CC by SA Monyo Kararan
Hay todavía un abismo entre el discurso de datos abiertos y el impacto que esta apertura, publicación, vinculación y otras prácticas tienen en la vida de las poblaciones globales. El puente entre los extremos de ese abismo es la relevancia de los datos, es decir, la capacidad que estos tienen para ser aprovechados efectivamente por las diversas poblaciones globales. Este abismo parece especialmente insondable para poblaciones que son política y socialmente excluidas.
La vinculación de los dos extremos de ese hueco es cada vez de una necesidad mayor, toda vez que organismos, oficiales y autónomos globales, han adoptado en mayor o menor medida dicho discurso de apertura de datos.
Es necesario en este punto, a la vez que admitir los avances, prestar atención a las muchas deficiencias en políticas de apertura en regiones específicas, reconocer que la apertura no es un fin en sí mismo, y que resulta trivial si no viene aparejada de garantías de acceso y uso de los conjuntos de datos. Más aún, resulta indispensable establecer mecanismos concretos y específicos para corregir esta deficiencia.
Para ello deben desarrollarse estándares contextuales, técnicos y de evaluación, con miras a la inclusión de amplias poblaciones que se beneficien del impacto de las políticas de apertura de datos.
El eje técnico
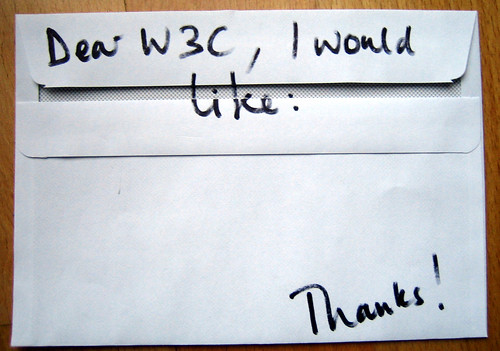
CC by NC SA Paul Downey
En un sentido técnico, la relevancia de datos es una métrica de calidad de datos que vincula los sets de datos disponibles con el interés de actores sociales. En este mismo sentido, parte del abismo entre apertura e impacto es irónicamente un vacío de (meta)datos: aquellos que se refieren a las potencialidades de “consumo” de dichos conjuntos de datos.
En una publicación sobre prácticas recomendables para la publicación de datos en la web, el World Wide Web Consortium (W3C) detalla una serie de criterios para que los conjuntos de datos sean vinculables y aprovechables en máximo grado. Entre estas prácticas, se encuentra el uso de un Vocabulario para el Uso de Conjuntos de datos (DUV, por sus siglas en inglés), para proveer un modo de retroalimentación entre “consumidores” y “publicadores” de datos sobre el uso de los mismos. Por ejemplo, agregando metadatos descriptivos a los conjuntos de datos, tanto sobre la base en sí misma, como de sus posibles usos. De esta manera, se generan metadatos que permiten contrastar el uso sugerido y el reuso dado.
Estas nuevas prácticas se adscriben a los principios FAIR y concuerdan con el espíritu de distribución y acceso universal que originalmente concibió internet.
Phil Archer, una de las diecinueve personas que redactó las recomendaciones, describe el propósito del documento de la siguiente manera:
““Quiero una revolución. No una revolución política, ni ciertamente una revolución violenta, pero una revolución a fin de cuentas. Una revolución de la manera en la que las personas piensan sobre compartir datos en la red”.
El eje contextual

CC by SA Marcos Ge
Para implementar relevancia hace falta una revolución que sí es de índole política: el reconocimiento de necesidades prioritarias en la publicación de conjuntos de datos, con respecto a necesidades de todos los grupos poblacionales, pero con especial atención a datos sobre garantías individuales que son sistemáticamente violentadas por gobiernos y otros actores sociales en distintas latitudes globales.
Por ejemplo, en el contexto mexicano, la Corte Interamericana de Derechos Humanos (CIDH) detalla en uno de sus informes más recientes no sólo algunas de las violaciones sistemáticas de Derechos Humanos: desaparición, desaparición forzada, tortura, ejecuciones extrajudiciales, injusticia; sino también las poblaciones más vulneradas por estas violaciones: mujeres, pueblos indígenas, niñas, niños, adolescentes, defensoras de derechos humanos, personas migrantes, personas lesbianas, gay, bisexuales, trans y otras formas de disentimiento sexual.
