil para limpiar datos con nombres particulares, ya sea de lugares y personas. En ocasiones, los errores de registro se deben a que se registran a partir de la pronunciación. Sirve para encontrar similitudes entre sonidos parecidos pero que se escriben muy distinto como el sonido de “sh” y “x”, que en ocasiones son similares.
Sección 2: Vecino más cercano (Nearest neighbor)
Estos métodos proveen un parámetro o radio de aproximación alrededor de un valor o palabra, y va encontrando los grados de similitud entre éste y otros registros. Debido a los cálculos necesarios, estos métodos son más tardados en procesar.
- Distancia Levenshtein
Este método se basa en el trabajo y proceso que implicaría cambiar a un registro A para que sea igual a un registro B. La distancia Levenshtein mide cuántas operaciones de edición -o cuántos pasos- le tomaría a alguien hacer que un dato se parezca al otro. Encuentra coincidencias entre los datos que están separados por la menor cantidad de pasos o cambios.
Por ejemplo, “Paris” y “paris” tienen una distancia de edición de 1, ya que solo se debe cambiar la P mayúscula a una minúscula. Sin embargo, “Nueva York” y “nuevayork” tienen una distancia de 3 pasos: dos sustituciones y un borrón.
- PPM (Prediction by Partial Matching)
Este método se utiliza para encontrar coincidencias en secuencias de ADN. Estima la similitud entre textos y determina su contenido idéntico. Por ejemplo, con el ADN encuentra similitud entre dos muestras para indicar un grado de familiaridad. Es común en este campo que no se busque una coincidencia exacta (que implicaría trabajar con muestras de ADN de la misma persona) sino encontrar un alto grado de coincidencia y familiaridad.
Si dos cadenas A y B son idénticas, al concatenar A+B debería de producirse muy poca diferencia. Pero si A y B son diferentes, al concatenar A+B se deberían producir diferencias muy dramáticas en la longitud de la cadena.
Paso a paso. Aplicando los clusters en OpenRefine
 OpenRefine es un programa que corre a través de tu browser o navegador de internet. Para instalarlo, es necesario que lo descargues en este link y sigas las instrucciones para tu equipo. Usualmente, solo requiere que descargues la carpeta, la descomprimas y abras la aplicación.
OpenRefine es un programa que corre a través de tu browser o navegador de internet. Para instalarlo, es necesario que lo descargues en este link y sigas las instrucciones para tu equipo. Usualmente, solo requiere que descargues la carpeta, la descomprimas y abras la aplicación.
OpenRefine debería abrir una ventana negra con algunos códigos y abrirse automáticamente en tu navegador de internet. Si no funciona, prueba ir a la dirección http://127.0.0.1:3333/
Vamos a hacer un ejemplo con un conjunto de datos sobre financistas a las elecciones del 2017-2018 en Estados Unidos que puedes descargar aquí.
Para subir el archivo, solo sigue los siguientes pasos:
Create project > Elegir archivo (selecciona el archivo ZIP que descargaste) > Next
OpenRefine te mostrará una previsualización de tu conjunto de datos. En este caso, deberás desmarcar la opción >Parse Next para indicar que tu base de datos no tiene títulos de columna en la primera fila.
En >Project Name, escribe “Financiamiento político_Estados Unidos 2017-2018” y da click a >Create project para guardar este proyecto.
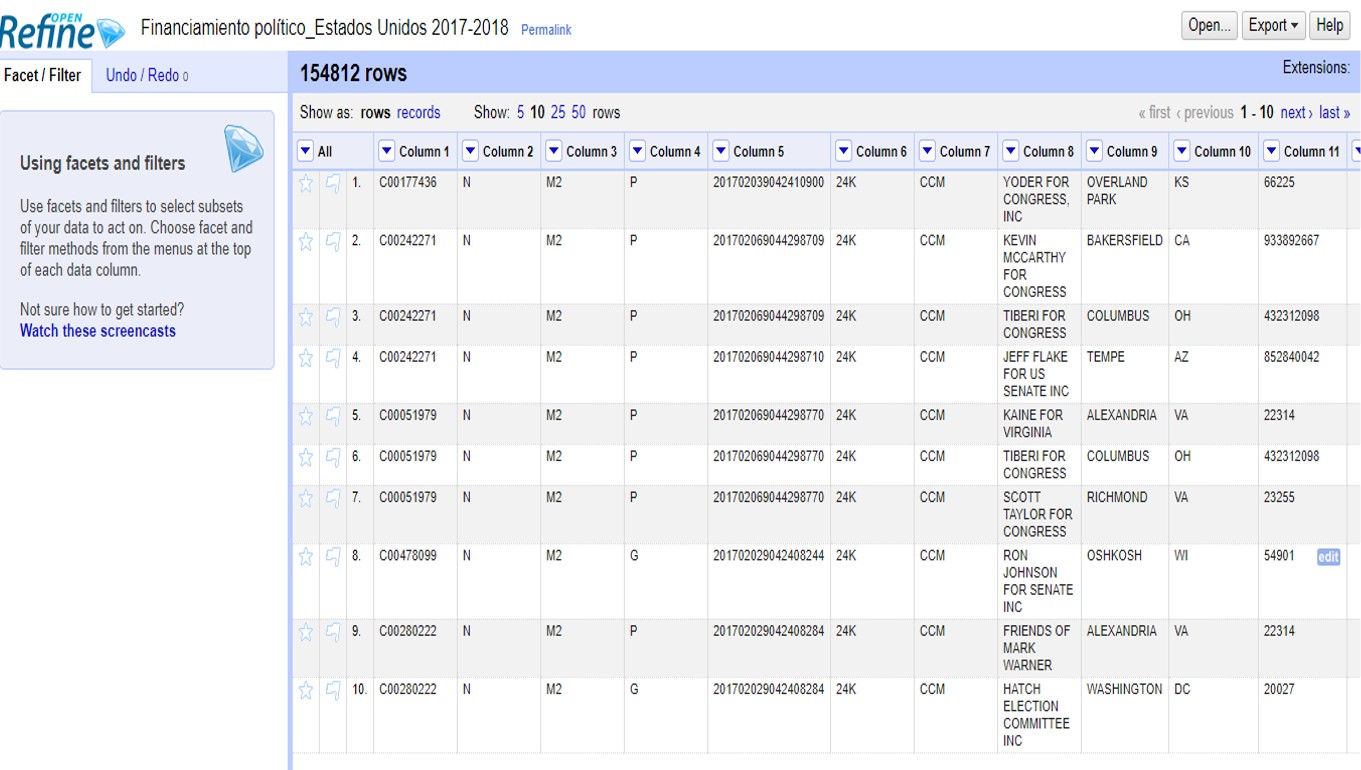
En la columna 8 encontrarás el listado de financistas. Haciendo click en el triángulo a la par del título de esta columna, selecciona >Facet >Text facet para generar un filtro de texto.
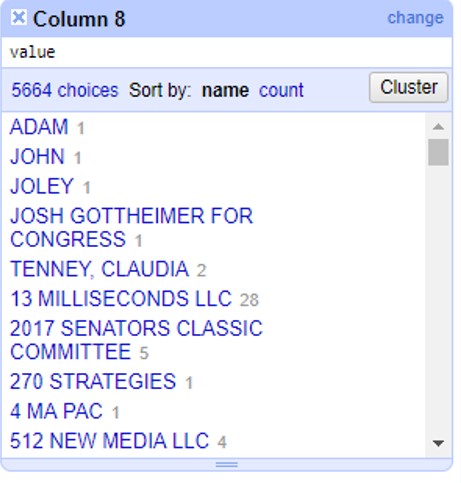
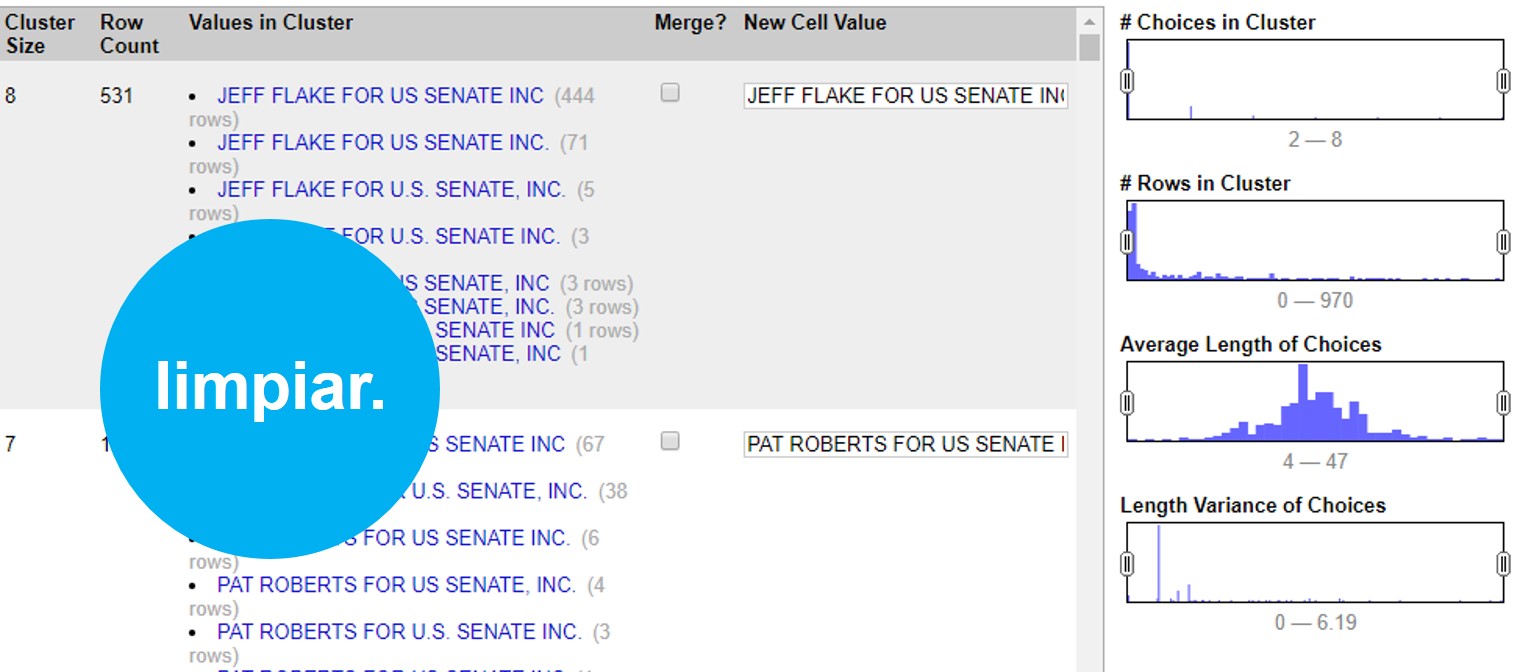
A un lado, te aparecerán todos los registros de financistas en orden alfabético, con un número a la par que indica cuántas veces aparece este nombre en la base de datos. Haz click en el botón >Cluster para empezar a generar agrupaciones automáticas.