En países en que se viven estas condiciones, es indispensable que este contexto de Derechos Humanos sea considerado como un factor determinante para la elaboración de políticas de apertura de datos relevantes. Aparejada a estas políticas, sólo la instrumentación de reglamentaciones y mecanismos concretos de análisis de la demanda de datos puede proveer a estas poblaciones de elementos para su defensa, que convengan efectivamente en la mejora de sus vidas.
Un paso más para asegurar la relevancia de los datos abiertos es la creación de mecanismos específicos que garanticen que poblaciones política y económicamente excluidas tengan acceso a un volumen y calidad de datos suficientes que les permita trabajar para erradicar las prácticas mismas que han promovido su exclusión.
Es decir, debe existir una concordancia entre las políticas de apertura de datos y la agenda pública propuesta por un gobierno abierto para el empoderamiento de la población, agenda que ya de por sí debe incluir a las poblaciones mencionadas.
Para la elaboración de estándares de todo tipo sobre políticas de relevancia de datos deben ser llamadas a participar no solamente especialistas en defensa de derechos, legislaciones nacionales e internacionales y otras disciplinas, sino principalmente representantes de estas poblaciones vulneradas y despojadas de la vida o de factores que permitan una vida digna.
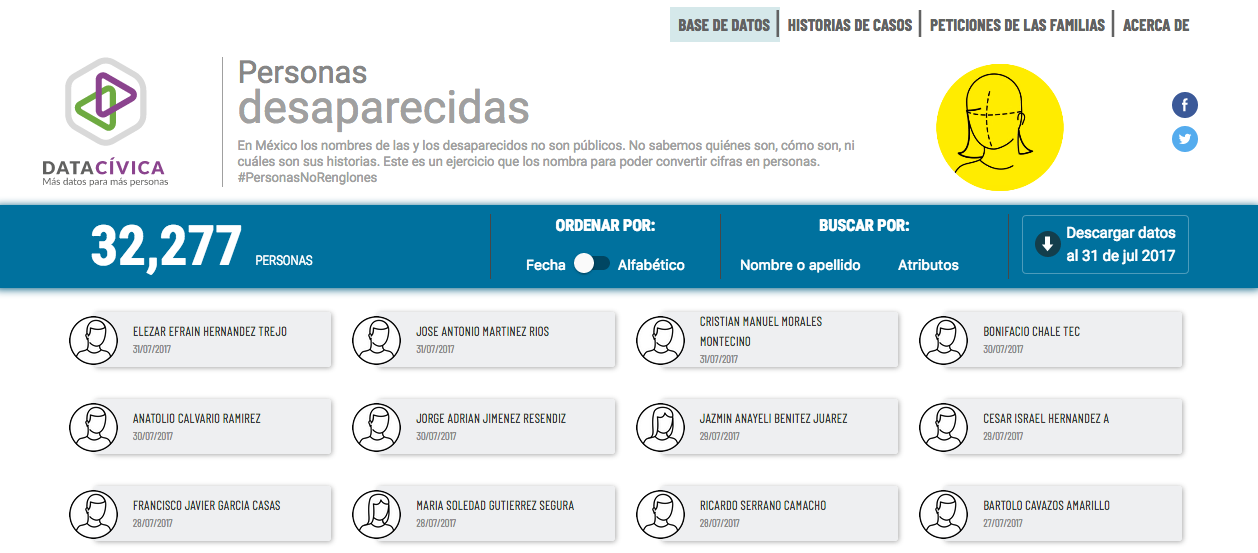
Hoy en día, la generación y publicación de datos con esta perspectiva se está llevando a cabo por organizaciones activistas. En México, por ejemplo, periodistas e investigadores independientes hicieron pública una base de datos sobre personas desaparecidas, y en Bolivia son activistas quienes construyen una base de datos sobre feminicidios; en España periodistas organizaron datos sobre la brecha de clase en el acceso a medicamentos; en Estados Unidos, un profesor universitario creó una base de variables relevantes para la comunidad LGBTTI; y desde el Reino Unido, el medio The Guardian creó una plataforma que muestra el número de personas de raza negra que mueren por causa de disparos de policías.