En la siguiente ventana puedes aplicar todos los métodos de clusters que te enseñamos. Puedes administrarlo cambiando las opciones >Method, >Keying Function o >Distance Function.
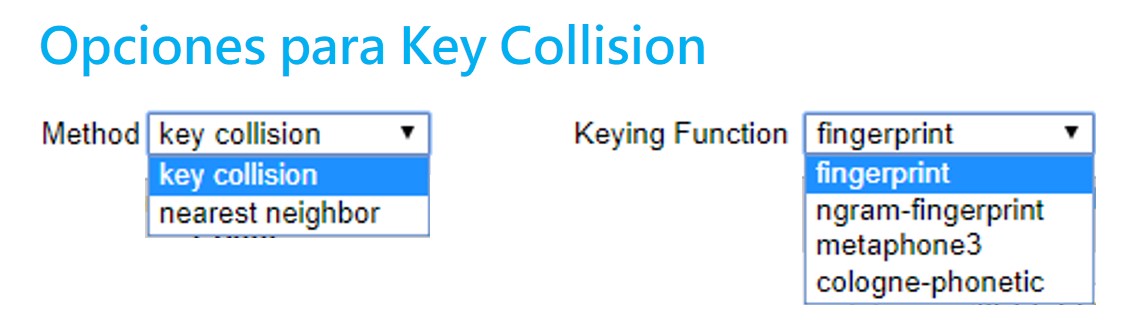

Con estos controles podrás ir determinando qué tan agresivos son tus clusters. Independientemente del método que eligas, el proceso es el mismo. Al seleccionar el método y sus opciones, OpenRefine comenzará a procesar los datos para encontrar coincidencias y armarlas en un cluster o agrupación.
En este ejemplo podemos ver que el programa encontró 531 valores muy similares, escritos de 8 maneras diferentes para decir lo mismo: que un financista se llama “JEFF FLAKE FOR U.S SENATE, INC”. Como puedes ver, a la par de cada manera de escribir, OpenRefine te muestra cuántas veces aparece de esta manera el valor.
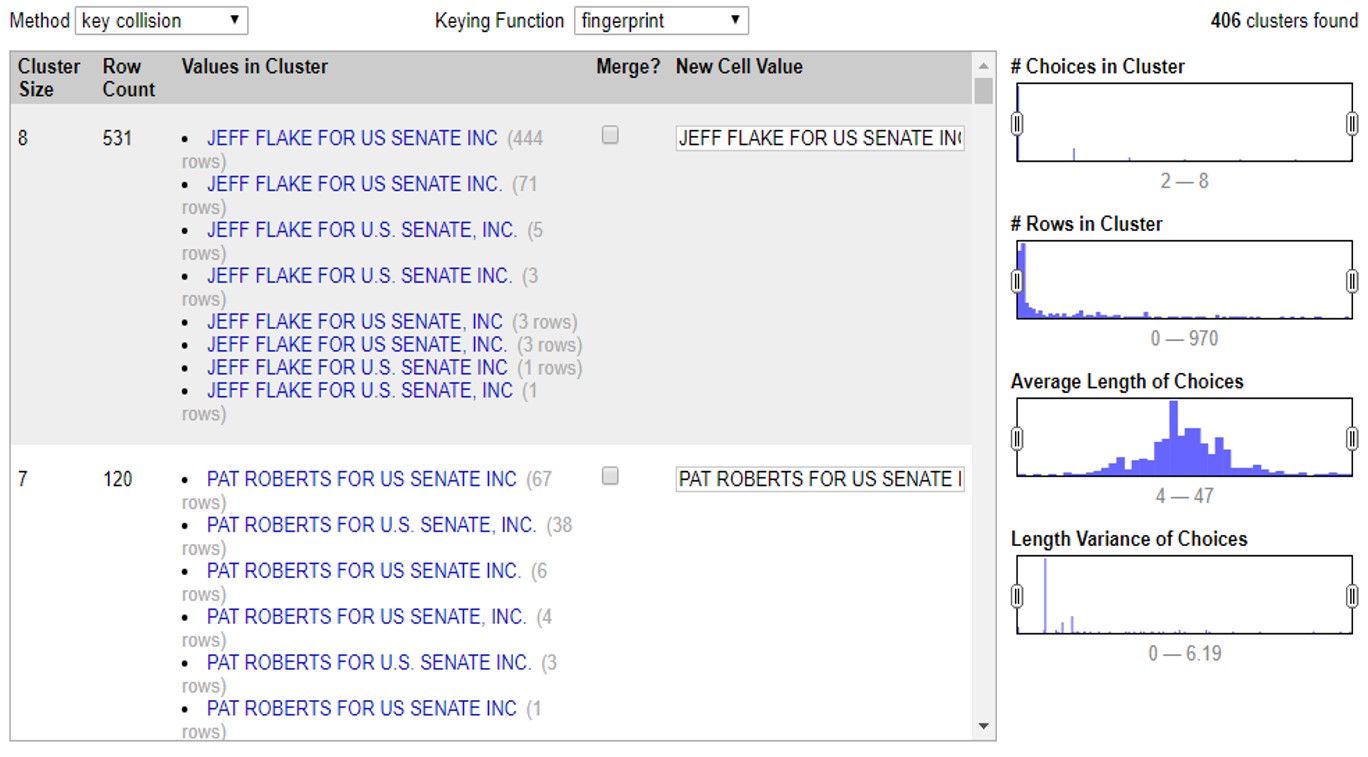
En este caso te muestra dos opciones. La primera, >Merge incluye una casilla que puedes seleccionar en caso de que sí quieras que OpenRefine una estos valores. En la segunda opción >New Cell Value, el programa te da la oportunidad de que edites y decidas de qué manera quieres que se reescriba este cluster. Así, irás administrando la agrupación valor por valor, decidiendo si quieres o no agrupar los valores con >Merge y la opción de escritura bajo la cual estos valores se agruparán con >New Cell Value
Con este ejemplo, si aceptas todas las agrupaciones de cluster que te permite el método >Key Collision >Fingerprint verás como la columna de financistas pasó de tener 5,664 opciones diferentes, a tener 5,136 registros diferentes. 528 valores menos que eran repetidos pero contenían errores gramaticales o de sintaxis que hacían que la computadora no los tomara como iguales.
Así, en estos sencillos pasos, OpenRefine editó los valores de 54,807 celdas que manualmente tomarían demasiado tiempo para limpiar y estandarizar.
Para finalizar, haz click en >Export para descargar tu base de datos limpia en el formato que prefieras.Ya sea valores separados por coma, o por tabulaciones; formato para Excel o HTML, OpenRefine te permite escoger entre diversos formatos para descargar la versión limpia de tu base de datos.
Cuéntanos en qué casos puedes utilizar los clusters y OpenRefine para limpiar tus datos. Escríbenos a [email protected] o por twitter @escueladedatos y estaremos compartiendo algunos ejemplos de usos de esta herramienta.
![]()
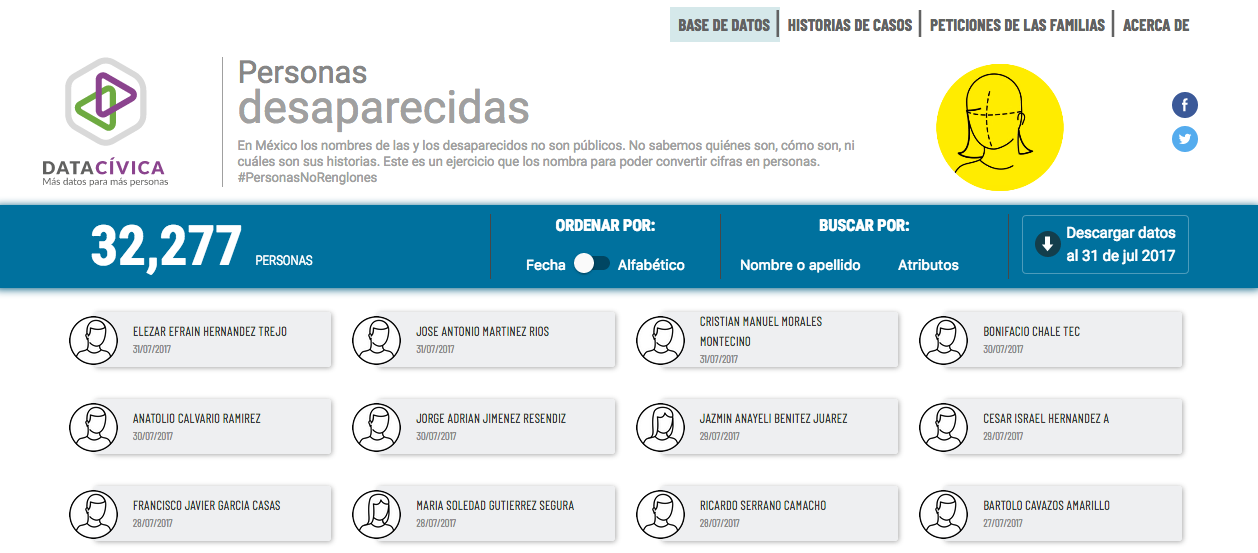
A dos semanas de su lanzamiento (el 14 de noviembre en Ciudad de México) la publicación de más de 31 mil nombres de personas desaparecidas propició que al menos 15 familias y dos colectivos de búsqueda acusen errores tan fundamentales como que el nombre en la base de datos no corresponde al familiar desaparecido, sino a otro famliar, que no lo está.