El eje de evaluación
Derivado del emparejamiento de los nuevos estándares técnicos propuestos por la W3C con las prioridades humanitarias globales, las poblaciones tendrían herramientas para exigir no sólo la calidad de los datos en los términos tradicionales de formatos de apertura, sino también en cuanto a su relevancia.
Por ejemplo, la encuesta global Open Data Survey, de la que proviene el Open Data Index de la organización Open Knowledge International, contiene algunas preguntas sobre la accesibilidad legal y técnica de los conjuntos de datos como una medida de su calidad. El Open Data Barometer, por otra parte, tiene un apartado de impacto social de la apertura de datos. Este año destaca, entre otras cosas, que el impacto en transparencia y rendición de cuentas disminuyó un 22%, mientras que el impacto en emprendimientos se incrementó 15%, lo cual ilustra que ciertos grupos sociales se están beneficiando de la apertura más que otros.
El aprovechamiento de la información es clave para que los conjuntos de datos puedan ser relevantes, no hay relevancia sin aprovechamiento y no hay aprovechamiento sin acceso a la información. En el caso ilustrado por el Open Data Barometer, los conjuntos de datos son relevantes solamente para emprendedores, lo cual implica que no necesariamente son relevantes para cualquier otro grupo poblacional.
No obstante, se necesitan más detalles para la evaluación de la relevancia de los datos a nivel nacional y local. En 2015, el investigador Juan Ortiz Freuler publicó el Estado de la Oferta y la Demanda de Datos Abiertos Gubernamentales tras la implementación de normativas de la defenestrada Alianza por el Gobierno Abierto en México, (de la cual las organizaciones de ese país decidieron salir, precisamente, debido a la evidencia de espionaje en contra de defensores de la salud y otros activistas con software de uso exclusivo gubernamental).
El informe de Freuler mostró, entre otros análisis, que la mayoría de las solicitudes de información (emparentadas con la demanda de datos abiertos) fueron realizadas por personas con grado académico de licenciatura, lo cual implica una profunda brecha de acceso a ellos respecto de poblaciones no profesionalizadas.
En su Uso y Cumplimiento de la Legislación de Acceso a la Información Pública en Brasil, Chile y México , los investigadores Silvana Fumega y Marcos Mendiburu ofrecen también algunos ejemplos de las ventajas de obtener datos sobre la demanda de información pública.
Por ejemplo, en la investigación de Fumega y Mendiburu se detalla que México incorpora dentro de la Ley General de Transparencia y Acceso a la Información Pública (LGTAIP) la obligación del organismo garante de recopilar datos sobre las solicitudes de información pública.
Con esta obligación, tanto el Estado como actores independientes pueden llegar a la conclusión de que en 2013 los institutos de seguridad social nacionales en México y Brasil y el ministerio de salud en Chile fueron las instancias públicas que más solicitudes de información recibieron. A partir de esa información es posible tomar medidas para jerarquizar la información de dicha instancia de salud pública.
Simultáneamente, los datos estadísticos sobre las personas que hacen las solicitudes, como su edad, género o escolaridad, abonan a la necesidad de delinear con datos también las políticas públicas de datos abiertos.
Así, la estandarización técnica de ciertas prácticas permitiría obtener y cruzar datos sobre el uso y propósito de los mismos; la priorización contextual permitirá garantizar que poblaciones excluidas y en riesgo puedan beneficiarse tanto como el resto de los grupos sociales; y la evaluación permitirá monitorear el resultado de las prácticas mencionadas.
En la publicación de las recomendaciones a las que antes aludí, sobre publicación de datos en internet, la W3C proponía generar a través de ellas una revolución exclusivamente tecnológica. No obstante, su articulación con estas otras formulaciones podría provocar una muy necesaria revolución que sí pertenece al orden de lo político: el empoderamiento de las comunidades a través del uso de conjuntos de datos.