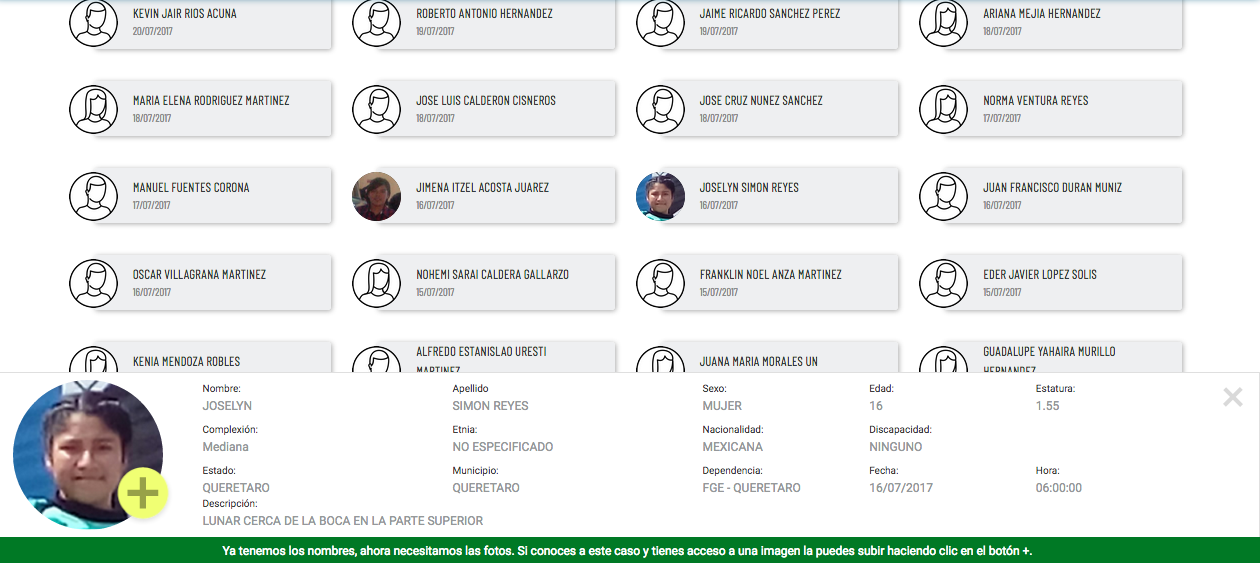
«El primer gran error (de RNPED), es que las personas desaparecidas no están; el segundo, que datos tan importante para la investigación como la fecha de desaparición, están mal. En uno de los casos, nos contactó la hija de la persona desaparecida diciéndonos que el nombre que está en la base es el de su tío (en lugar del de su padre desaparecido)», dijo en entrevista Héctor Chávez, analista de datos en Data Cívica.
Además de facilitar a familias y organizaciones la verificación de fechas y lugar de desaparición junto con los nombres, la base permitirá una actualización de la base que le otorgue mayor confiabilidad, pues podrá investigarse quiénes, por ejemplo, salen de la base de datos, y por qué razones.
«Podemos ya contar historias sobre las personas desaparecidas con esos nombres. ¿Por qué salió de la base? ¿Se rectificó el delito de desaparición por el de secuestro, fue encontrada la persona con vida, fue encontrada sin vida?», dice Chávez.
Una más de las ventajas de la publicación de los nombres es que finalmente puede cruzarse esta base con las que tienen las organizaciones y colectivas de búsqueda de personas desaparecidas que se han construido en varias entidades del país, y así combatir una de las mayores barreras para el análisis confiable de estos datos: la cifra negra.
«En contacto directo, nos han enviado también doscientas veinte fotos de familiares. Al menos quince familias y dos colectivos de búsqueda nos han contactado. La solución que estamos planteando es en el futuro es publicar un formulario donde sea posible añadir la información del familiar o persona en cuestión».
Días después de la publicación de personasdesaparecidas.org.mx, el representante del poder ejecutivo mexicano firmó la Ley General de Desaparición Forzada de Personas y de Desaparición cometida por particulares, luego de dos años de que se publicara el proyecto de ley en la Gaceta Oficial de la Federación.

Esta ley contempla la publicación obligatoria de todos los nombres de las personas desparecidas en la base oficial, del fuero común o federal. No obstante, la ley no cuenta con mecanismos concretos de implementación aún, como un presupuesto que lo respalde. Por ello, Chávez considera que la publicación de su base se adelanta a la implementación de la ley.
«Estamos ganando meses o hasta años hasta que se publiquen (los nombres en RNPED). La nueva ley sí se habla muy bien con nuestro registro, sin embargo estamos ganando tiempo para las familias en este proceso de memoria y justicia para los desaparecidos”.
Cómo se hizo
La base consiste en la publicación de los datos oficiales de RNPED más 31 mil 968 nombres faltantes. Para lograrlo, el equipo de Data Cívica pasó dos años ideando e intentando distintos métodos.
“El principal camino fue darnos cuenta de que en internet está la base de de datos disponible, donde al insertar el nombre, Sergio, salen todos los registros junto con sus atributos: la fecha donde desapareció, el municipio donde desapareció, entre otras, pero no el nombre completo».
La solución que ideó el equipo de Data Cívica fue ingresar nombre por nombre a la base de datos y descargar cada uno de los registros de cada nombre y apellido para después cruzar los distintos registros y encontrar concordancias.
Aunque al principio trataron de construir la lista de nombres manualmente, finalmente llegaron a la idea de de automatizar el ingreso de nombres usando los que se encuentran en las bases de datos del beneficiarios de los burós de salud y asistencia social mexicanos, el Instituto Mexicano del Seguro Social (IMSS) y de Secretaría de Desarrollo Social (respectivamente).
La automatización, ingreso y descargas de los datos de estas bases tardó alrededor de 5 días, y dependió para lograrlo no sólo de la velocidad de procesamiento bajo el código utilizado, sino de la velocidad de conexión a internet que permitiera la descarga de 18 mil bases de datos.
Pero el proceso más intensivo del análisis ocurrió después de la descarga.
«El reto fue el proceso de limpieza y de verificación. Consistió en verificar contra RNPED que cada «Munoz» que está mal escrito, cada Zúñiga y otros, realmente está mal en el RNPED, y no es un error de la automatización de nuestros nombres».
Así, el equipo de Data Cívica se cercioró de que si en la base aparece J en lugar de un nombre, sea porque así está en la base original.
![]()
En esta colaboración, Adrián Pino, coordinador de Datos Concepción y Soledad Arreguez, periodista, investigadora y colaboradora de la misma organización, comparten cinco aprendizajes clave sobre la creación y navegación del portal de datos abiertos.
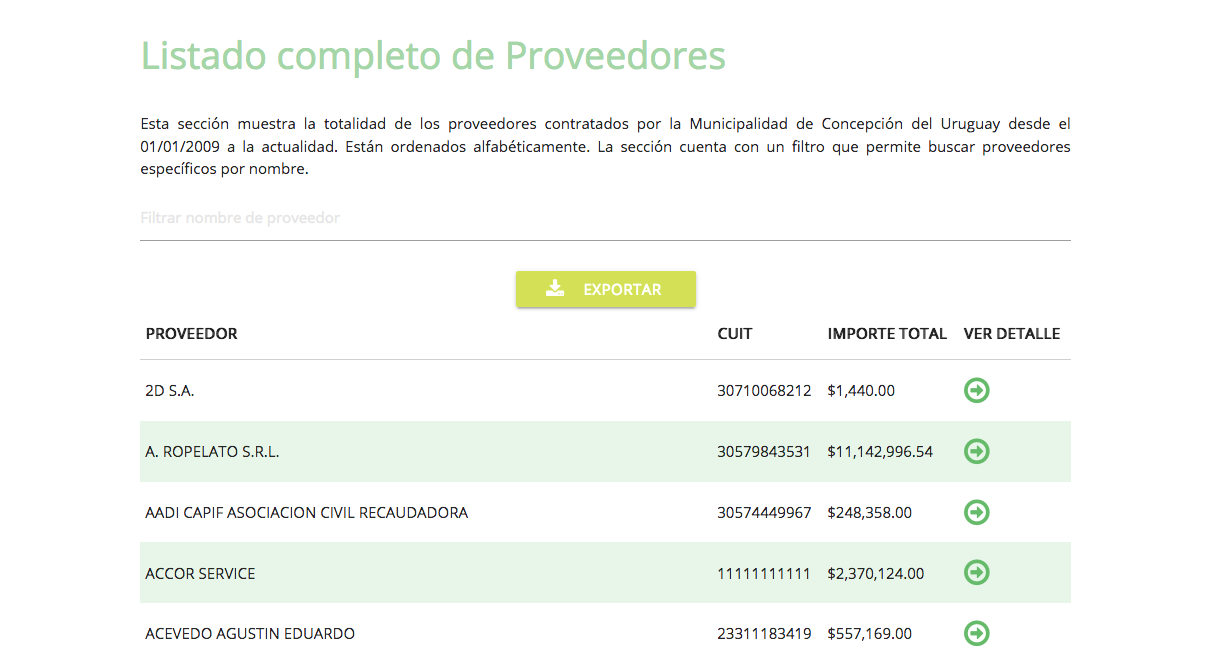
El proyecto nació hace un año con la meta de montar el primer portal de transparencia de la provincia de Entre Ríos (Argentina) para la Municipalidad de Concepción del Uruguay. La plataforma se lanzó el lunes 4 de Julio de 2017 y ya está en línea en www.concepciontransparente.org. desde allí es posible el acceso a los gastos del Municipio desde 2009 hasta la actualidad.
La plataforma (en versión beta) permite a los usuarios filtrar y visualizar el régimen de contrataciones y otras modalidades a partir de la información oficial que publica la Municipalidad, incluyendo la cantidad de órdenes de compra, el ranking de obra pública y el monto que percibió cada proveedor.
El coordinador de Datos Concepción, Adrián Pino, dijo que “el desafío implicó pensar en una herramienta dinámica, simple de entender para el común de los usuarios y con una fuerte apuesta a estructurar los datos de forma clara y ordenada para que sea fácil efectuar búsquedas, seleccionar proveedores y descargar la información”.
Aprendizajes
1. Mostrar los contratistas de la Obra Pública
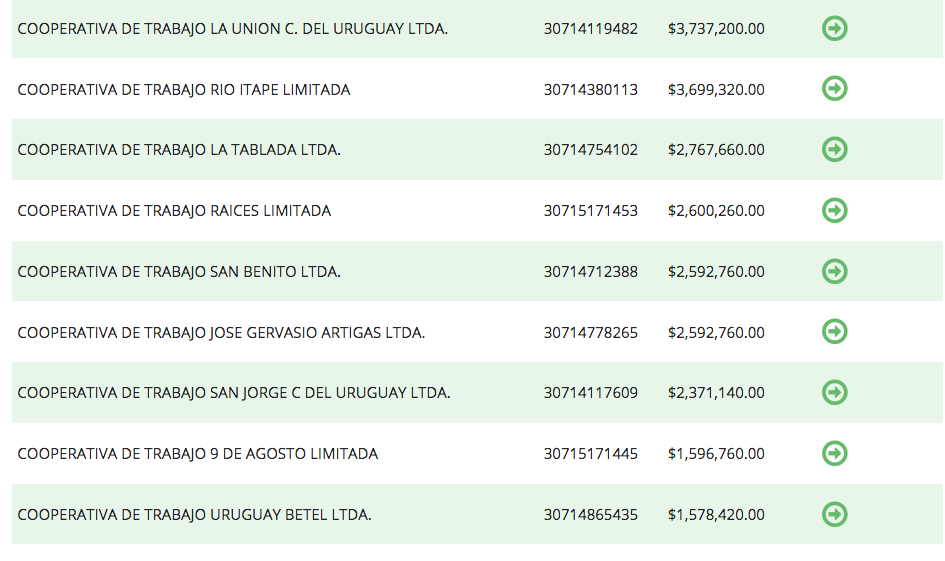
La enorme sensibilidad que despiertan los hechos de corrupción vinculados a las coimas en las obras Públicas vuelve necesario exhibir un Ranking de Contratos de Obra Pública para dar seguimiento a los principales beneficiarios de este rubro. No hay transparencia posible si no se identifica claramente quiénes son los principales contratistas de la obra pública, cuántos contratos recibieron y por cuánto dinero.
2. Filtros para bucear en los datos
Para promover un gobierno transparente hay que permitir que todas las contrataciones estén disponibles y en línea, y puedan ser exploradas con filtros para comparar. El control cruzado de proveedores y los procesos de auditoría cívica que permite el Portal Concepción Transparente marcan un piso elevado para los intentos de corrupción. La posibilidad de interactuar con los datos es crucial en este tipo de proyectos.
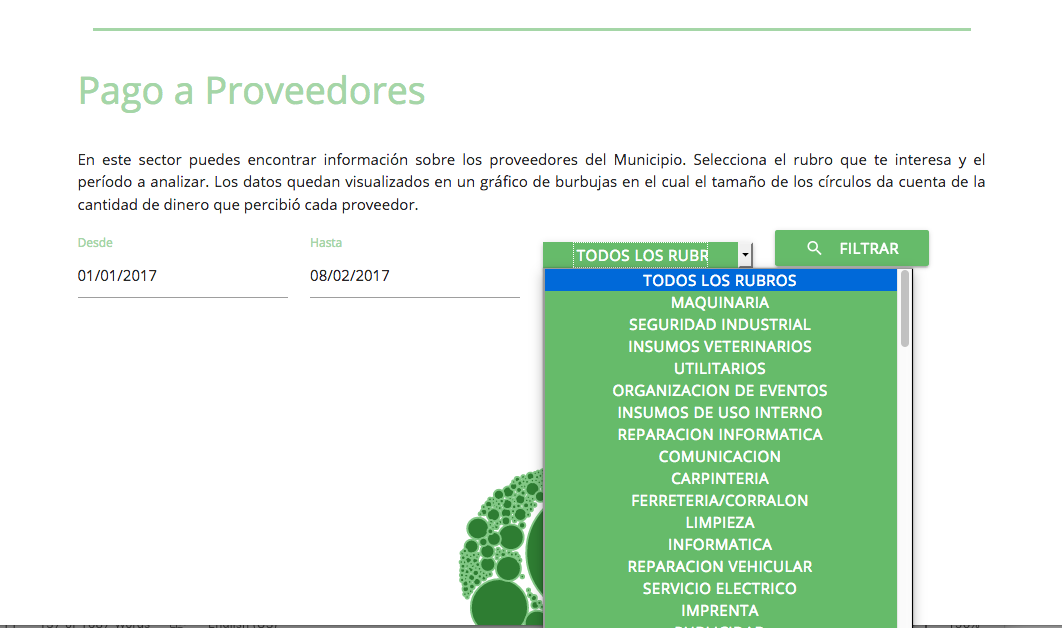
3. Permitir el análisis a través del tiempo
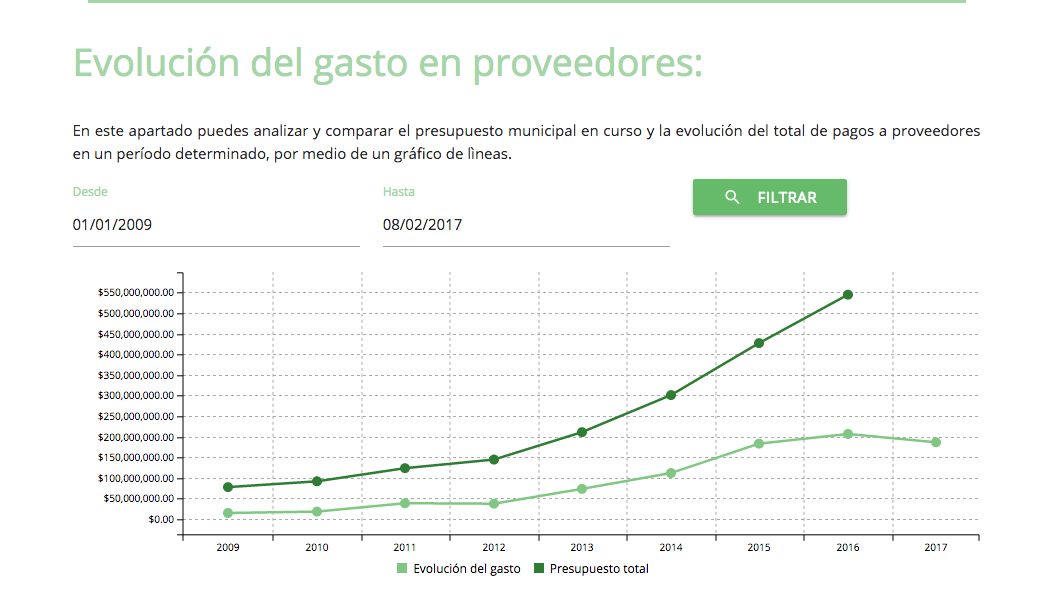
Si se muestra información a partir de los años disponibles, es posible trabajar con el filtro de fecha, que permite analizar algunos patrones en los datos y gastos de los Municipios.
4. Visualizaciones interactivas.
La sencillez y claridad de las visualizaciones es una necesidad creciente entre los Portales de Transparencia, que tienen la enorme misión de ayudar a los ciudadanos a entender el destino de los dineros públicos.

5. Datos Abiertos
La disponibilidad para descargar los datos en formatos abiertos es un requisito cada vez más necesario en la promoción de formas de empoderamiento que impulsan los procesos de apertura y transparencia de datos públicos. Con más datos en poder de los usuarios, es más probable que haya mejores controles para evitar el desvío de fondos públicos.
El desafío de escalar
El trabajo de Datos Concepción en el desarrollo de esta herramienta contó con las aportaciones del equipo de Genosha y se estructuró con un esquema que permite ser adaptado a los requerimientos de otros Municipios de Latinoamérica. En esta etapa posterior al lanzamiento estamos mejorando las prestaciones del Portal, agregando funcionalidades y visualizaciones que mejoren la comprensión de los gastos de cada Municipio.
El esfuerzo de nuestro equipo está enfocado en ciudades de hasta 300 mil habitantes, entendiendo que los Municipios de menor cantidad de población son los que requieren más acompañamiento para avanzar en políticas de Transparencia y Apertura de Datos.
En este momento el equipo de Datos Concepción está a la búsqueda de financiamiento adicional que les permita escalar a otros Municipios de Latinoamérica que ya han mostrado interés en replicar este Portal de Transparencia.
![]()
Daniel Suárez Pérez, coordinador del proyecto colombiano Datos Al Tablero, comparte cómo éste se inició, cómo se desarrolló, y los retos que aún tiene por delante.
Datos al Tablero se realizó vía School of Data, a través del Data Member Support, en alianza con el movimiento Todos por la Educación. Es una análisis de la desigualdad educativa en Colombia, a través de la recolección y análisis de datos sobre deserción y repitencia entre 2012 y 2015.
![]()

Periodistas, economistas y desarrolladores, ex fellows del programa Fellowship de School of Data, detallan qué es y cómo se han servido del fellowship para crecer la comunidad de datos en Latinoamérica
Han influido en la rendición de cuentas nacionales de Perú y Costa Rica con publicaciones como Decide por tu Cantón o Cuentas Juradas; han capacitado periodistas para que detallen la confiabilidad de gasolineras, como en Gasolineras honestas, y han contribuido a la vinculación de datos sobre mineras en Perú, a través del Instituto de Gobernanza de Recursos Naturales.
Pero, por encima del alcance de proyectos específicos en los que trabajaron durante el Fellowship de School of Data, los fellows latinoamericanos que hasta ahora han participado evalúan el impacto de su trabajo en términos de su contribución para la creación de una escena local y regional en el uso efectivo de datos, que se une a una red global que tiene el mismo propósito.
Camila Salazar y Julio López, seleccionados de la Fellowship 2015, así como PhiRequiem y Antonio Cucho, en 2014, detallan cómo compartieron sus conocimientos sobre apertura de Datos a una red global de actores sociales, los retos que enfrenta la escena local y las enseñanzas que obtuvieron de sus fellowships, vis a vis la convocatoria para este Fellowship 2016.
Para los participantes, el fellowship fue la oportunidad única o bien para generar escenas locales y regionales de apertura, limpieza y visualización de datos, o de elevar la solvencia técnica de comunidades periodísticas, o contribuir a movimientos de transparencia de recursos naturales, con el soporte de una comunidad global y regional que, además, les otorgó visibilidad a una enriquecedora red de actores sociales.
Periodismo de datos y Datos sobre la industria extractiva son dos de los temas en que ellos se especializaron, y forman parte de los enfoques temáticos de la convocatoria para el Fellowship 2016.
La primera entrega es esta entervista con Camila Salazar, fellow de Costa Rica en 2015
Lee la entrevista con Camila Salazar aquí
La segunda entrega es una relación del proceso de capacitación, principalmente en Centroamérica, de PhiRequiem, fellow de México en 2014.
Lee la entrevista con PhiRequiem aquí
La tercera y penúltima entrega es una entrevista con Antonio Cucho Gamboa, fellow por Perú en 2014, fundador de Ojo Público, Open Data Perú, y un fellowship nacional.
Lee la entrevista con Antonio Cucho aquí
Nuestra última entrega es nuestra entrevista con Julio López, fellow por Ecuador en 2015, quien inauguró lo que hoy una línea temática del fellowship: la extracción, gestión y visualizació de datos sobre recursos minerales.
Lee la entrevista con Julio López aquí
![]()